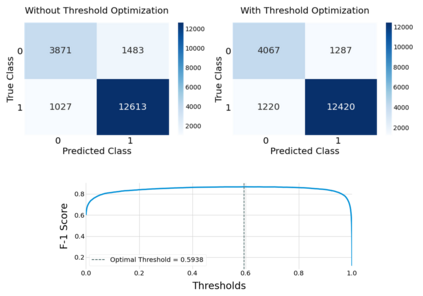
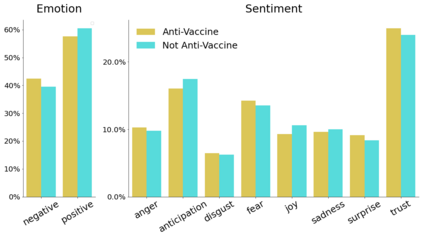
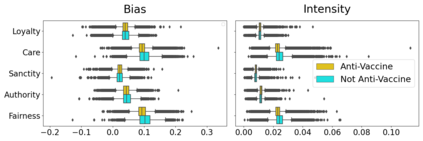
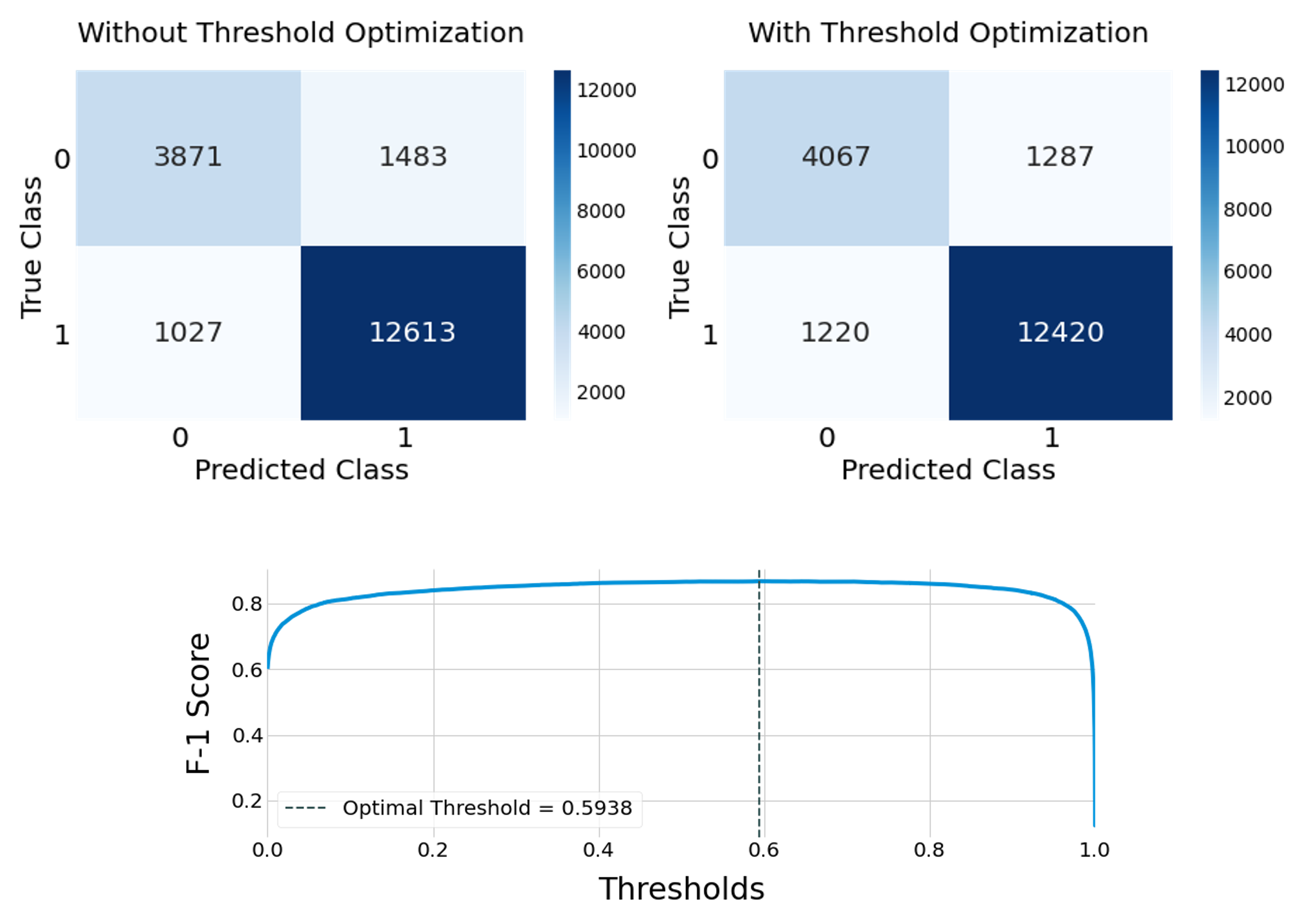
Vaccine hesitancy has a long history but has been recently driven by the anti-vaccine narratives shared online, which significantly degrades the efficacy of vaccination strategies, such as those for COVID-19. Despite broad agreement in the medical community about the safety and efficacy of available vaccines, a large number of social media users continue to be inundated with false information about vaccines and, partly because of this, became indecisive or unwilling to be vaccinated. The goal of this study is to better understand anti-vaccine sentiment, and work to reduce its impact, by developing a system capable of automatically identifying the users responsible for spreading anti-vaccine narratives. We introduce a publicly available Python package capable of analyzing Twitter profiles to assess how likely that profile is to spread anti-vaccine sentiment in the future. The software package is built using text embedding methods, neural networks, and automated dataset generation. It is trained on over one hundred thousand accounts and several million tweets. This model will help researchers and policy-makers understand anti-vaccine discussion and misinformation strategies, which can further help tailor targeted campaigns seeking to inform and debunk the harmful anti-vaccination myths currently being spread. Additionally, we leverage the data on such users to understand what are the moral and emotional characteristics of anti-vaccine spreaders.
翻译:尽管医疗界对可用疫苗的安全和功效达成广泛共识,但大量社交媒体用户仍然在疫苗的虚假信息中充斥着有关疫苗的虚假信息,部分由于这一原因,他们变得犹豫不决或不愿接种疫苗。本研究的目标是更好地了解抗疫苗情绪,并努力减少其影响,为此开发一个系统,能够自动识别负责传播抗疫苗说明的用户。我们推出一个公开的Python软件包,能够分析推特的概况,以评估这种特征在未来传播抗疫苗情绪的可能性。软件包是使用嵌入文本的方法、神经网络和自动的道德数据集生成而建造的。该软件包在超过10万个账户和几百万个推特上进行了培训。该模型将帮助研究人员和决策者了解反疫苗讨论和错误信息战略,从而进一步帮助调整有针对性的运动,以传播和删除我们目前这种有害的反疫苗特征。