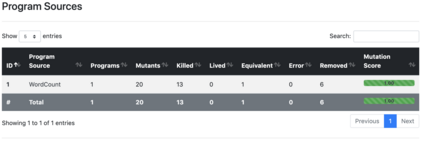
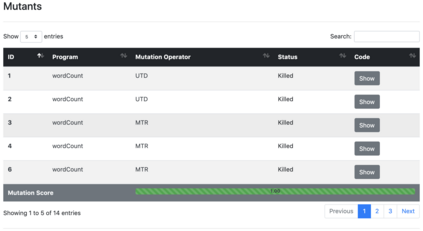
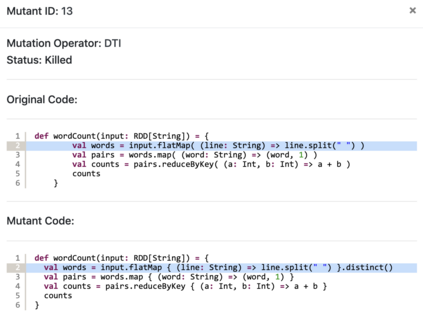
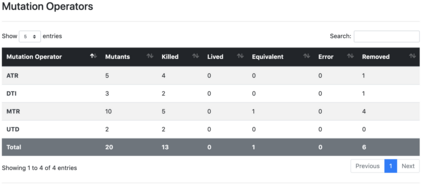
We propose TRANSMUT-Spark, a tool that automates the mutation testing process of Big Data processing code within Spark programs. Apache Spark is an engine for Big Data Processing. It hides the complexity inherent to Big Data parallel and distributed programming and processing through built-in functions, underlying parallel processes, and data management strategies. Nonetheless, programmers must cleverly combine these functions within programs and guide the engine to use the right data management strategies to exploit the large number of computational resources required by Big Data processing and avoid substantial production losses. Many programming details in data processing code within Spark programs are prone to false statements that need to be correctly and automatically tested. This paper explores the application of mutation testing in Spark programs, a fault-based testing technique that relies on fault simulation to evaluate and design test sets. The paper introduces the TRANSMUT-Spark solution for testing Spark programs. TRANSMUT-Spark automates the most laborious steps of the process and fully executes the mutation testing process. The paper describes how the tool automates the mutants generation, test execution, and adequacy analysis phases of mutation testing with TRANSMUT-Spark. It also discusses the results of experiments that were carried out to validate the tool to argue its scope and limitations.
翻译:我们提议了TRANSMUT-Spark, 这是一种将大数据处理码的突变测试过程自动化的工具。 Apache Spark 是大数据处理的引擎。 它隐藏了大数据平行和通过内在功能、基本平行程序和数据管理战略进行分布编程和处理所固有的复杂性。 然而, 程序设计者必须巧妙地将这些功能结合到程序内部, 并指导引擎使用正确的数据管理战略, 以利用大数据处理所需的大量计算资源, 并避免大量生产损失。 游戏程序内许多数据处理代码的编程细节容易出现需要正确和自动测试的虚假报表。 本文探讨了在电源程序内应用突变测试, 这是一种基于错误的测试技术, 依赖错误模拟来评估和设计测试装置。 论文介绍了用于测试火花程序的TRANSMUT-Spoint解决方案。 TRANDMUT-Spoint 自动显示程序最艰苦的步骤, 并充分实施突变试验过程。 本文描述了变体的自动生成、 测试执行和适当分析阶段, 也用TRAMUTS-Sprint 来模拟测试。