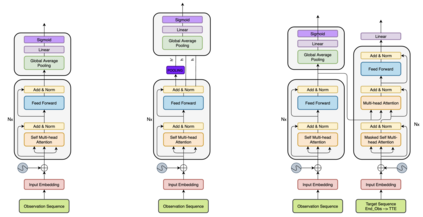
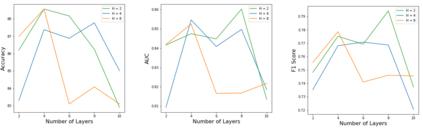
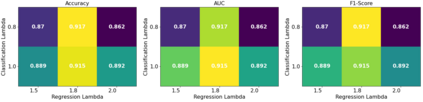
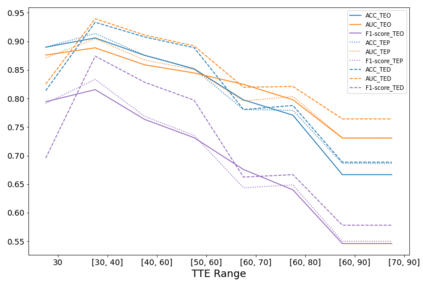
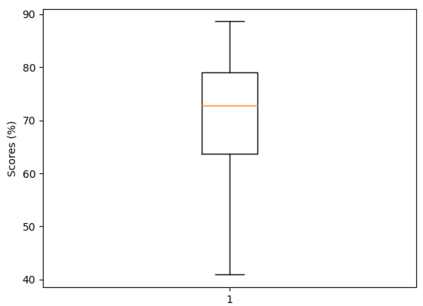
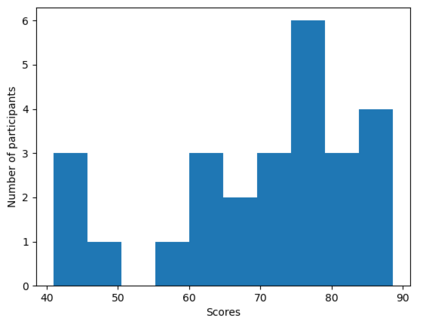
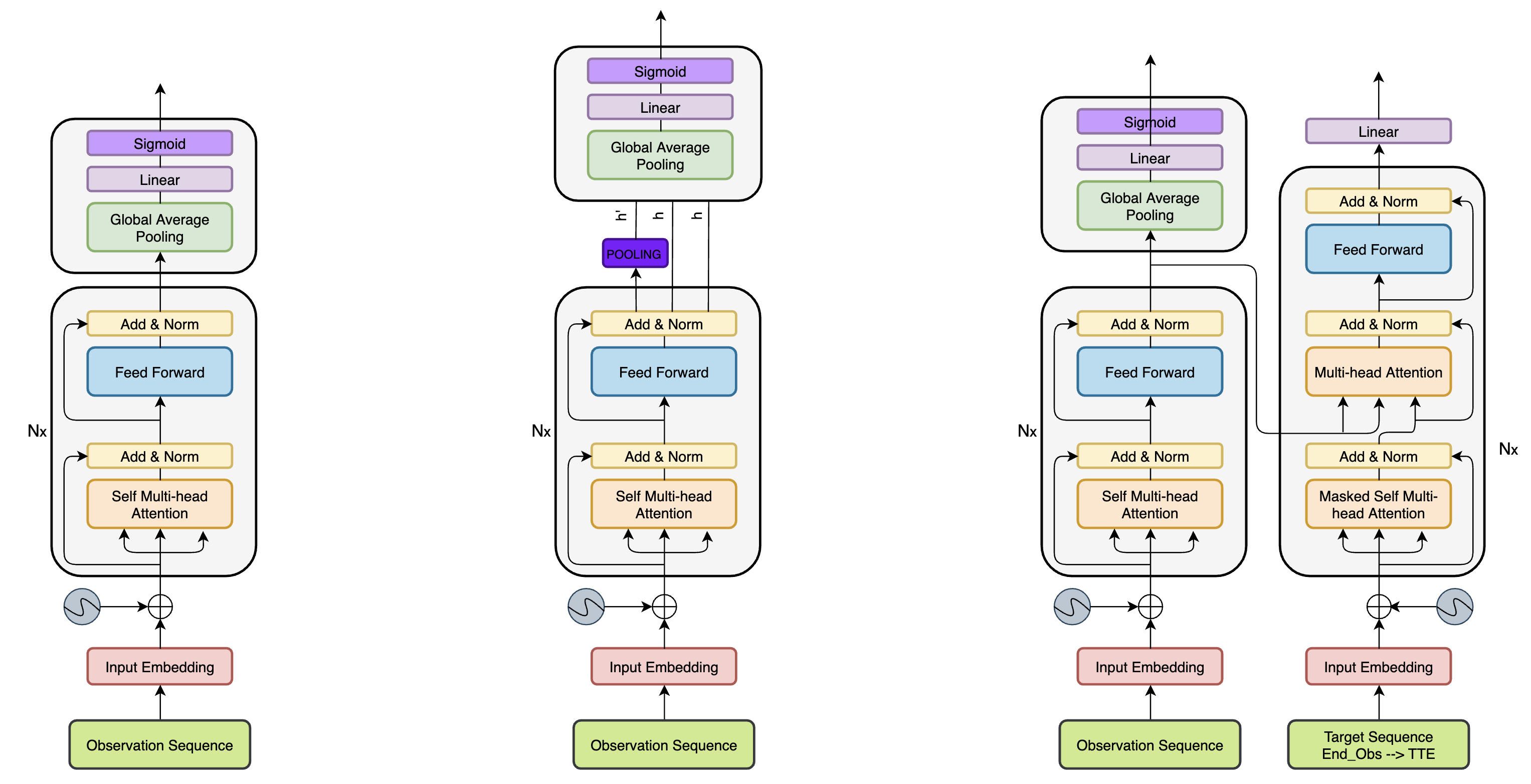
The human driver is no longer the only one concerned with the complexity of the driving scenarios. Autonomous vehicles (AV) are similarly becoming involved in the process. Nowadays, the development of AV in urban places underpins essential safety concerns for vulnerable road users (VRUs) such as pedestrians. Therefore, to make the roads safer, it is critical to classify and predict their future behavior. In this paper, we present a framework based on multiple variations of the Transformer models to reason attentively about the dynamic evolution of the pedestrians' past trajectory and predict its future actions of crossing or not crossing the street. We proved that using only bounding boxes as input to our model can outperform the previous state-of-the-art models and reach a prediction accuracy of 91% and an F1-score of 0.83 on the PIE dataset up to two seconds ahead in the future. In addition, we introduced a large-size simulated dataset (CP2A) using CARLA for action prediction. Our model has similarly reached high accuracy (91%) and F1-score (0.91) on this dataset. Interestingly, we showed that pre-training our Transformer model on the simulated dataset and then fine-tuning it on the real dataset can be very effective for the action prediction task. Finally, we created the "human attention to bounding boxes" experiment that equally proved the ability of humans to predict the future sufficiently by only giving attention to the bounding boxes without the need for environmental context.
翻译:人类司机不再是唯一关注驾驶方案复杂性的驱动器。 自治车辆( AV) 正在同样地参与这一进程。 如今, 城市地区的AV在城市发展是行人等弱势道路使用者(VRUs)基本安全关切的基础。 因此, 为使道路更加安全, 关键是要对道路进行分类和预测其未来行为。 在本文件中, 我们提出了一个基于变异器模型多种变异的框架, 以关注行人过去轨迹的动态演进, 并预测行人今后跨越或跨越街道的行动。 我们证明, 仅使用装装箱作为模型的输入, 能够超越我们以前最先进的模型, 并达到91% 和 F1 的预测准确度。 因此, 在未来两秒钟内, 要使 PIE 数据集更加安全, 我们推出一个大型的模拟数据集( CP2A ), 以便使用 CARLA 来进行行动预测。 我们的模型同样达到了很高的准确性( 91% ) 和 F1 - core ( 0.91) ) 。 我们证明, 在这个精细的数据集中, 我们最后展示了“ 之前的模型能模拟的模型, 校验定的模型, 使人类变形的模型能数据 成为我们之前的模拟的模拟的模拟的模拟的模拟的模拟数据 成为了人类变形变形的模型, 。