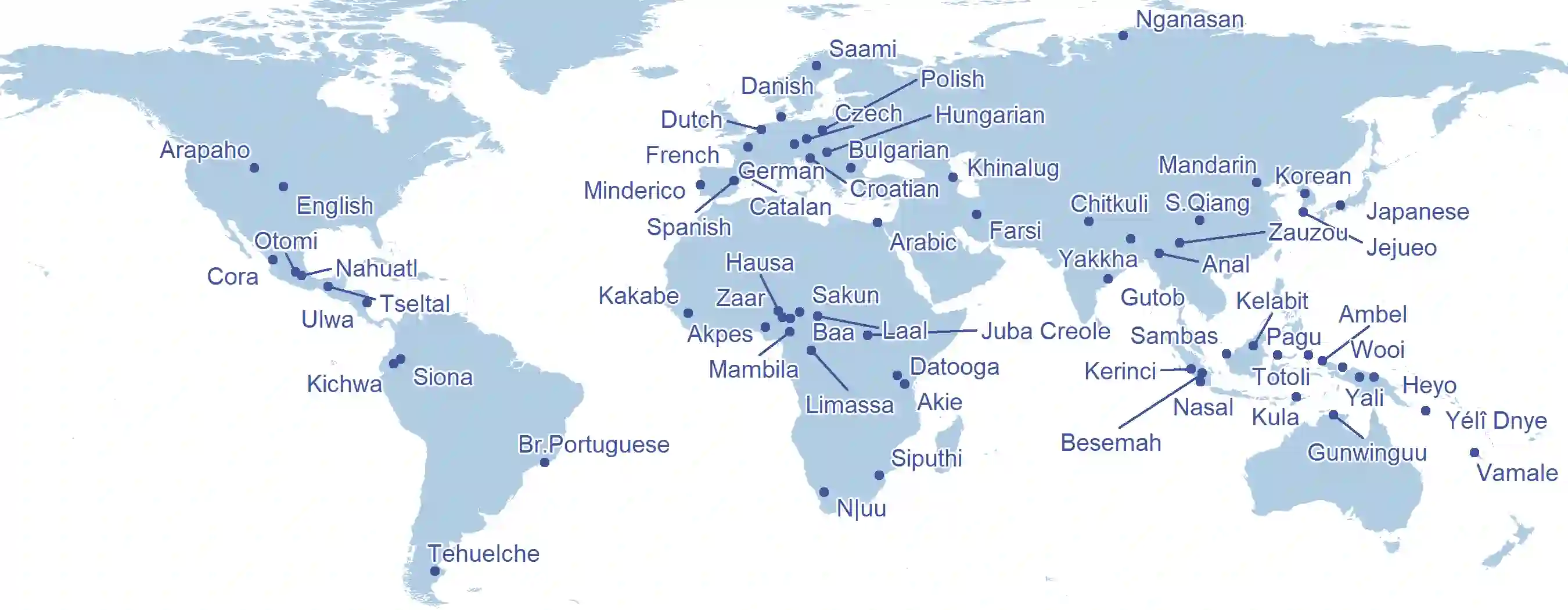
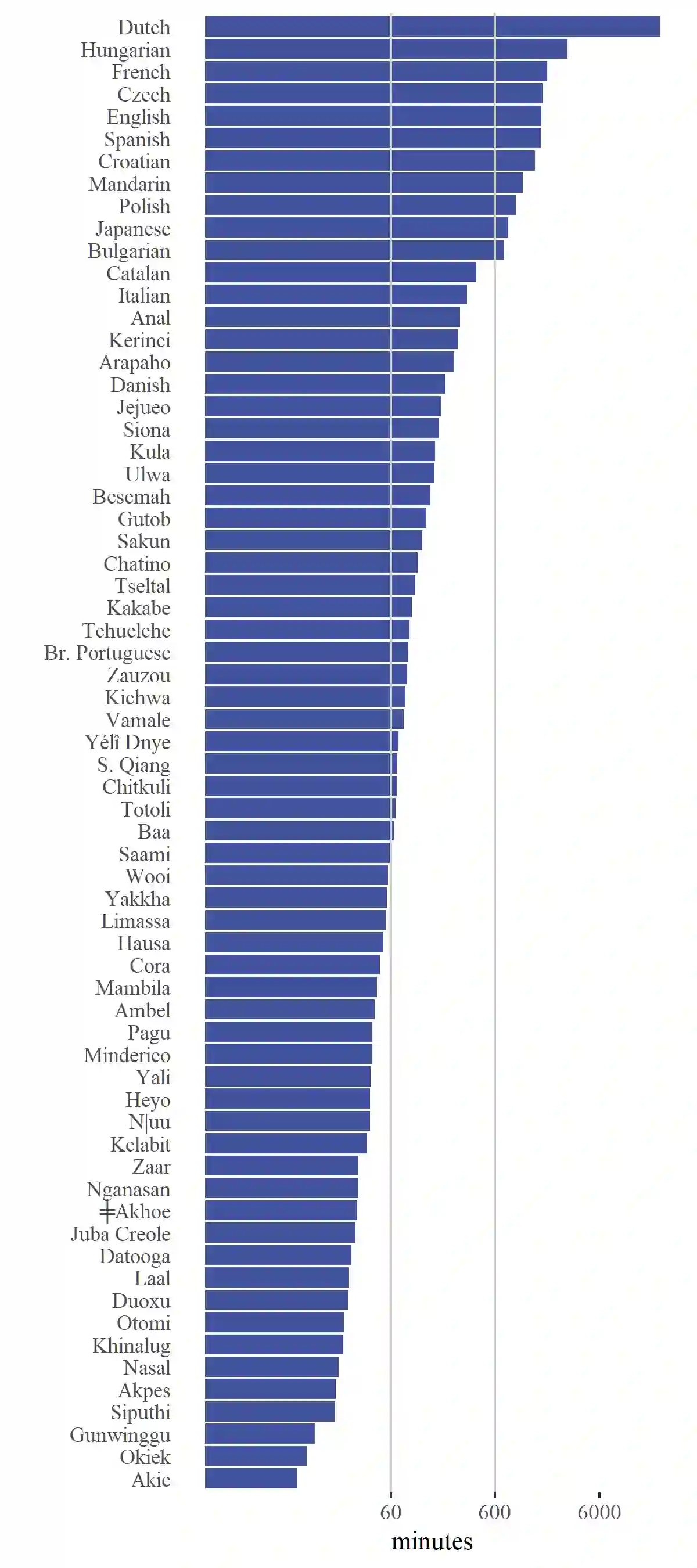
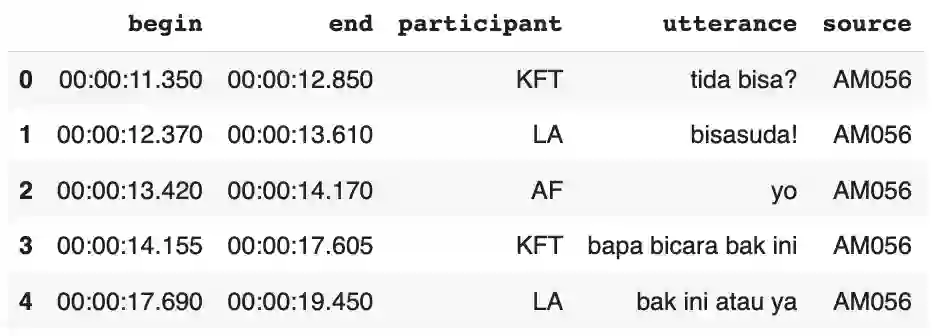
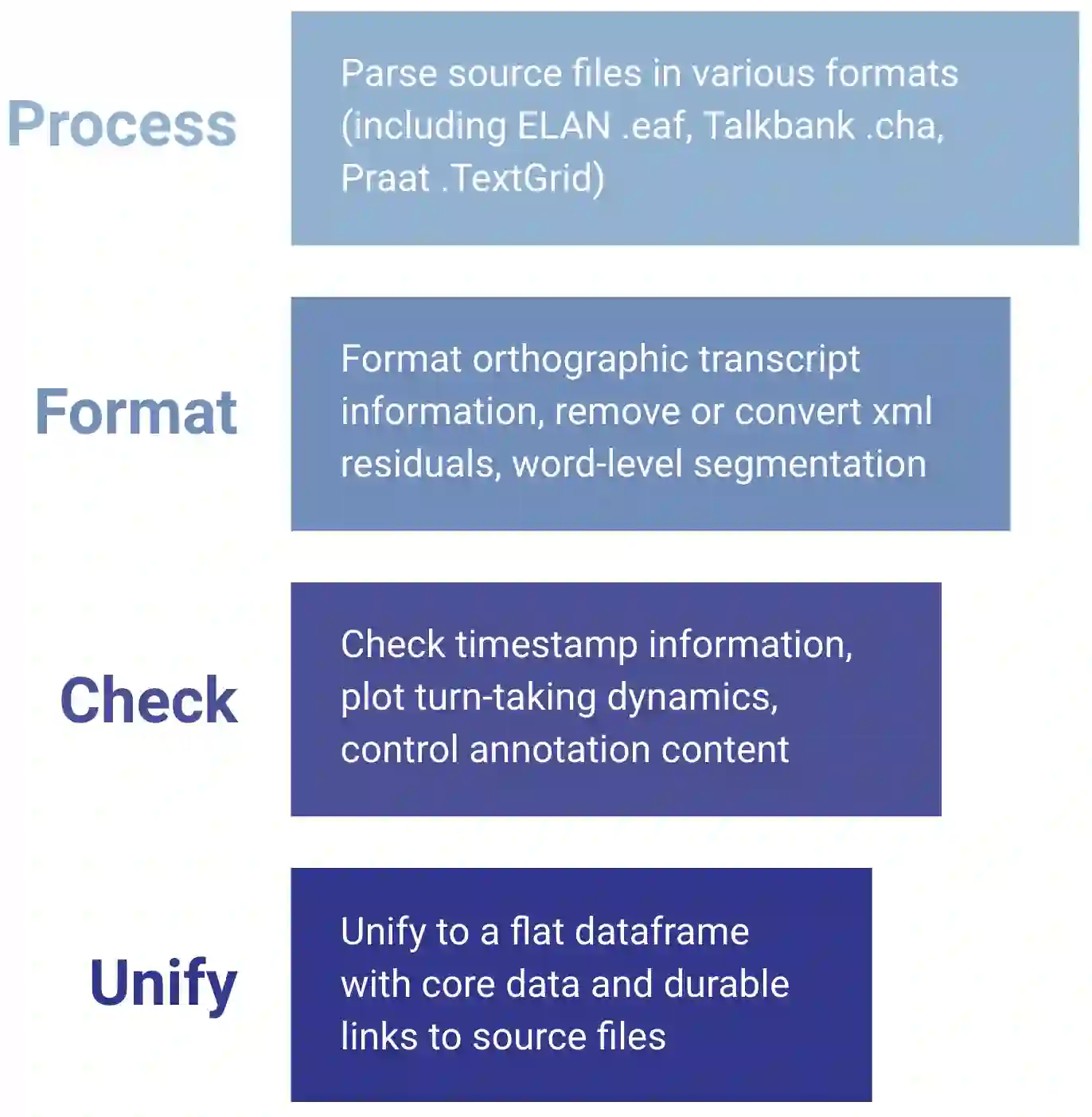
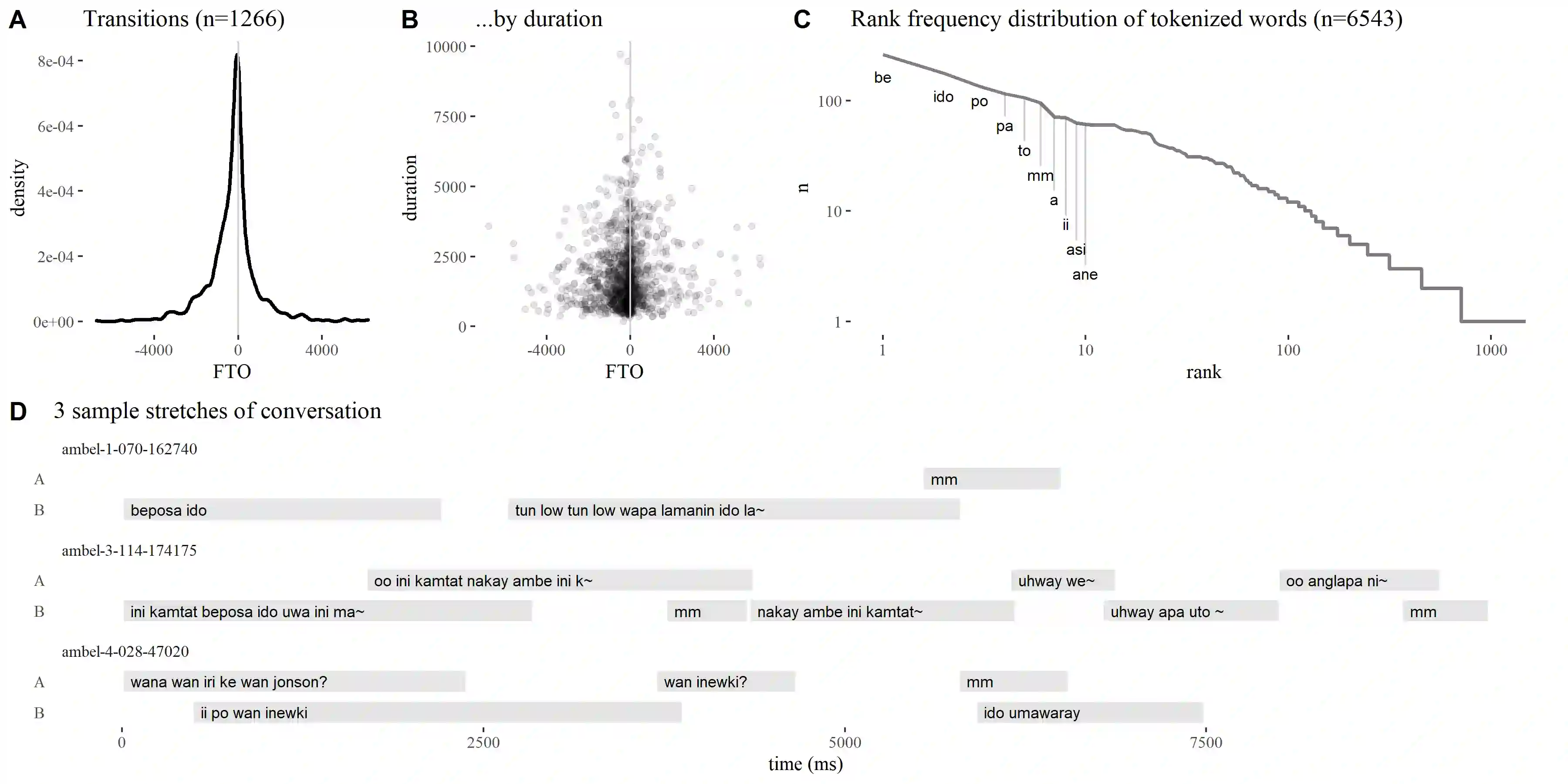
We present an analysis pipeline and best practice guidelines for building and curating corpora of everyday conversation in diverse languages. Surveying language documentation corpora and other resources that cover 67 languages and varieties from 28 phyla, we describe the compilation and curation process, specify minimal properties of a unified format for interactional data, and develop methods for quality control that take into account turn-taking and timing. Two case studies show the broad utility of conversational data for (i) charting human interactional infrastructure and (ii) tracing challenges and opportunities for current ASR solutions. Linguistically diverse conversational corpora can provide new insights for the language sciences and stronger empirical foundations for language technology.
翻译:我们提出以多种语言建立和整理日常对话社团的分析编审流程和最佳做法准则,调查语言文献社团和其他资源,涵盖来自28个phyla的67种语言和品种,我们描述汇编和整理过程,具体说明互动数据统一格式的最小特性,并制订考虑到考量和时机的质量控制方法,两个案例研究表明,对话数据在(一) 绘制人类互动基础设施图和(二) 追踪当前ASR解决方案的挑战和机遇方面具有广泛效用。语言多样性谈话社团可以为语言科学提供新的洞察力,并为语言技术提供更强有力的经验基础。