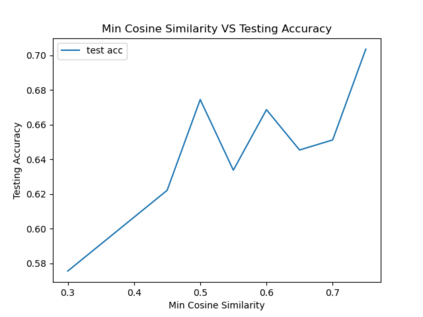
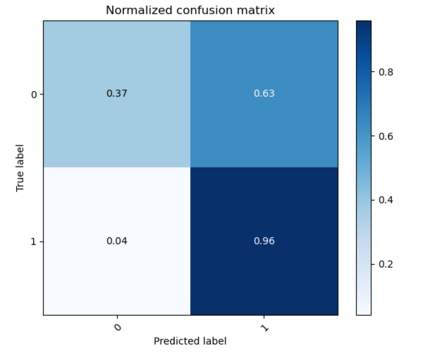
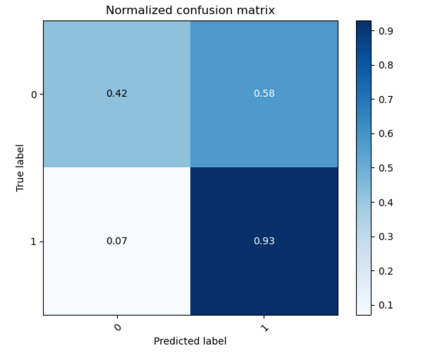
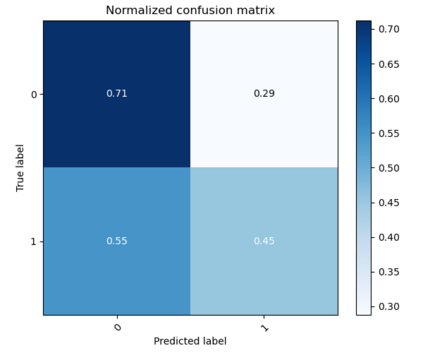
As the deployment of NLP systems in critical applications grows, ensuring the robustness of large language models (LLMs) against adversarial attacks becomes increasingly important. Large language models excel in various NLP tasks but remain vulnerable to low-cost adversarial attacks. Focusing on the domain of conversation entailment, where multi-turn dialogues serve as premises to verify hypotheses, we fine-tune a transformer model to accurately discern the truthfulness of these hypotheses. Adversaries manipulate hypotheses through synonym swapping, aiming to deceive the model into making incorrect predictions. To counteract these attacks, we implemented innovative fine-tuning techniques and introduced an embedding perturbation loss method to significantly bolster the model's robustness. Our findings not only emphasize the importance of defending against adversarial attacks in NLP but also highlight the real-world implications, suggesting that enhancing model robustness is critical for reliable NLP applications.
翻译:暂无翻译