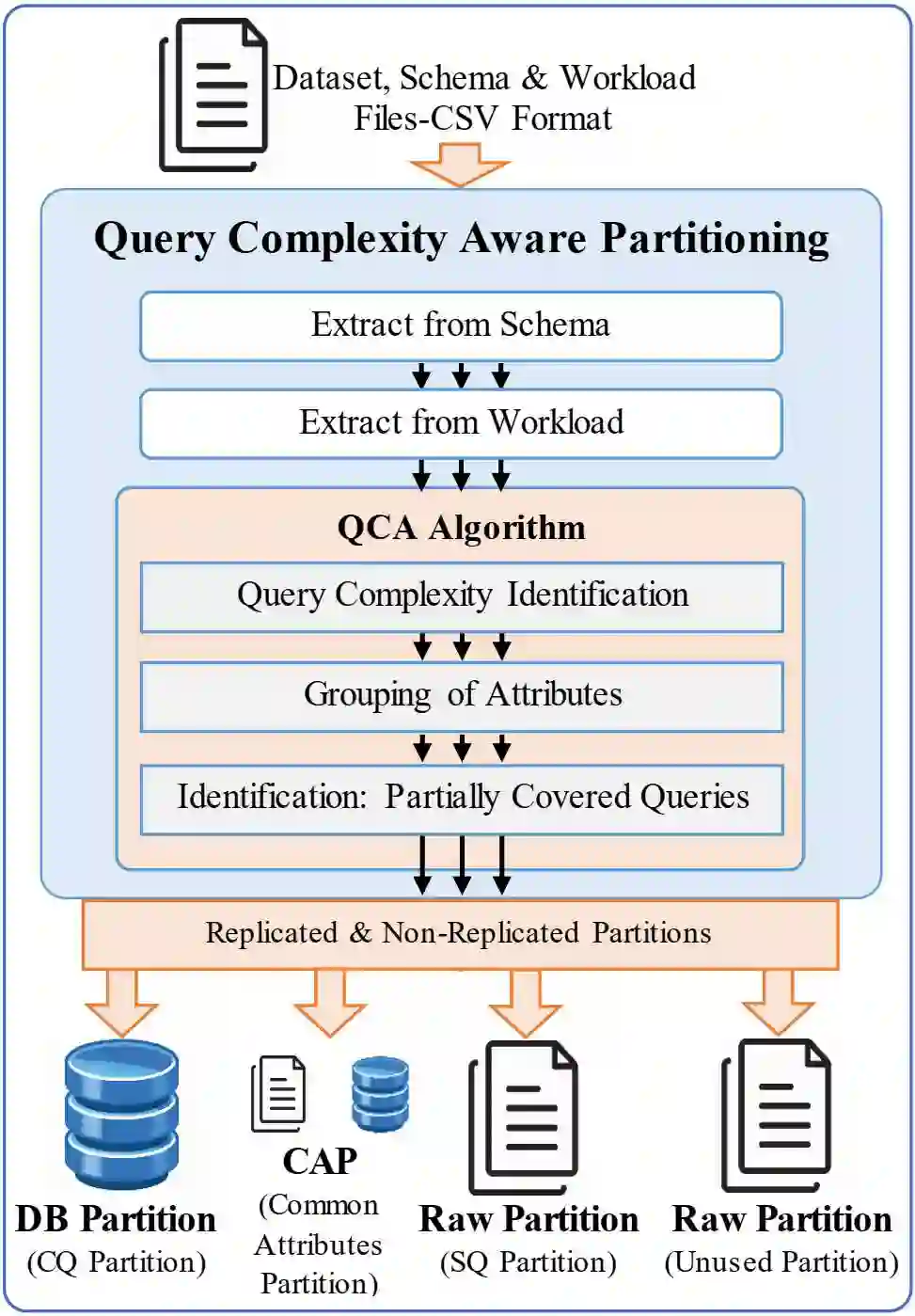
The paper aims to find an efficient way for processing large datasets having different types of workload queries with minimal replication. The work first identifies the complexity of queries best suited for the given data processing tool . The paper proposes Query Complexity Aware partitioning technique QCA with a lightweight query identification and partitioning algorithm. Different replication approaches have been studied to cover more use-cases for different application workloads. The technique is demonstrated using a scientific dataset known as Sloan Digital Sky Survey SDSS. The results show workload execution time WET reduced by 94.6% using only 6.7% of the dataset in loaded format compared to the original dataset. The QCA technique also reduced multi-node replication by 5.8x times compared to state-of-the-art workload aware WA techniques. The multi-node and multi-core execution of workload using QCA proposed partitions reduced WET by 42.66% and 25.46% compared to WA.
翻译:本文旨在找到一种高效的方法,处理具有不同类型工作量查询的大型数据集,并尽量少复制。工作首先确定最适合特定数据处理工具的查询的复杂性。文件提议了查询复杂度知识分解技术QCA,采用轻量级查询识别和分区算法。研究了不同的复制方法,以涵盖不同应用工作量的更多使用案例。该技术使用称为Sloan数字天空调查SDSS的科学数据集进行演示。结果显示,与原始数据集相比,WET执行工作量的时间减少了94.6%,仅使用已加载格式的数据集的6.7%。QCA技术也减少了5.8x倍的多点复制,而与最先进的了解WA工作量的技术相比,这种多节点和多核心的工作量使用QCA拟议的分区使WET减少了42.66%,与WA相比减少了25.46%。