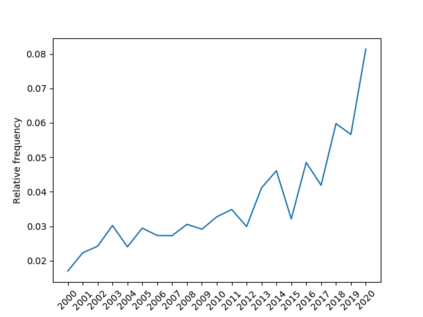
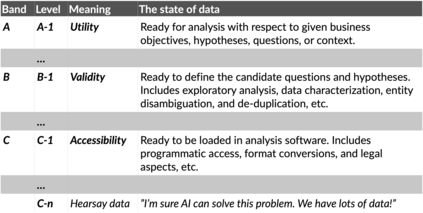
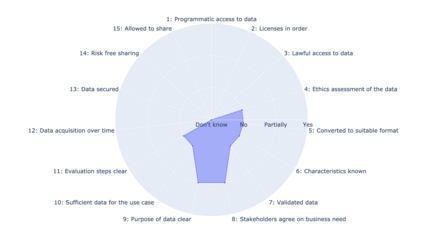
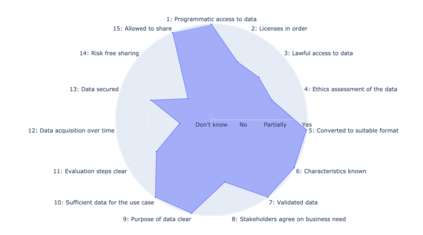
In this paper, we identify the state of data as being an important reason for failure in applied Natural Language Processing (NLP) projects. We argue that there is a gap between academic research in NLP and its application to problems outside academia, and that this gap is rooted in poor mutual understanding between academic researchers and their non-academic peers who seek to apply research results to their operations. To foster transfer of research results from academia to non-academic settings, and the corresponding influx of requirements back to academia, we propose a method for improving the communication between researchers and external stakeholders regarding the accessibility, validity, and utility of data based on Data Readiness Levels \cite{lawrence2017data}. While still in its infancy, the method has been iterated on and applied in multiple innovation and research projects carried out with stakeholders in both the private and public sectors. Finally, we invite researchers and practitioners to share their experiences, and thus contributing to a body of work aimed at raising awareness of the importance of data readiness for NLP.
翻译:本文指出,数据状况是应用自然语言处理(NLP)项目失败的重要原因之一,我们认为,在NLP的学术研究及其在学术界以外问题的应用之间存在差距,这一差距的根源在于学术研究人员与试图将研究成果应用于其业务的非学术同行之间缺乏相互了解。为了促进将学术界的研究成果转移到非学术环境中,以及相应的要求向学术界的流入,我们提出了一个方法,用于改进研究人员与外部利益攸关方之间关于基于数据准备水平(cite{lawrence2017data)的数据的可获取性、有效性和效用的沟通。虽然该方法尚处于初始阶段,但在与私营和公共部门的利益攸关方一起开展的多个创新和研究项目中反复使用和适用。最后,我们请研究人员和从业人员交流经验,从而帮助开展旨在提高人们对数据准备对于NLP重要性的认识的工作。