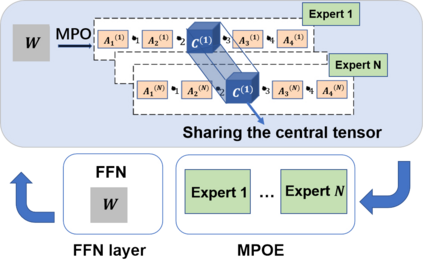
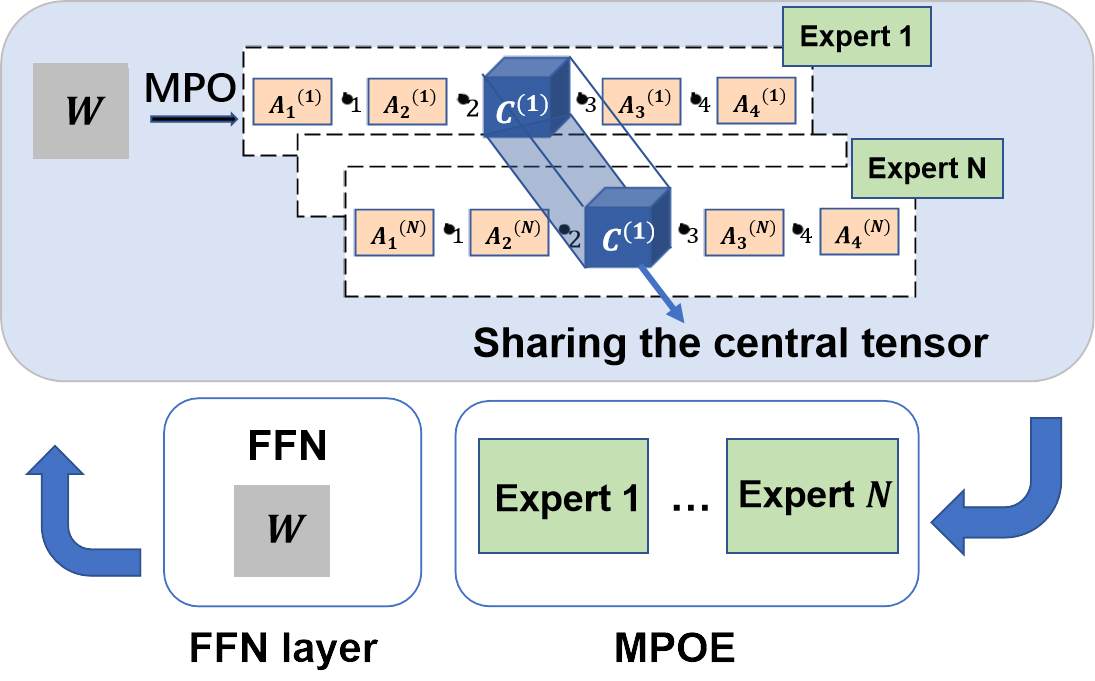
Recently, Mixture-of-Experts (short as MoE) architecture has achieved remarkable success in increasing the model capacity of large-scale language models. However, MoE requires incorporating significantly more parameters than the base model being extended. In this paper, we propose building a parameter-efficient MoE architecture by sharing information across experts. We adopt the matrix product operator (MPO, a tensor decomposition from quantum many-body physics) to reconstruct the parameter matrix in the expert layer and increase model capacity for pre-trained language models by sharing parameters of the central tensor (containing the core information) among different experts while enabling the specificity through the auxiliary tensors (complementing the central tensor) of different experts. To address the unbalanced optimization issue, we further design the gradient mask strategy for the MPO-based MoE architecture. Extensive experiments based on T5 and GPT-2 show improved performance and efficiency of the pre-trained language model (27.2x reduction in total parameters for the superior model performance, compared with the Switch Transformers). Our code is publicly available at \url{https://github.com/RUCAIBox/MPO/MPOE}.
翻译:最近,Mixture-Expertive-Informations(短期作为教育部)架构在提高大规模语言模型模型的模型能力方面取得了显著的成功,然而,教育部需要纳入比正在扩展的基础模型要多得多的参数。在本文件中,我们建议通过专家共享信息建立一个具有参数效率的MOE架构。我们采用了矩阵产品操作员(MPO,从量子多体物理学中分解出来)来重建专家层的参数矩阵,并通过在不同专家之间分享中央发号(包含核心信息)参数(包含核心信息)的模型能力来提高预先培训语言模型的模型能力,同时通过辅助发号器(补充中央发号)使不同专家具有特殊性。为了解决不平衡的优化问题,我们进一步设计以MOPO为基础的移动结构的梯度遮掩战略。基于T5和GPT-2的广泛实验显示,与开关变换型器相比,经过培训的语言模型的性能和效率有所提高(27.2x减少高级模型性能总参数)。我们的代码在以下可公开查阅:https://github.com/RUCATOM}/POMMM}。