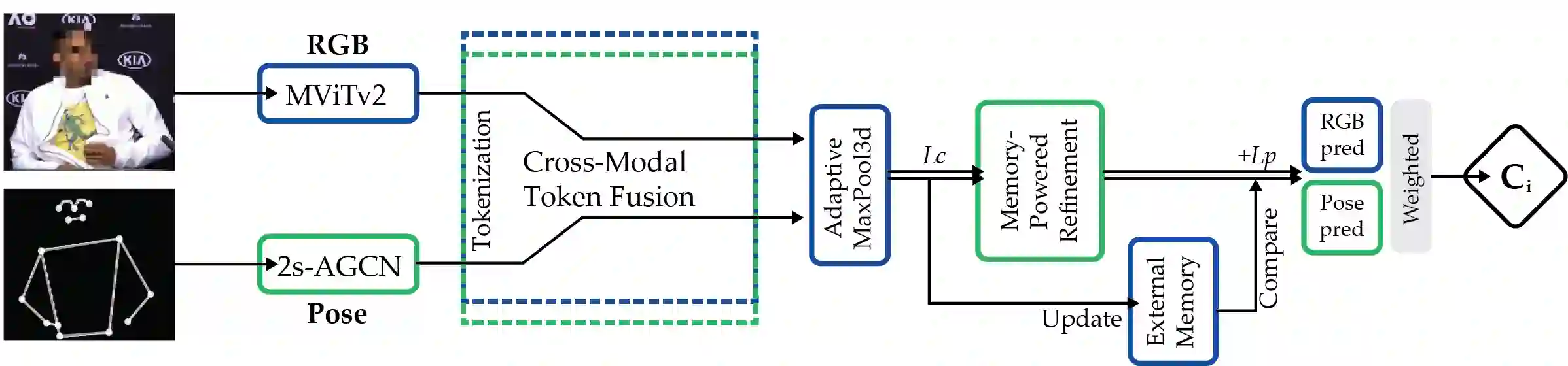
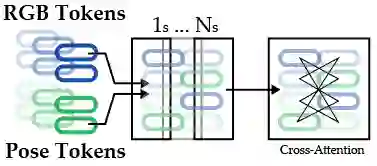
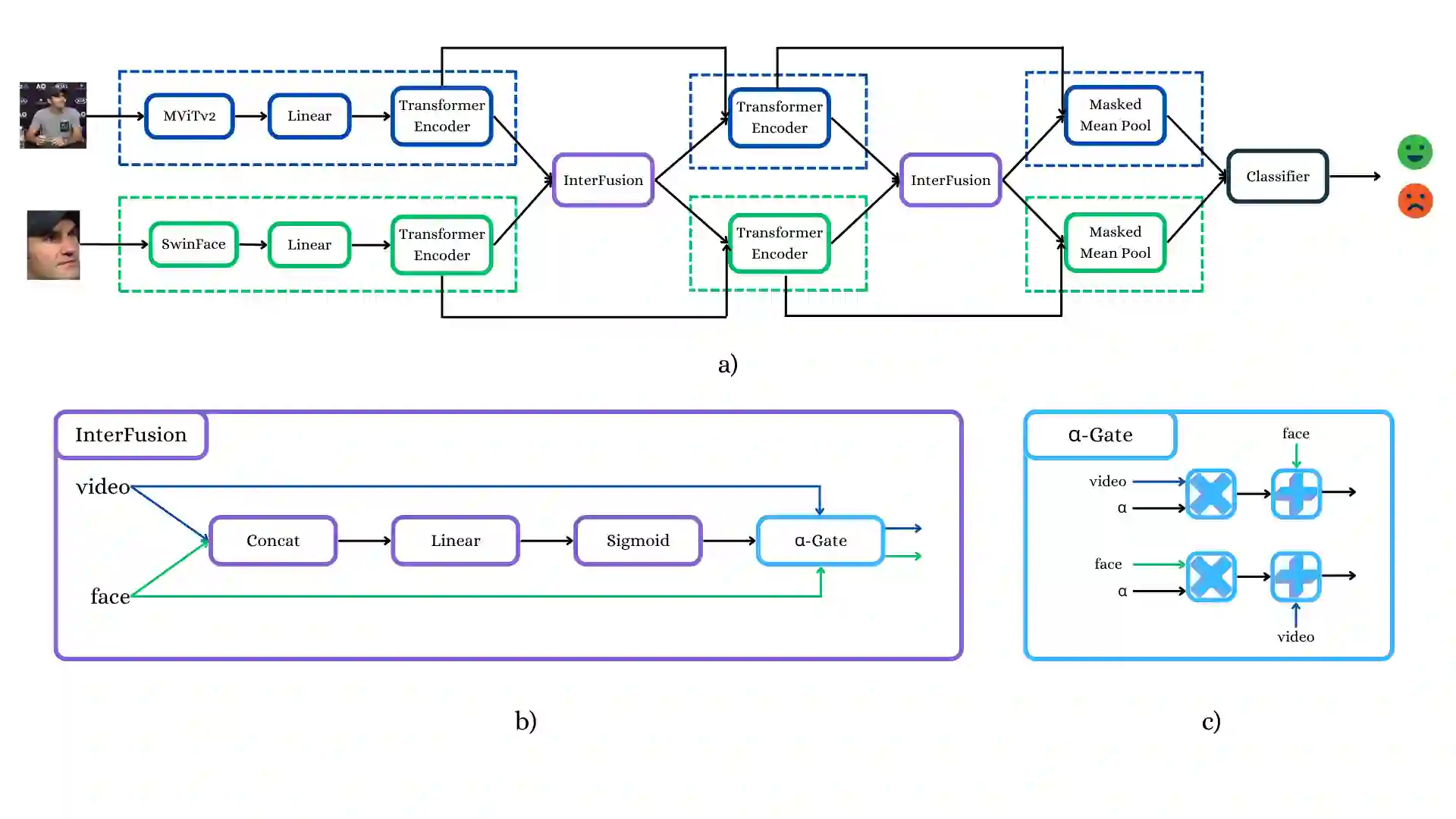
Micro-gesture recognition and behavior-based emotion prediction are both highly challenging tasks that require modeling subtle, fine-grained human behaviors, primarily leveraging video and skeletal pose data. In this work, we present two multimodal frameworks designed to tackle both problems on the iMiGUE dataset. For micro-gesture classification, we explore the complementary strengths of RGB and 3D pose-based representations to capture nuanced spatio-temporal patterns. To comprehensively represent gestures, video, and skeletal embeddings are extracted using MViTv2-S and 2s-AGCN, respectively. Then, they are integrated through a Cross-Modal Token Fusion module to combine spatial and pose information. For emotion recognition, our framework extends to behavior-based emotion prediction, a binary classification task identifying emotional states based on visual cues. We leverage facial and contextual embeddings extracted using SwinFace and MViTv2-S models and fuse them through an InterFusion module designed to capture emotional expressions and body gestures. Experiments conducted on the iMiGUE dataset, within the scope of the MiGA 2025 Challenge, demonstrate the robust performance and accuracy of our method in the behavior-based emotion prediction task, where our approach secured 2nd place.
翻译:微手势识别与基于行为的情感预测均是极具挑战性的任务,它们需要对细微、精细的人类行为进行建模,主要利用视频和骨骼姿态数据。在本工作中,我们提出了两种多模态框架,旨在解决iMiGUE数据集上的这两个问题。针对微手势分类,我们探索了RGB与基于3D姿态的表征之间的互补优势,以捕捉细微的时空模式。为了全面表征手势,分别使用MViTv2-S和2s-AGCN提取视频和骨骼嵌入。随后,通过跨模态令牌融合模块将它们集成,以结合空间与姿态信息。对于情感识别,我们的框架扩展到基于行为的情感预测,这是一个基于视觉线索识别情感状态的二分类任务。我们利用SwinFace和MViTv2-S模型提取的面部与上下文嵌入,并通过一个旨在捕捉情感表达与身体手势的InterFusion模块进行融合。在MiGA 2025挑战赛范围内,于iMiGUE数据集上进行的实验证明了我们的方法在基于行为的情感预测任务中具有鲁棒的性能与准确性,我们的方法在该任务中获得了第二名。