
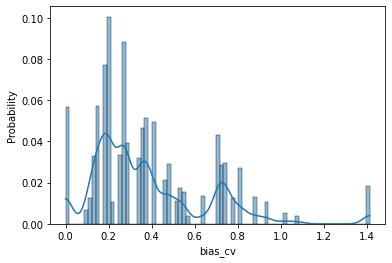
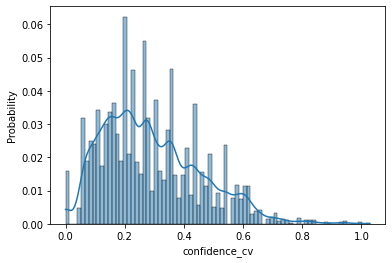
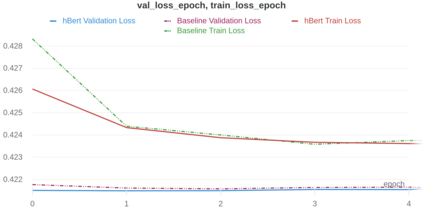
Subtle and overt racism is still present both in physical and online communities today and has impacted many lives in different segments of the society. In this short piece of work, we present how we're tackling this societal issue with Natural Language Processing. We are releasing BiasCorp, a dataset containing 139,090 comments and news segment from three specific sources - Fox News, BreitbartNews and YouTube. The first batch (45,000 manually annotated) is ready for publication. We are currently in the final phase of manually labeling the remaining dataset using Amazon Mechanical Turk. BERT has been used widely in several downstream tasks. In this work, we present hBERT, where we modify certain layers of the pretrained BERT model with the new Hopfield Layer. hBert generalizes well across different distributions with the added advantage of a reduced model complexity. We are also releasing a JavaScript library and a Chrome Extension Application, to help developers make use of our trained model in web applications (say chat application) and for users to identify and report racially biased contents on the web respectively.
翻译:现今,在实体和网络社群中,公开和隐含的种族主义仍然存在,已经影响到社会不同阶层的许多人。在这个短短的作品中,我们展示了我们如何通过自然语言处理来解决这个社会问题。我们正在释放BiasCorp,这是一个包含139,090条评论的数据集,以及来自三个具体来源 -- -- Fox News、 BreitbartNews和YouTube -- -- 的新闻报道部分。第一批(45 000条手动附加说明)已经准备出版。我们目前正处于使用亚马逊机械土耳其语手动标注剩余数据集的最后阶段。BERT在几个下游任务中被广泛使用。在这项工作中,我们展示了HBERT, 我们用新的Hopfield层对预先训练的BERT模型的某些层次进行了修改。 hBert 将不同版本的分布广泛化,增加了模型复杂性的优势。我们还发行了JavaScript图书馆和Chrome扩展应用程序,以帮助开发者使用我们在网络应用中经过训练的模型(说聊天应用程序),用户可以分别识别和报告网上有种族偏见的内容。


相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem


