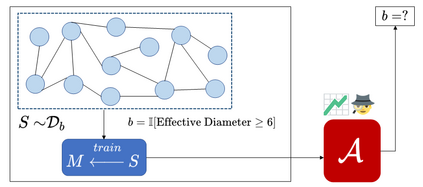
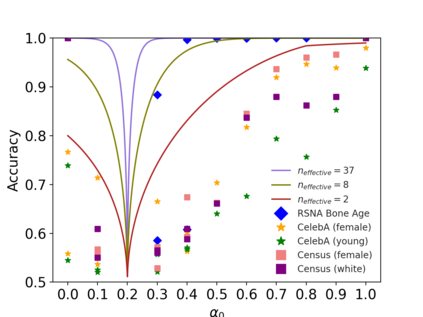
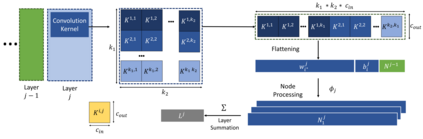
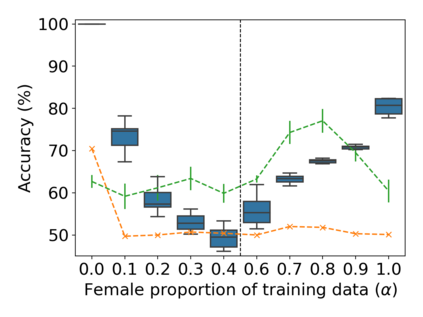
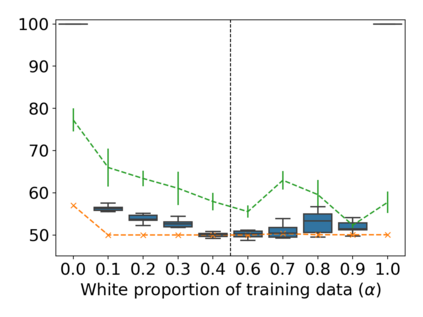
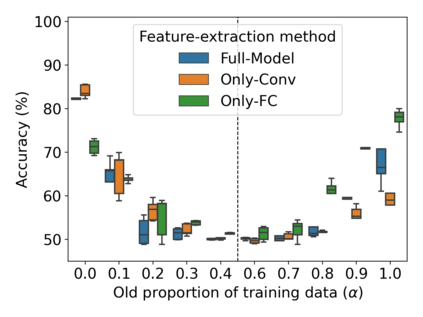
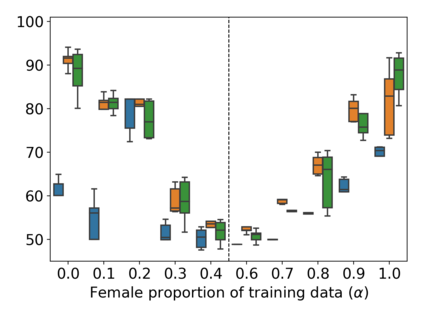
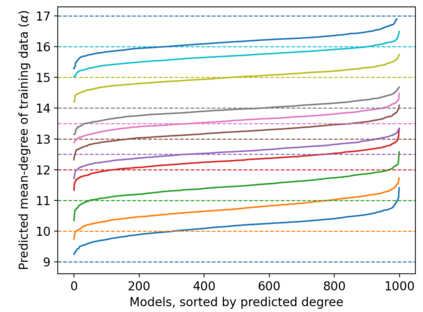
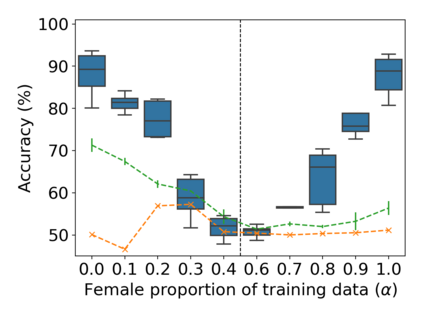
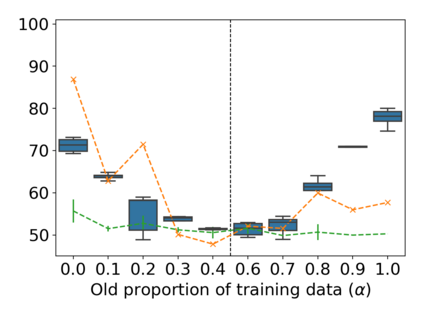
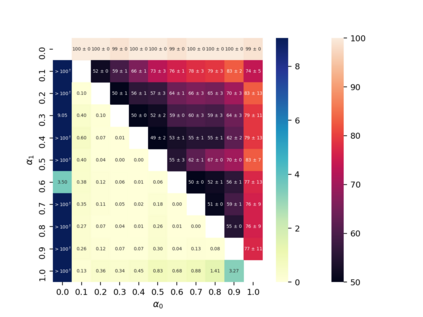
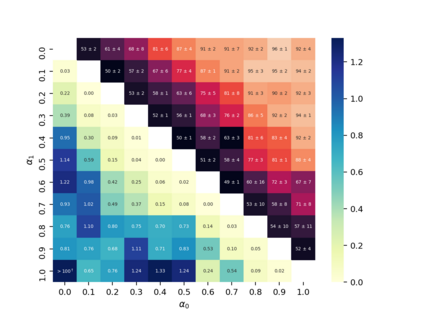
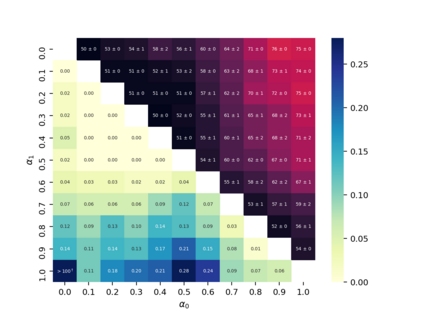
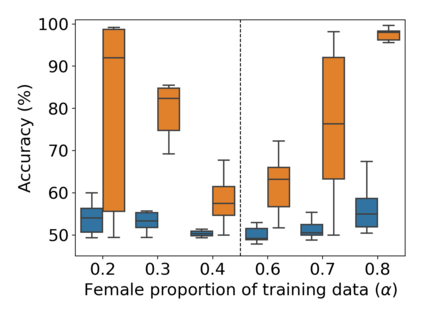
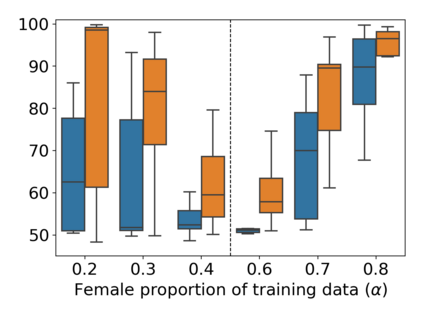
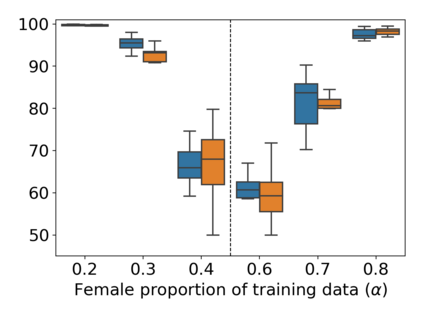
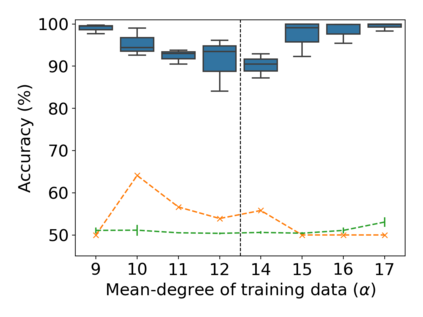
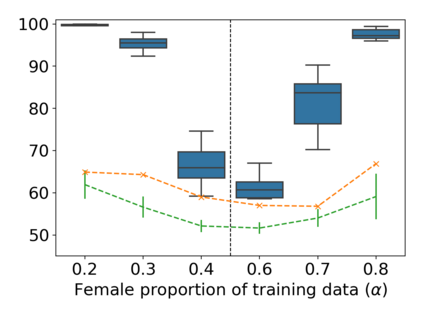
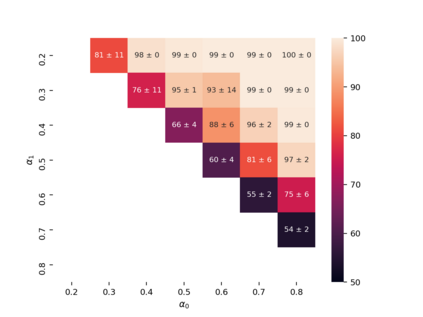
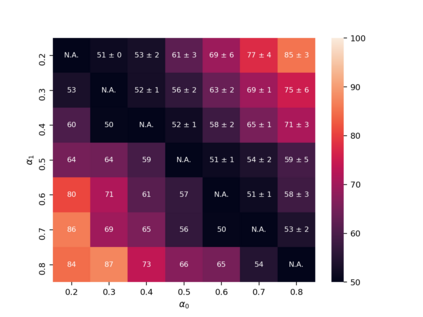
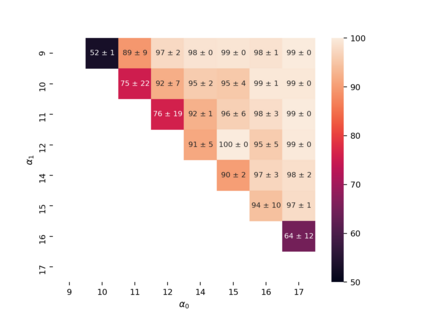
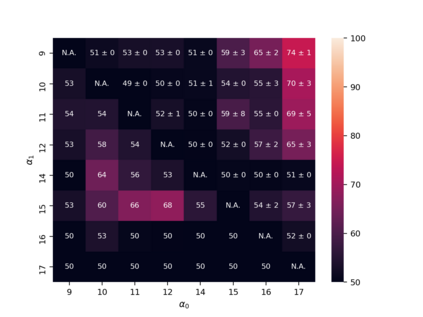
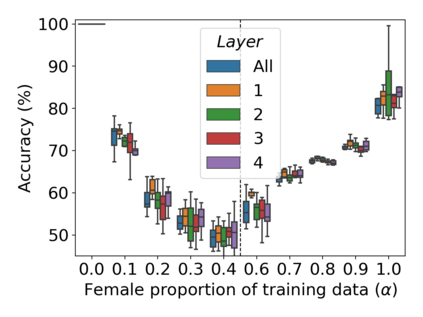
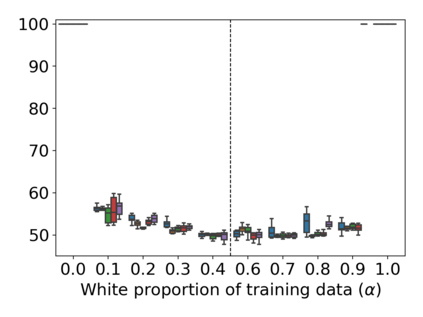
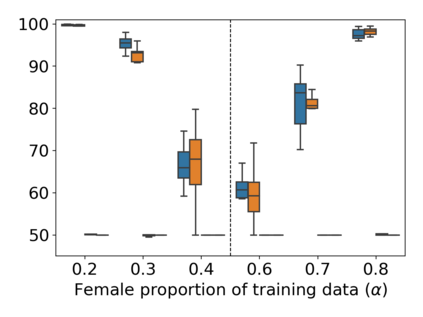
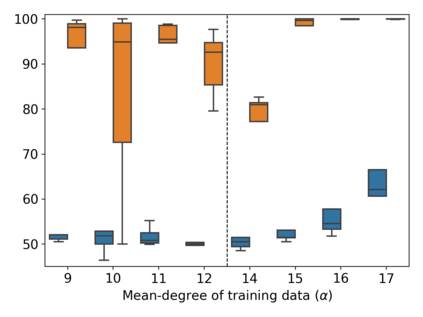
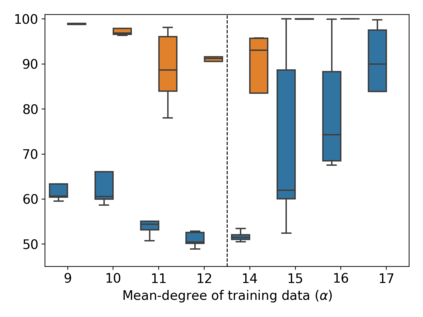
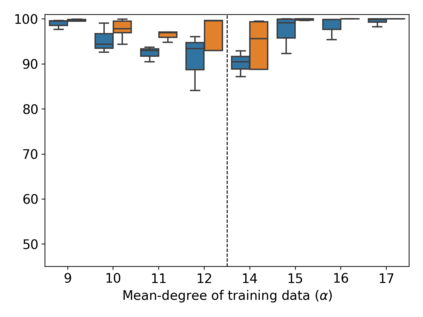
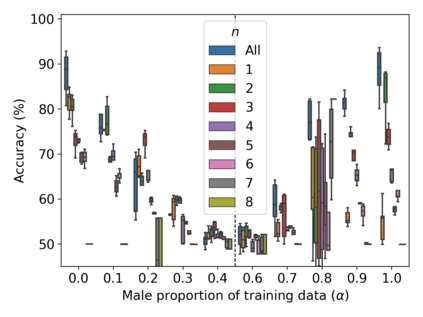
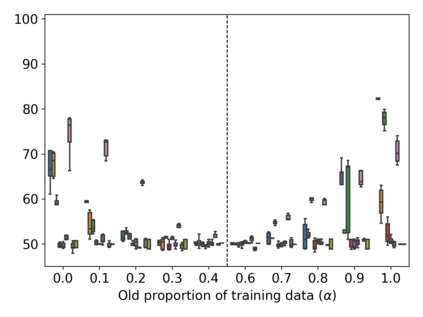
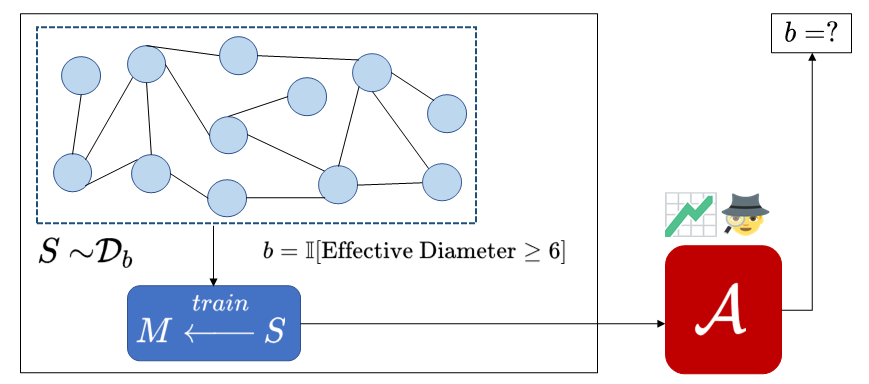
Property inference attacks reveal statistical properties about a training set but are difficult to distinguish from the intrinsic purpose of statistical machine learning, namely to produce models that capture statistical properties about a distribution. Motivated by Yeom et al.'s membership inference framework, we propose a formal and general definition of property inference attacks. The proposed notion describes attacks that can distinguish between possible training distributions, extending beyond previous property inference attacks that infer the ratio of a particular type of data in the training data set such as the proportion of females. We show how our definition captures previous property inference attacks as well as a new attack that can reveal the average node degree or clustering coefficient of a training graph. Our definition also enables a theorem that connects the maximum possible accuracy of inference attacks distinguishing between distributions to the effective size of dataset leaked by the model. To quantify and understand property inference risks, we conduct a series of experiments across a range of different distributions using both black-box and white-box attacks. Our results show that inexpensive attacks are often as effective as expensive meta-classifier attacks, and that there are surprising asymmetries in the effectiveness of attacks. We also extend the state-of-the-art property inference attack to work on convolutional neural networks, and propose techniques to help identify parameters in a model that leak the most information, thus significantly lowering resource requirements for meta-classifier attacks.
翻译:属性推断攻击揭示了对一组培训的统计属性,但很难与统计机器学习的内在目的区分,即制作反映分布统计属性的模型。受Yeom等人成员推论框架的激励,我们提出了财产推断攻击的正式和一般定义。拟议的概念描述了可以区分可能的培训分布的攻击,范围超出了以前的财产推断攻击,从而推断出培训数据集中特定类型数据(如女性比例)的比例。我们展示了我们的定义如何捕捉了先前的财产推断攻击以及能够显示培训图表平均偏差程度或组合系数的新攻击。我们的定义还使一种理论能够将推断攻击的最大可能准确性与模型所泄漏的数据的有效大小区分起来。为了量化和理解财产推断风险,我们利用黑箱和白箱攻击等不同类型模型分布进行了一系列实验。我们的结果显示,廉价攻击往往具有昂贵的元分类攻击的效力,或能够显示培训图的平均值系数。我们的定义还使推断攻击的最大可能精确度与模型分布的分布值联系起来,从而可以令人惊讶地将资产推断为变价攻击的系统定义。