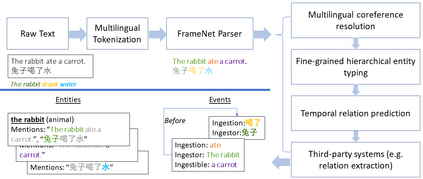
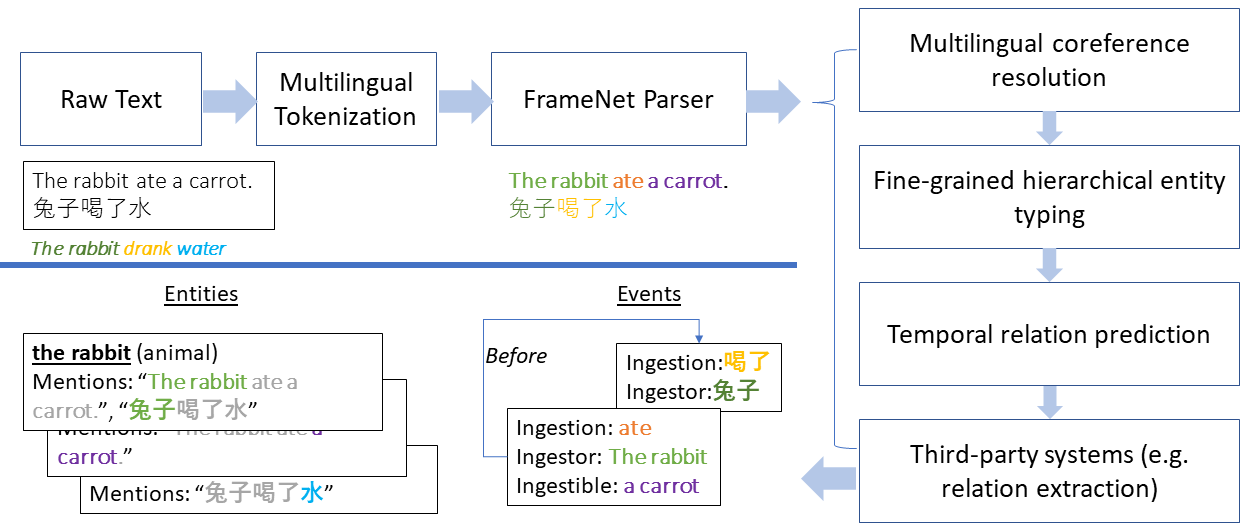
We present LOME, a system for performing multilingual information extraction. Given a text document as input, our core system identifies spans of textual entity and event mentions with a FrameNet (Baker et al., 1998) parser. It subsequently performs coreference resolution, fine-grained entity typing, and temporal relation prediction between events. By doing so, the system constructs an event and entity focused knowledge graph. We can further apply third-party modules for other types of annotation, like relation extraction. Our (multilingual) first-party modules either outperform or are competitive with the (monolingual) state-of-the-art. We achieve this through the use of multilingual encoders like XLM-R (Conneau et al., 2020) and leveraging multilingual training data. LOME is available as a Docker container on Docker Hub. In addition, a lightweight version of the system is accessible as a web demo.
翻译:我们提出LOME,这是一个多语种信息提取系统。用一个文本文件作为投入,我们的核心系统用一个框架网(Baker等人,1998年)来确定文本实体和事件的范围(Baker等人,1998年),然后进行共同参照分辨率、细刻式实体打字和事件之间的时间关系预测。通过这样做,系统可以构建一个事件和实体集中知识图。我们还可以将第三方模块应用于其他类型的说明,如关系提取。我们(多语种)的第一党模块要么表现超常,要么与(双语)最新技术相比具有竞争力。我们通过使用XLM-R(Connaau等人,2020年)等多语种编码和多语种培训数据实现这一点。LOME作为多语种集装箱在多语种中心可以使用。此外,一个轻量的系统版本也可以作为网络演示。