
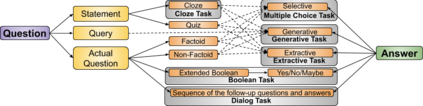
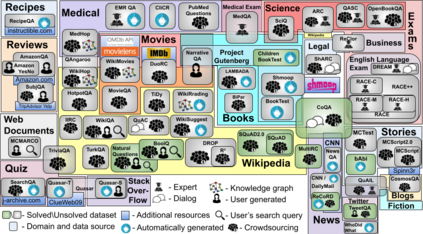
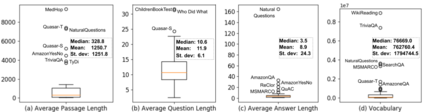
This paper surveys 60 English Machine Reading Comprehension datasets, with a view to providing a convenient resource for other researchers interested in this problem. We categorize the datasets according to their question and answer form and compare them across various dimensions including size, vocabulary, data source, method of creation, human performance level, and first question word. Our analysis reveals that Wikipedia is by far the most common data source and that there is a relative lack of why, when, and where questions across datasets.
翻译:本文调查了60个英文机器阅读理解数据集,目的是为关注这一问题的其他研究人员提供方便的资源。 我们根据数据集的问答形式进行分类,并在各层面进行比较,包括大小、词汇、数据来源、创建方法、人类性能水平和第一个问题词。 我们的分析显示维基百科是迄今为止最常见的数据源,相对缺乏为什么、何时、在哪里跨数据集的问题。



相关内容

专知会员服务
19+阅读 · 2020年4月25日
专知会员服务
20+阅读 · 2020年1月7日
专知会员服务
7+阅读 · 2019年12月19日
专知会员服务
41+阅读 · 2019年11月24日
专知会员服务
34+阅读 · 2019年10月18日
Arxiv
15+阅读 · 2020年5月13日
Arxiv
7+阅读 · 2018年5月25日
Arxiv
4+阅读 · 2017年11月15日



相关VIP内容
专知会员服务
19+阅读 · 2020年4月25日
专知会员服务
20+阅读 · 2020年1月7日
专知会员服务
7+阅读 · 2019年12月19日
专知会员服务
41+阅读 · 2019年11月24日
专知会员服务
34+阅读 · 2019年10月18日
相关资讯
相关论文
Arxiv
15+阅读 · 2020年5月13日
Arxiv
7+阅读 · 2018年5月25日
Arxiv
4+阅读 · 2017年11月15日