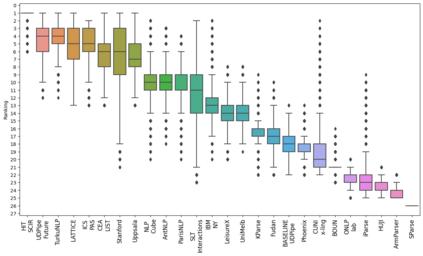
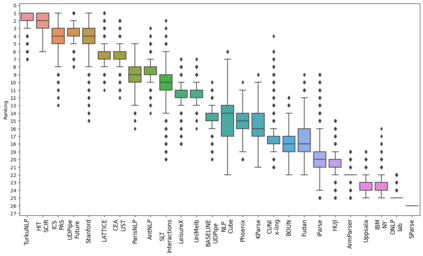
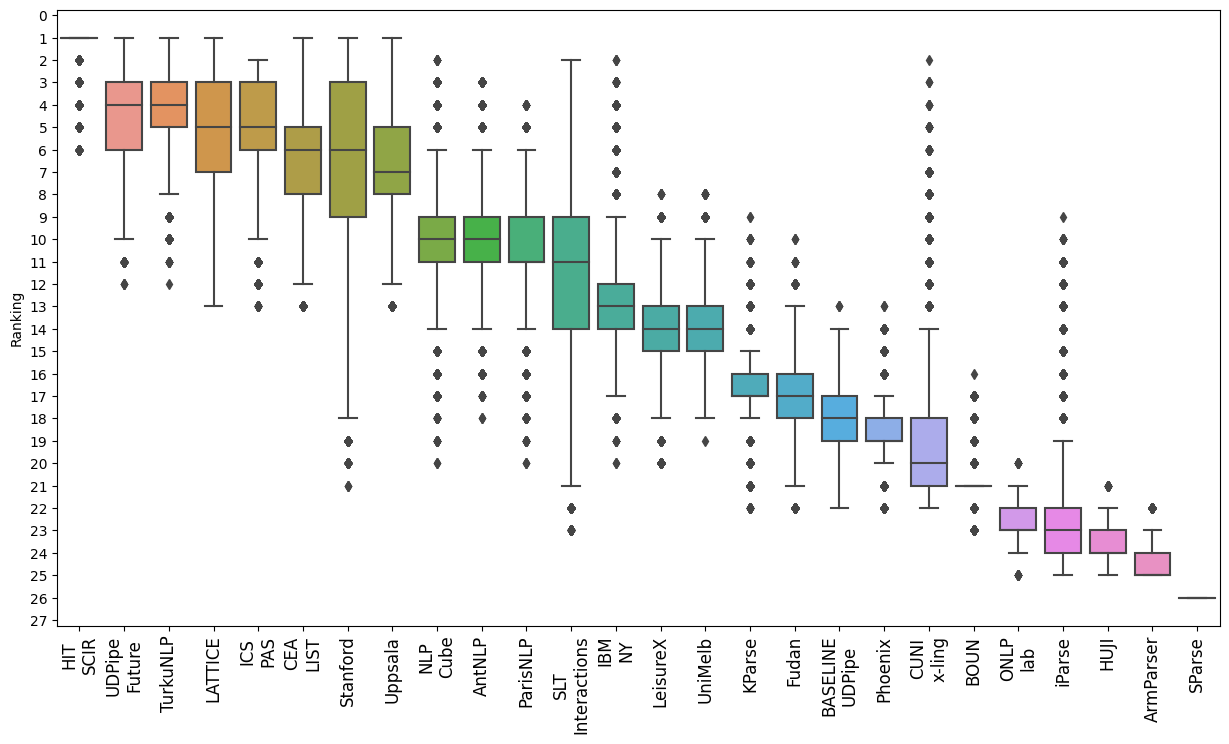
Treebank selection for parsing evaluation and the spurious effects that might arise from a biased choice have not been explored in detail. This paper studies how evaluating on a single subset of treebanks can lead to weak conclusions. First, we take a few contrasting parsers, and run them on subsets of treebanks proposed in previous work, whose use was justified (or not) on criteria such as typology or data scarcity. Second, we run a large-scale version of this experiment, create vast amounts of random subsets of treebanks, and compare on them many parsers whose scores are available. The results show substantial variability across subsets and that although establishing guidelines for good treebank selection is hard, it is possible to detect potentially harmful strategies.
翻译:用于分析评估的树库选择以及偏向选择可能产生的虚假影响尚未详细探讨。 本文研究的是,对单个树库子集的评估如何会导致薄弱的结论。 首先,我们采取一些对比式的采伐者,并在先前工作中提议的树库子集中运行这些分类,这些分类在类型学或数据稀缺等标准上使用是合理的(或不合理 ) 。 其次,我们进行了大规模实验,创造了大量随机的树库子集,并比较了许多有分数的采伐者。 研究结果显示,各子集之间差异很大,尽管为良好的树库选择制定准则是困难的,但有可能发现潜在的有害策略。