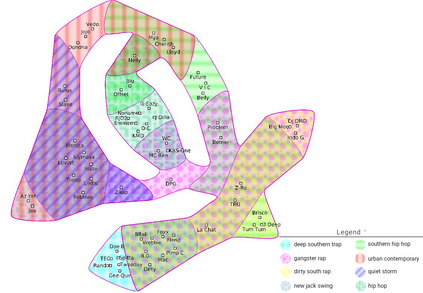
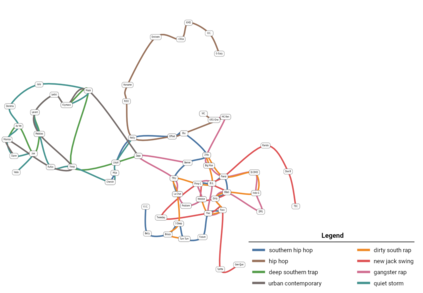
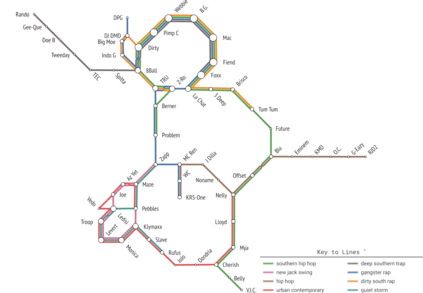
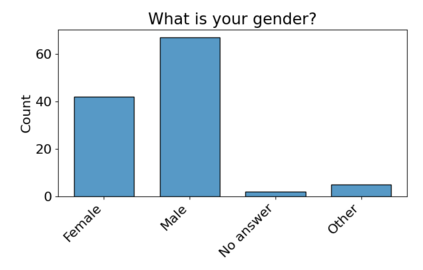
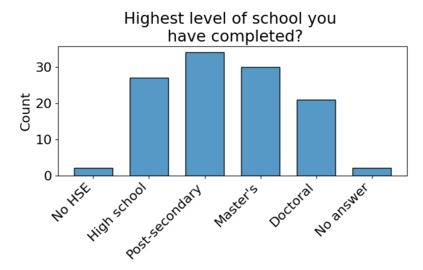
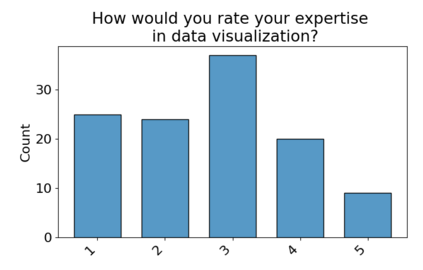
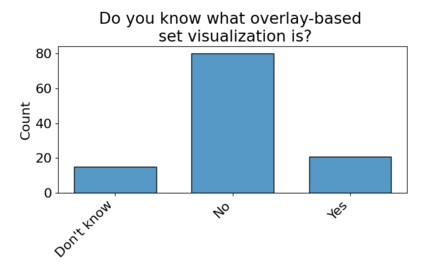
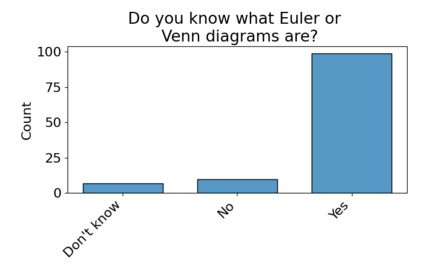
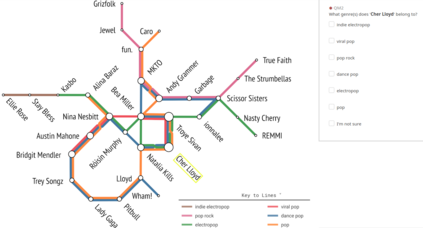
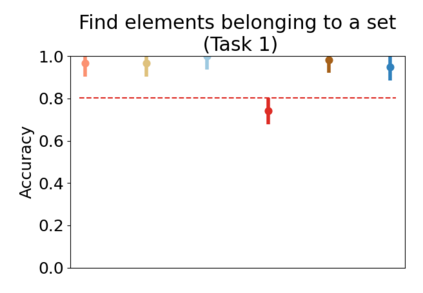
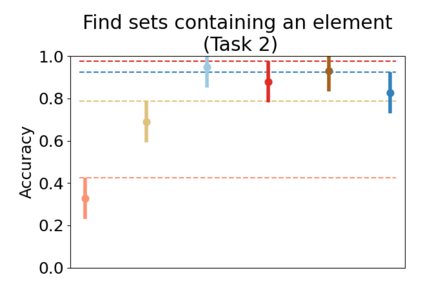
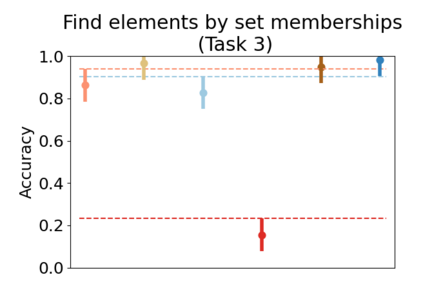
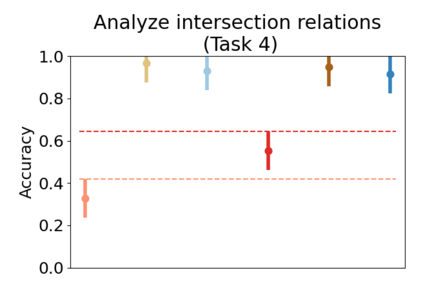
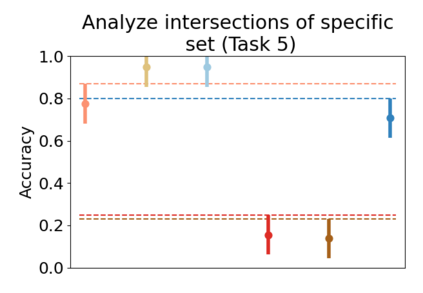
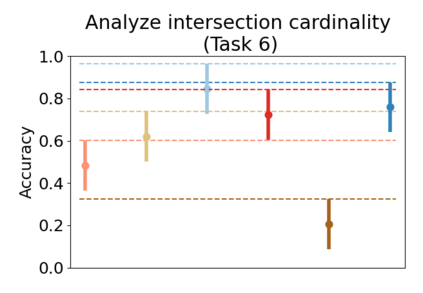
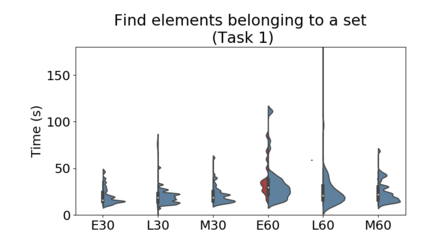
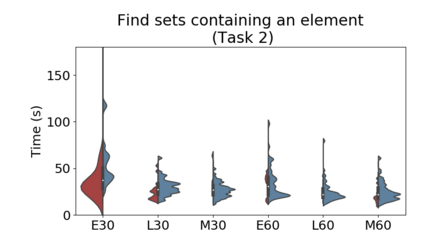
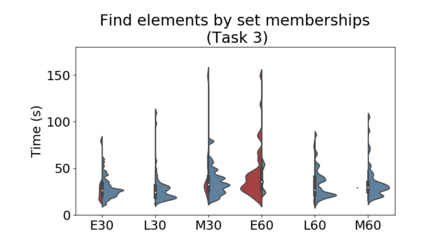
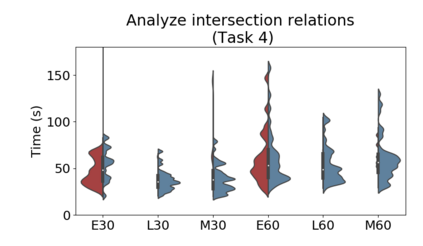
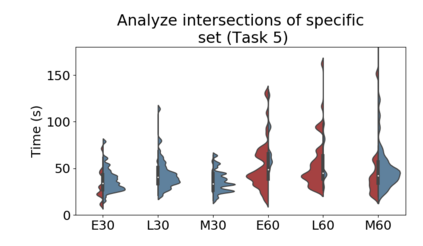
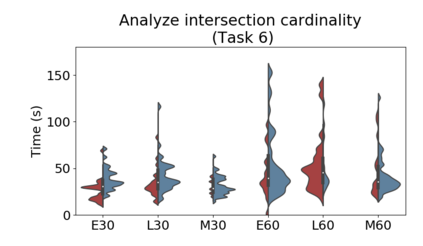
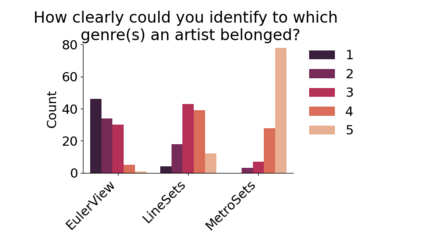
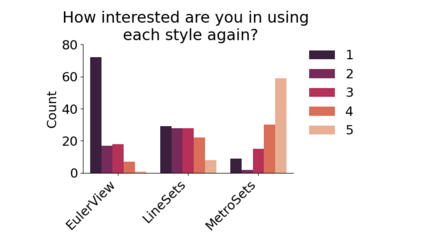
Set systems are used to model data that naturally arises in many contexts: social networks have communities, musicians have genres, and patients have symptoms. Visualizations that accurately reflect the information in the underlying set system make it possible to identify the set elements, the sets themselves, and the relationships between the sets. In static contexts, such as print media or infographics, it is necessary to capture this information without the help of interactions. With this in mind, we consider three different systems for medium-sized set data, LineSets, EulerView, and MetroSets, and report the results of a controlled human-subjects experiment comparing their effectiveness. Specifically, we evaluate the performance, in terms of time and error, on tasks that cover the spectrum of static set-based tasks. We also collect and analyze qualitative data about the three different visualization systems. Our results include statistically significant differences, suggesting that MetroSets performs and scales better.
翻译:设置系统用于模拟在很多情况下自然产生的数据: 社交网络有社区, 音乐家有基因, 病人有症状。 精确反映基本设置系统中的信息的可视化使得能够识别集成元素、 集集本身以及各组之间的关系。 在静态背景下, 如印刷媒体或成像, 必须在没有互动帮助的情况下捕捉这些信息。 考虑到这一点, 我们考虑三个不同的中等规模数据系统, 即 LineSets、 EulerView 和 MetroSet, 并报告受控的人类实验结果, 比较其效果。 具体地说, 我们从时间和错误的角度评估涵盖静态设定任务范围的任务的性能。 我们还收集和分析关于三种不同可视化系统的定性数据。 我们的结果包括统计上的重大差异, 表明MetelSet 更好地表现和规模。