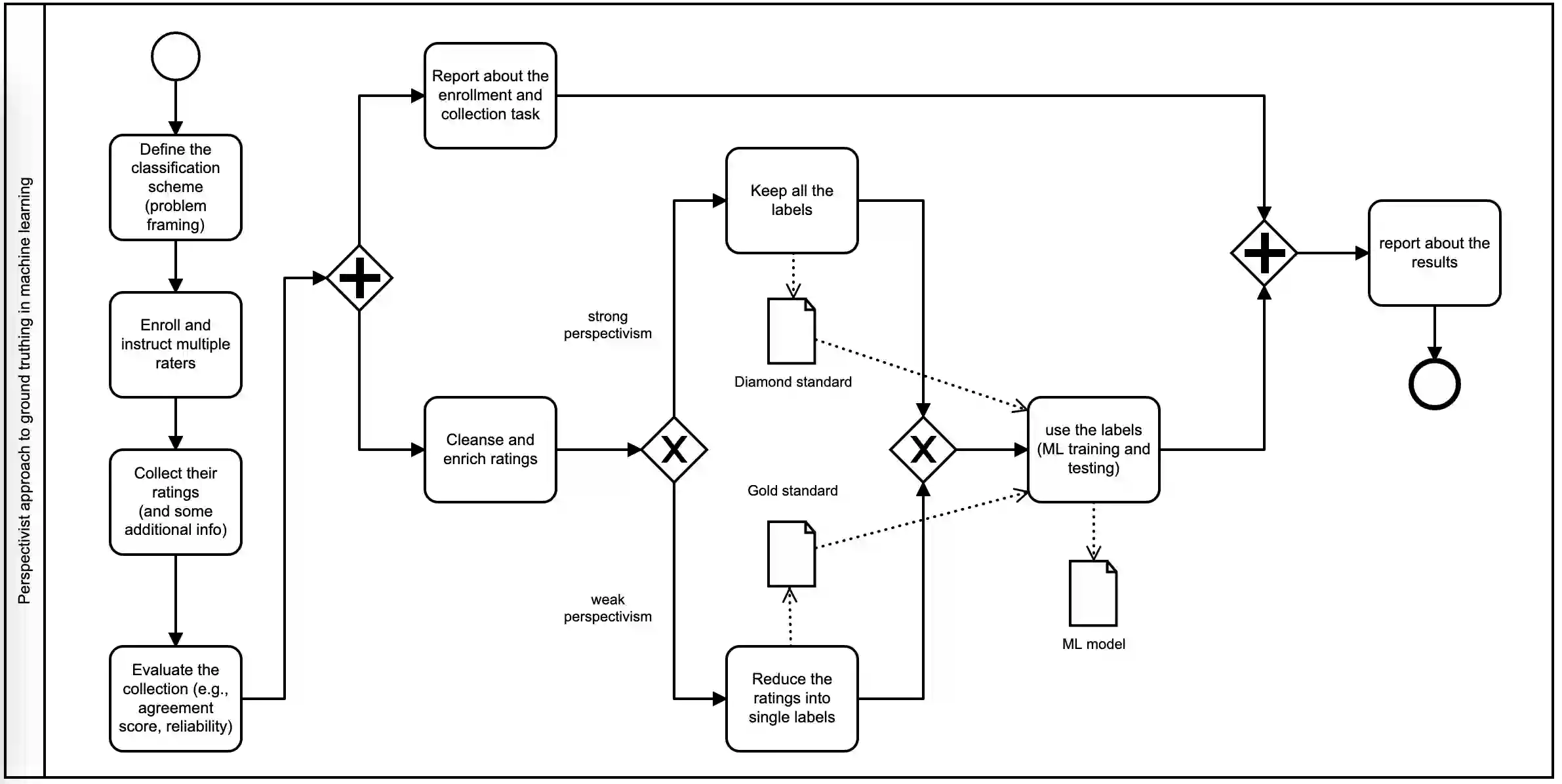
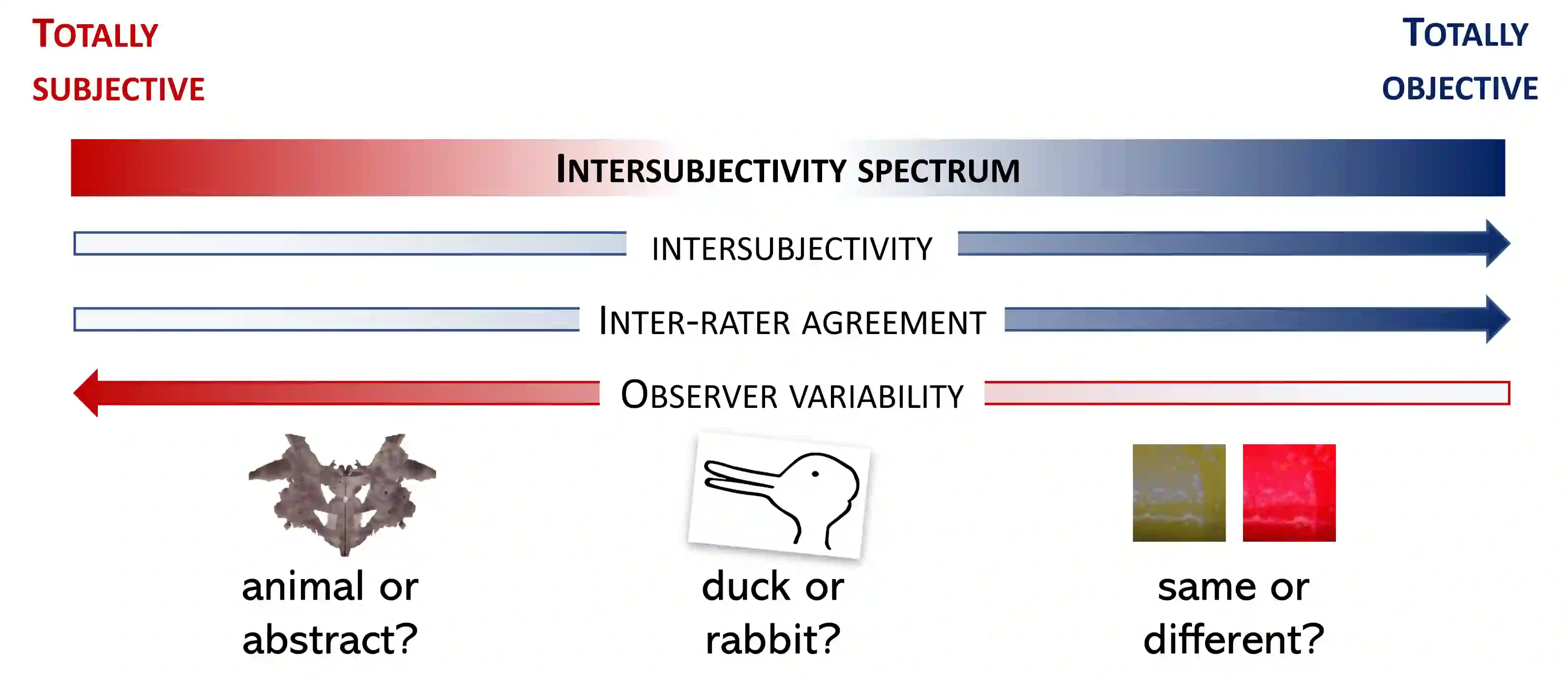
Most Artificial Intelligence applications are based on supervised machine learning (ML), which ultimately grounds on manually annotated data. The annotation process is often performed in terms of a majority vote and this has been proved to be often problematic, as highlighted by recent studies on the evaluation of ML models. In this article we describe and advocate for a different paradigm, which we call data perspectivism, which moves away from traditional gold standard datasets, towards the adoption of methods that integrate the opinions and perspectives of the human subjects involved in the knowledge representation step of ML processes. Drawing on previous works which inspired our proposal we describe the potential of our proposal for not only the more subjective tasks (e.g. those related to human language) but also to tasks commonly understood as objective (e.g. medical decision making), and present the main advantages of adopting a perspectivist stance in ML, as well as possible disadvantages, and various ways in which such a stance can be implemented in practice. Finally, we share a set of recommendations and outline a research agenda to advance the perspectivist stance in ML.
翻译:多数人工智能应用都基于监督的机器学习(ML),这最终是以人工附加说明的数据为依据的。说明过程往往以多数投票方式进行,而且正如最近对ML模型的评估研究所强调的那样,这往往证明是有问题的。在本条中,我们描述并倡导一种不同的模式,我们称之为数据透视主义,从传统的黄金标准数据集转向采用将参与ML过程知识代表步骤的人类主体的观点和观点综合起来的方法。我们借鉴了以前启发我们提出建议的著作,我们描述了我们提案的潜力,不仅涉及更主观的任务(例如与人类语言有关的任务),而且涉及通常被视为客观的任务(例如医疗决策),并介绍了在ML采取透视主义立场的主要优势,以及可能存在的不利之处,以及在实践中可以落实这种立场的各种方法。我们分享了一套建议,并概述了一项研究议程,以推进ML的透视主义立场。