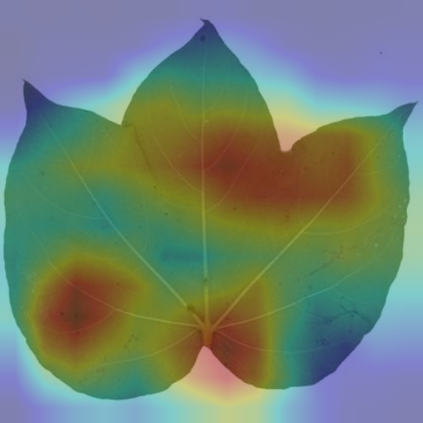
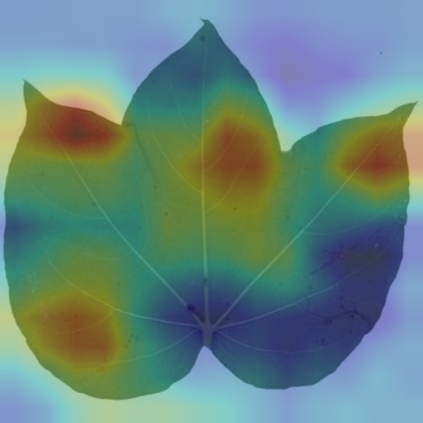
Fine-grained visual categorization (FGVC), which aims at classifying objects with small inter-class variances, has been significantly advanced in recent years. However, ultra-fine-grained visual categorization (ultra-FGVC), which targets at identifying subclasses with extremely similar patterns, has not received much attention. In ultra-FGVC datasets, the samples per category are always scarce as the granularity moves down, which will lead to overfitting problems. Moreover, the difference among different categories is too subtle to distinguish even for professional experts. Motivated by these issues, this paper proposes a novel compositional feature embedding and similarity metric (CECS). Specifically, in the compositional feature embedding module, we randomly select patches in the original input image, and these patches are then replaced by patches from the images of different categories or masked out. Then the replaced and masked images are used to augment the original input images, which can provide more diverse samples and thus largely alleviate overfitting problem resulted from limited training samples. Besides, learning with diverse samples forces the model to learn not only the most discriminative features but also other informative features in remaining regions, enhancing the generalization and robustness of the model. In the compositional similarity metric module, a new similarity metric is developed to improve the classification performance by narrowing the intra-category distance and enlarging the inter-category distance. Experimental results on two ultra-FGVC datasets and one FGVC dataset with recent benchmark methods consistently demonstrate that the proposed CECS method achieves the state of-the-art performance.
翻译:精细的视觉分类(FGVC)旨在对不同对象进行小类间差异的分类,近年来取得了显著的进展;然而,超细的视觉分类(Ulttra-FGVC)旨在识别模式极为相似的子类,但并未引起多少注意;在超微粒类内,每类的样本总是稀缺,因为颗粒会降低,导致问题过多;此外,不同类别之间的差异太小,甚至无法区分专业专家。受这些问题的驱动,本文件提出了一个新的组成特征嵌入和相似度测量(CECS)。具体地说,在组成特征嵌入模块中,我们随机选择原始输入模式中的补丁,这些补丁随后被与不同类别或遮掩图像的补补所取代。随后,替换和遮掩图像被用来增加原始输入图像,这可以提供更多样化的样本,从而大大缓解过度匹配的问题,因为有限的培训样本。此外,与多样化的样本相比,构建一个模型的构成比重性的缩缩缩缩缩缩缩缩缩缩缩缩缩缩缩缩缩缩度数据,也通过相同的缩缩缩缩缩微缩缩缩缩缩缩缩缩缩缩缩缩缩缩缩缩的C。