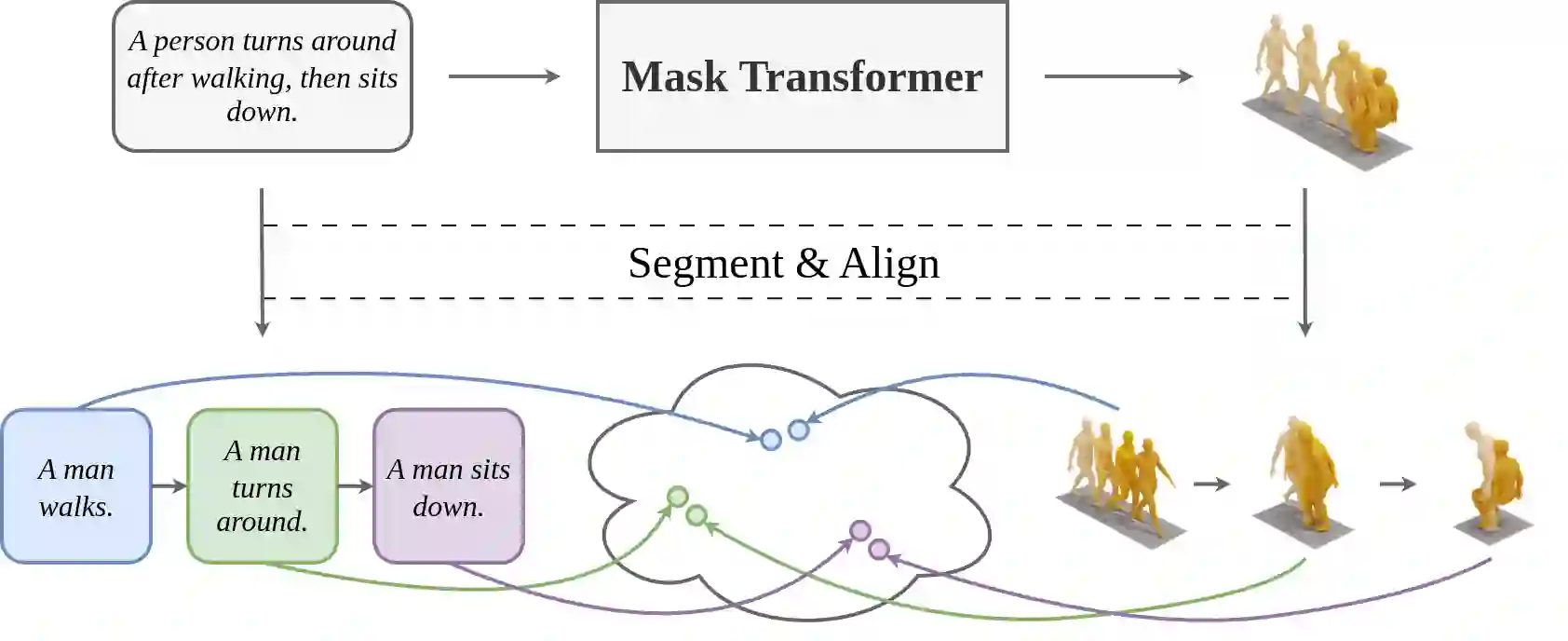
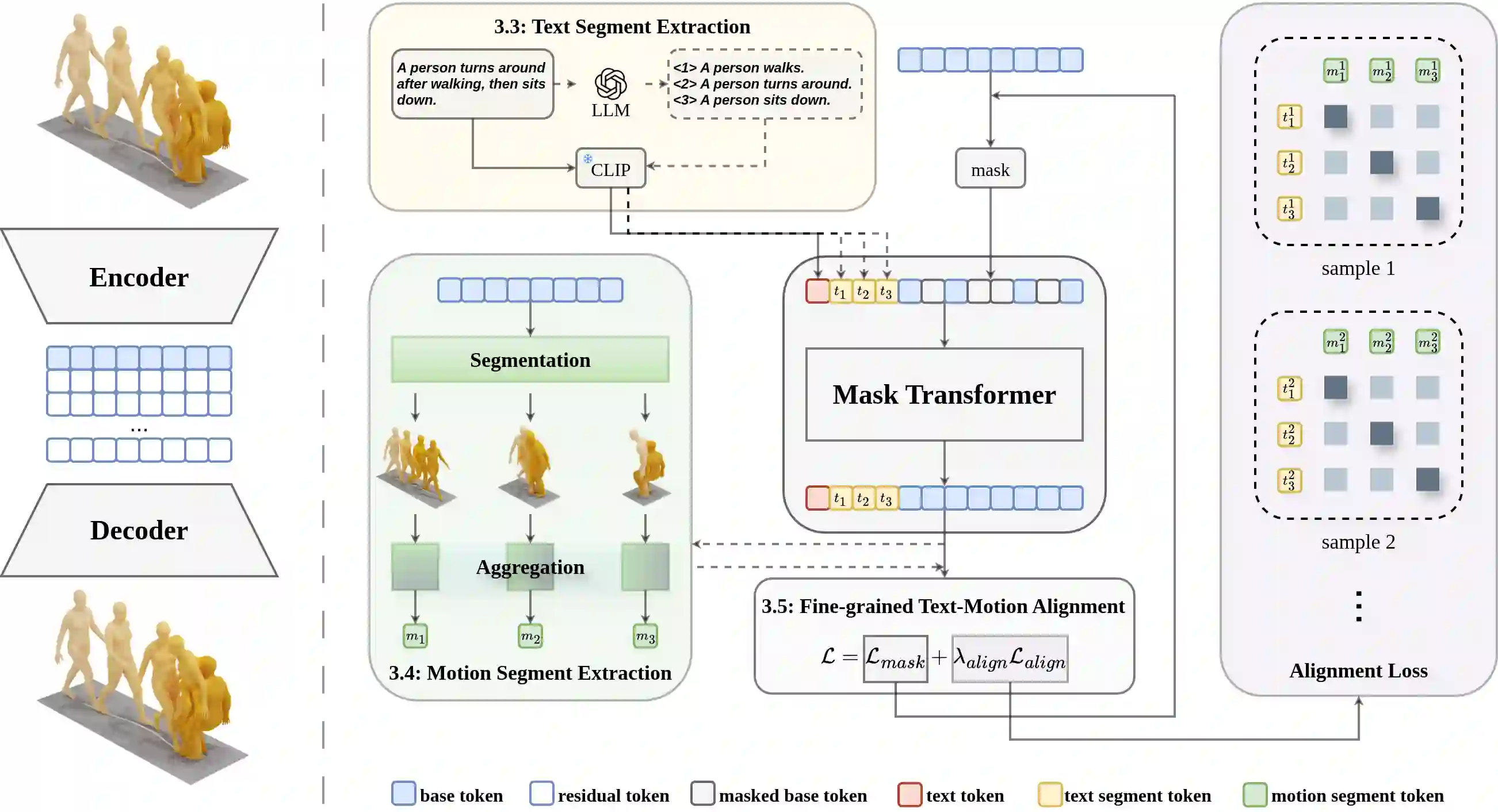
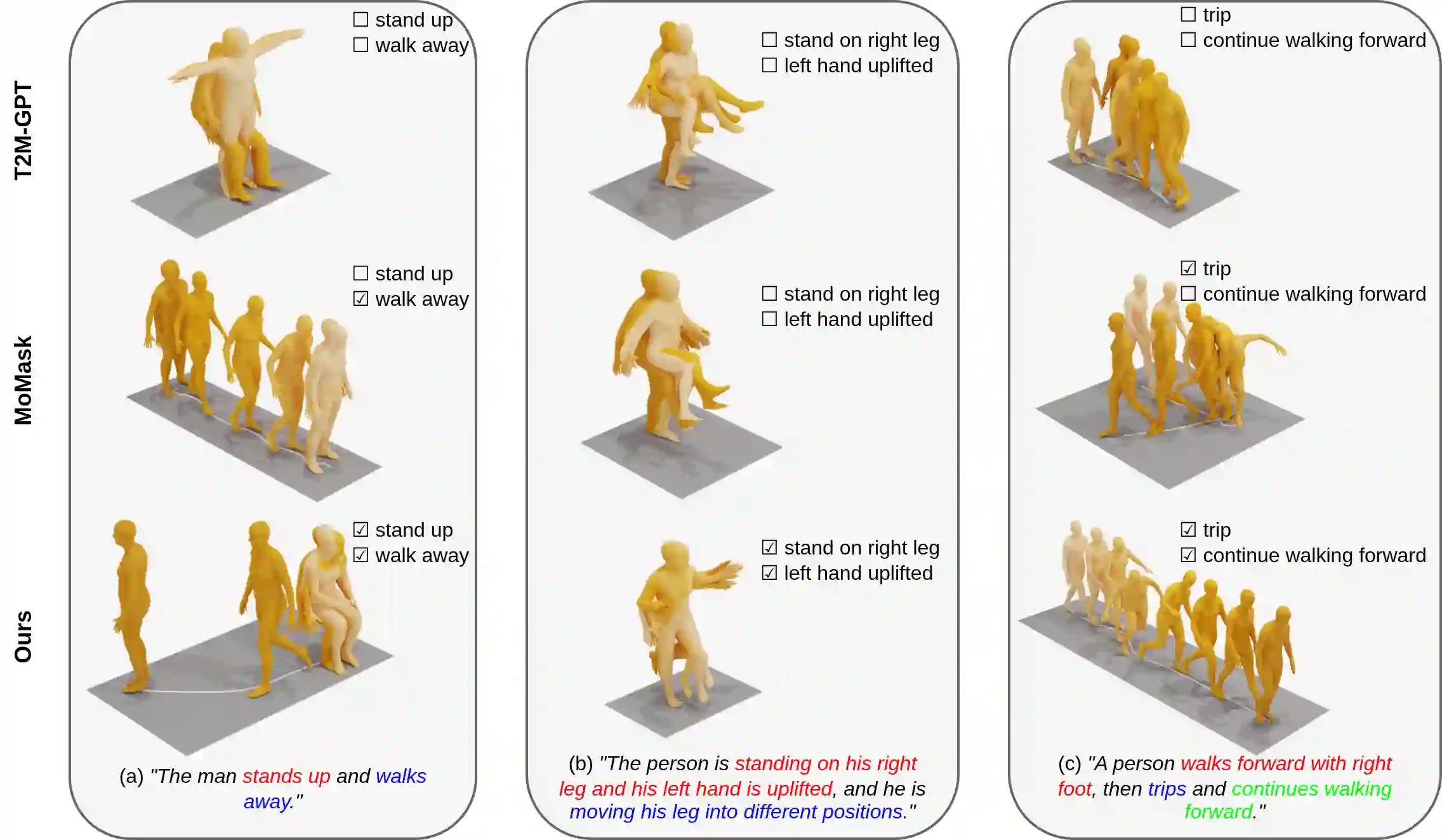
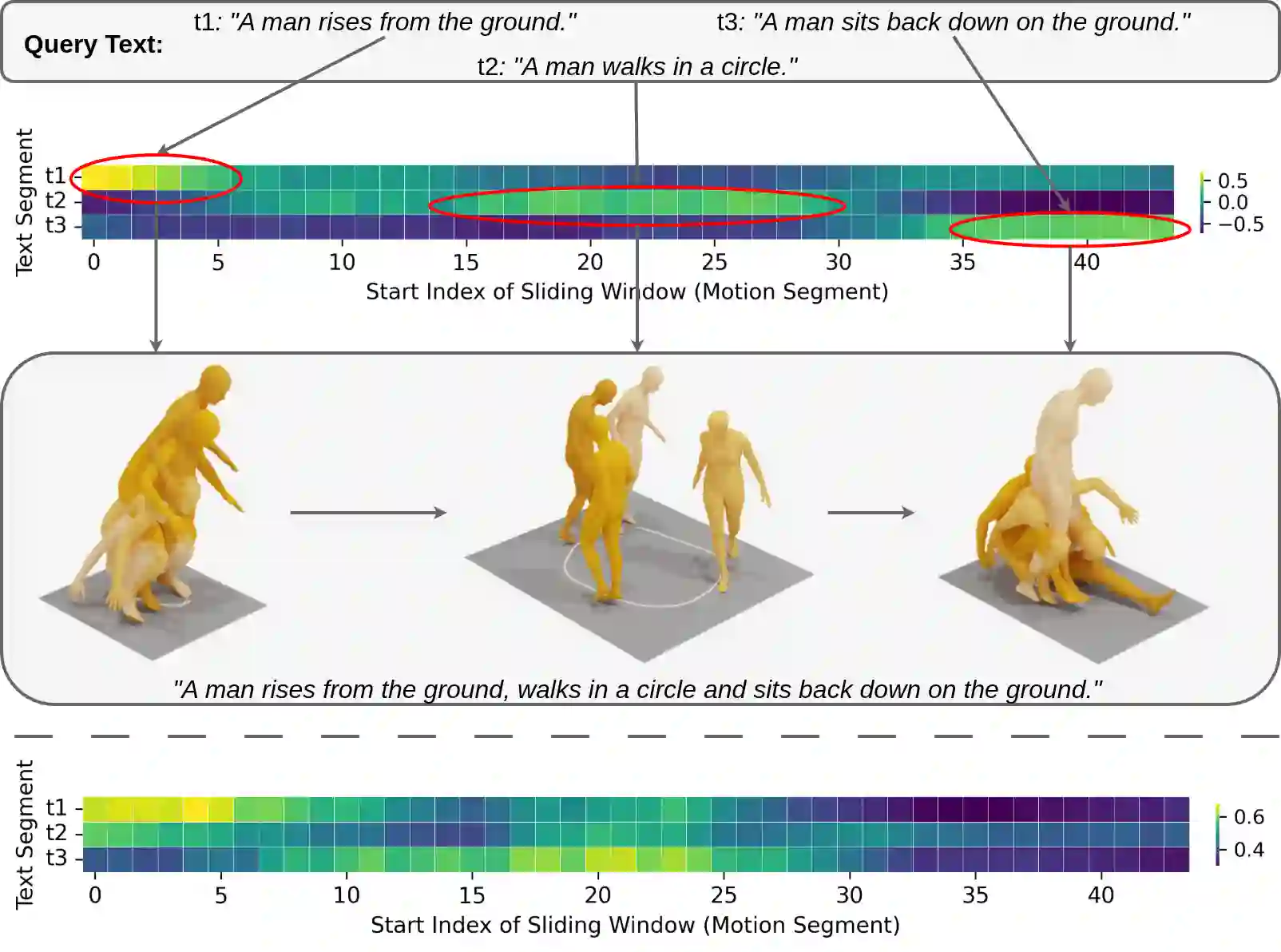
Generating 3D human motions from textual descriptions is an important research problem with broad applications in video games, virtual reality, and augmented reality. Recent methods align the textual description with human motion at the sequence level, neglecting the internal semantic structure of modalities. However, both motion descriptions and motion sequences can be naturally decomposed into smaller and semantically coherent segments, which can serve as atomic alignment units to achieve finer-grained correspondence. Motivated by this, we propose SegMo, a novel Segment-aligned text-conditioned human Motion generation framework to achieve fine-grained text-motion alignment. Our framework consists of three modules: (1) Text Segment Extraction, which decomposes complex textual descriptions into temporally ordered phrases, each representing a simple atomic action; (2) Motion Segment Extraction, which partitions complete motion sequences into corresponding motion segments; and (3) Fine-grained Text-Motion Alignment, which aligns text and motion segments with contrastive learning. Extensive experiments demonstrate that SegMo improves the strong baseline on two widely used datasets, achieving an improved TOP 1 score of 0.553 on the HumanML3D test set. Moreover, thanks to the learned shared embedding space for text and motion segments, SegMo can also be applied to retrieval-style tasks such as motion grounding and motion-to-text retrieval.
翻译:从文本描述生成三维人体运动是一个重要的研究问题,在电子游戏、虚拟现实和增强现实中具有广泛的应用。现有方法通常在序列级别上将文本描述与人体运动对齐,忽略了模态内部的语义结构。然而,运动描述和运动序列都可以自然地分解为更小且语义连贯的片段,这些片段可以作为原子对齐单元以实现更细粒度的对应关系。受此启发,我们提出了SegMo,一种新颖的基于片段对齐的文本条件人体运动生成框架,以实现细粒度的文本-运动对齐。我们的框架包含三个模块:(1)文本片段提取,将复杂的文本描述分解为时间有序的短语,每个短语代表一个简单的原子动作;(2)运动片段提取,将完整的运动序列分割为相应的运动片段;(3)细粒度文本-运动对齐,通过对比学习对齐文本和运动片段。大量实验表明,SegMo在两个广泛使用的数据集上改进了强基线,在HumanML3D测试集上实现了0.553的改进TOP 1分数。此外,得益于学习到的文本和运动片段共享嵌入空间,SegMo也可应用于检索式任务,如运动定位和运动到文本检索。