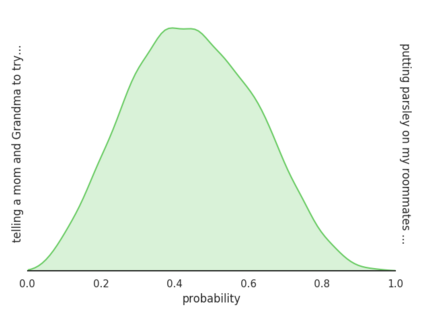
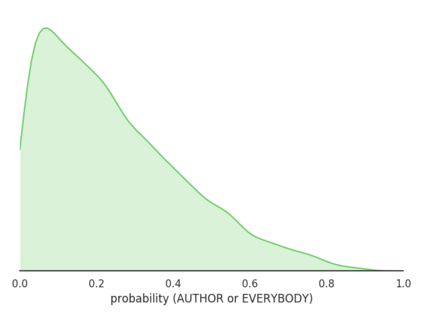
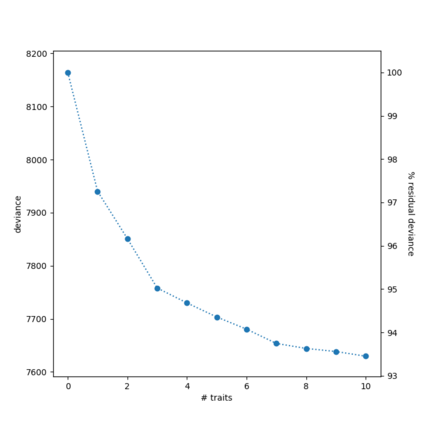
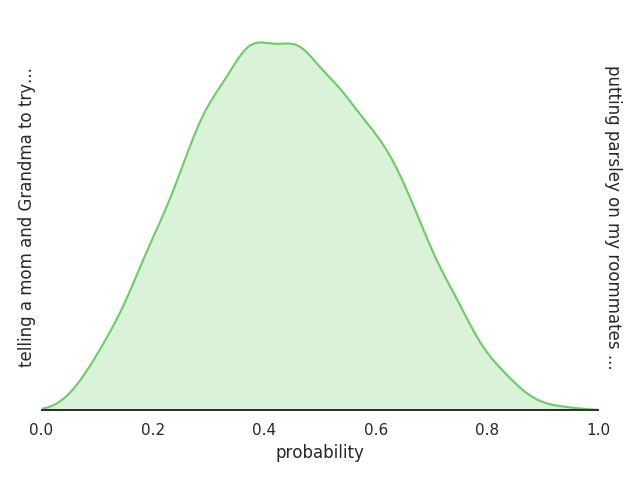
As AI systems become an increasing part of people's everyday lives, it becomes ever more important that they understand people's ethical norms. Motivated by descriptive ethics, a field of study that focuses on people's descriptive judgments rather than theoretical prescriptions on morality, we investigate a novel, data-driven approach to machine ethics. We introduce Scruples, the first large-scale dataset with 625,000 ethical judgments over 32,000 real-life anecdotes. Each anecdote recounts a complex ethical situation, often posing moral dilemmas, paired with a distribution of judgments contributed by the community members. Our dataset presents a major challenge to state-of-the-art neural language models, leaving significant room for improvement. However, when presented with simplified moral situations, the results are considerably more promising, suggesting that neural models can effectively learn simpler ethical building blocks. A key take-away of our empirical analysis is that norms are not always clean-cut; many situations are naturally divisive. We present a new method to estimate the best possible performance on such tasks with inherently diverse label distributions, and explore likelihood functions that separate intrinsic from model uncertainty.
翻译:随着AI系统日益成为人们日常生活的一部分,人们越来越需要理解人们的道德规范。受描述性伦理学的激励,我们研究的领域侧重于人们的描述性判断,而不是道德理论的理论处方,我们调查机器伦理学的新颖的、数据驱动的方法。我们引入了Scrubles,这是第一个大型的数据集,其625,000项伦理学判断超过32 000个实际动因。每个厌食者都讲述了复杂的伦理状况,往往造成道德困境,并配之以社区成员提供的判断。我们的数据集对最新神经语言模型提出了重大挑战,留下了很大的改进空间。然而,当提出简化的道德状况时,结果则大有希望,表明神经模型可以有效地学习更简单的道德建筑块。我们经验分析的关键是,规范并非总是干净的;许多情况自然是分裂的。我们提出了一个新的方法,用来估计在这种任务上可能的最佳表现,具有内在多样性的标签分布,并探索与模型不确定性分化的可能性。