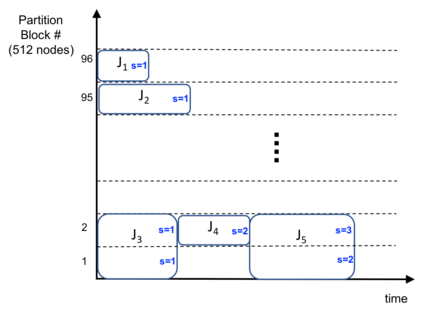
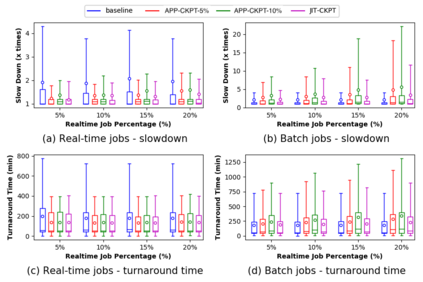
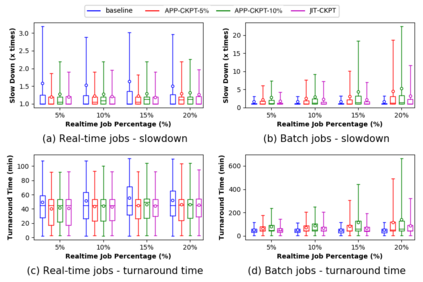
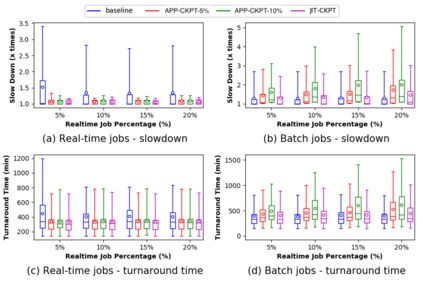
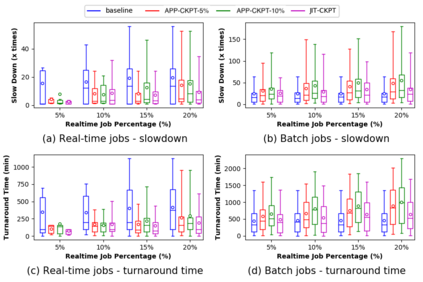
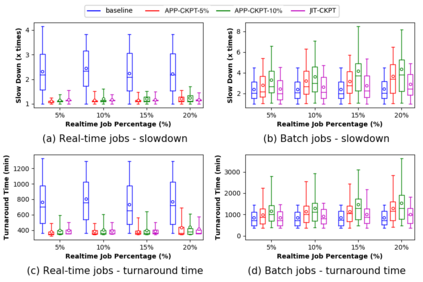
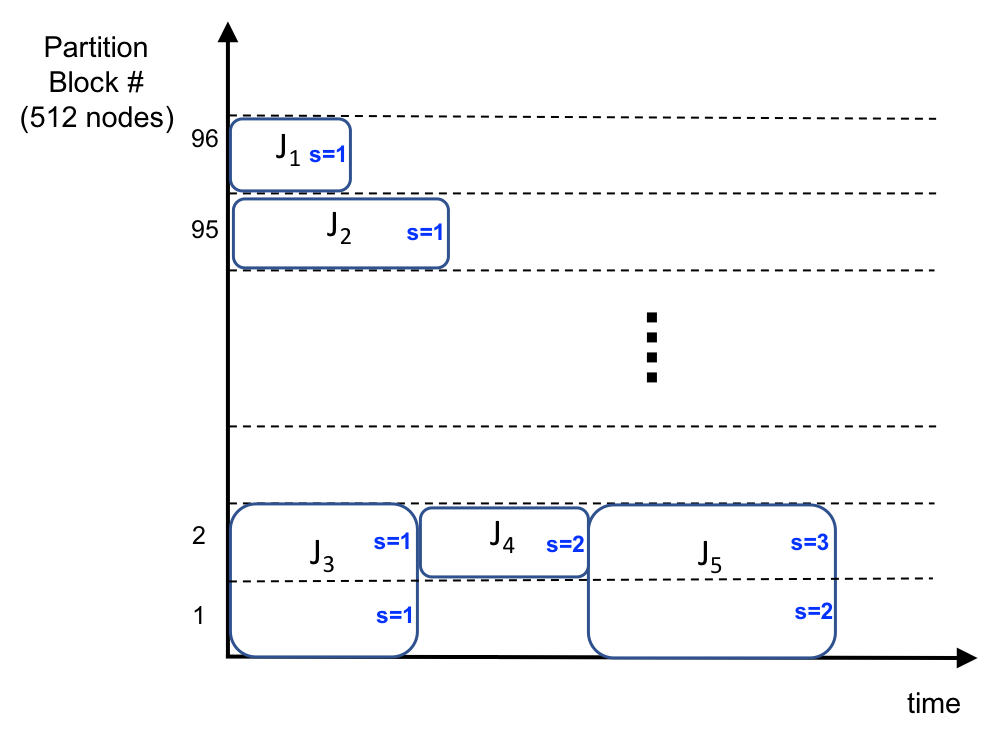
Increasing data volumes in scientific experiments necessitate the use of high-performance computing (HPC) resources for data analysis. In many scientific fields, the data generated from scientific instruments and supercomputer simulations must be analyzed rapidly. In fact, the requirement for quasi-instant feedback is growing. Scientists want to use results from one experiment to guide the selection of the next or even to improve the course of a single experiment. Current HPC systems are typically batch-scheduled under policies in which an arriving job is run immediately only if enough resources are available; otherwise, it is queued. It is hard for these systems to support real-time jobs. Real-time jobs, in order to meet their requirements, should sometimes have to preempt batch jobs and/or be scheduled ahead of batch jobs that were submitted earlier. Accommodating real-time jobs may negatively impact system utilization also, especially when preemption/restart of batch jobs is involved. We first explore several existing scheduling strategies to make real-time jobs more likely to be scheduled in due time. We then rigorously formulate the problem as a mixed-integer linear programming for offline scheduling and develop novel scheduling heuristics for online scheduling. We perform simulation studies using trace logs of Mira, the IBM BG/Q system at Argonne National Laboratory, to quantify the impact of real-time jobs on batch job performance for various percentages of real-time jobs in the workload. We present new insights gained from grouping jobs into different categories based on runtime and the number of nodes used and studying the performance of each category. Our results show that with 10% real-time job percentages, just-in-time checkpointing combined with our heuristic can improve the slowdowns of real-time jobs by 35% while limiting the increase of the slowdowns of batch jobs to 10%.
翻译:科学实验中不断增加的数据量要求使用高性能计算(HPC)资源进行数据分析。在许多科学领域,必须迅速分析科学仪器和超级计算机模拟生成的数据。事实上,对准即时反馈的需求正在增加。科学家希望利用一次实验的结果来指导下一个实验的选择,甚至改进一个实验的过程。目前的HPC系统通常是根据以下政策分批排列的:只有当有足够资源时,才能立即进行到来的工作;否则,它被排队。这些系统很难支持实时工作。为了满足其要求,实时工作有时必须提前完成批次工作和(或)提前完成批次工作。调整实时工作可能会对系统的利用产生消极影响,特别是在涉及预降/重新开始批次工作的情况下。我们首先探索一些现有的时间安排战略,以便更有可能通过适当时间来安排实时工作;我们随后严格地将问题编成一个混合的线性线性编程程序,以便完成离线性工作安排,满足其需要,有时必须提前完成批次的工作和(或)提前完成已经提交的批次工作。 调整实时工作可能会对系统的系统产生消极影响,同时进行实时工作表现,我们当前工作业绩的系统进行实时排序。