【预告】CSIG图像图形技术国际在线研讨会第六期将于7月5日举办

近年来,3D场景的理解与建模在计算机视觉、计算机图形学、机器人等领域受到广泛大量关注。场景理解与建模是智能机器人探索环境、理解环境、与环境发生交互、完成各种智能任务的使能技术,也是构建真实世界的数字孪生,实现元宇宙的重要技术。围绕这一主题,中国图象图形学学会(CSIG)将于2022年7月5日(周二)19:30-21:30举办CSIG图像图形技术国际在线研讨会第六期(3D场景理解与建模专题)。会议邀请了来自4位该方向的国际顶尖、活跃学者介绍他们在场景理解和建模领域的最新研究成果,并围绕该领域当下挑战及未来趋势开展讨论。期待学术与工业界同行的积极参与!
会议直播:https://meeting.tencent.com/l/PTatQESfNEHf
或长按以下二维码进入:

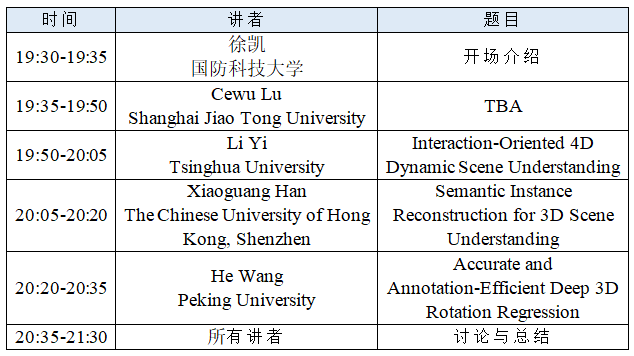
会议日程
讲者简介

Shanghai Jiao Tong University
Cewu Lu is a professor at Shanghai Jiao Tong University. His research interests fall mainly in Computer Vision and Intelligent Robot, and has made many innovative contributions in these fields. He has published more than 100 papers at top conferences and Journals, like Nature/ Nature Machine Intelligence/TPAMI/CVPR/ICCV, etc. He served as the Senior Area Chair of NeurIPS2022, Associate Editor of IROS 2021/2022, Area Chair of CVPR 2020/ ICCV2021/ECCV2022, Senior Program Committee Members of AAAI 2020/2021, and reviewer for the journal Science. In 2016, he was selected as the National "1000 Youth Talents Plan". In 2018, he was selected as 35 Innovators Under 35 (MIT TR35) by MIT Technology Review. In 2019, he was awarded “Qiu Shi Outstanding Young Scholar”. In 2020, he was awarded the “Special Prize of Shanghai Science and Technology Progress Award”.

Li Yi
Tsinghua University
Li Yi is a tenure-track assistant professor in the Institute for Interdisciplinary Information Sciences (IIIS) at Tsinghua University. He received his Ph.D. from Stanford University, advised by Professor Leonidas J. Guibas. And he was previously a Research Scientist at Google working closely with Professor Thomas Funkhouser. Before joining Stanford, he got his B.E. in Electronic Engineering from Tsinghua University. His recent research focuses on 3D perception and shape analysis, and his mission is to equip robotic agents with the ability of understanding and interacting with the 3D world. He has published papers at CVPR, ICCV, ECCV, NeurIPS, SIGGRAPH, SIGGRAPH Asia, etc, and he served as an Area Chair for CVPR 2022. His representative work includes ShapeNet-Part, SyncSpecCNN, PointNet++.
Talk title: Interaction-Oriented 4D Dynamic Scene Understanding
Abstract: Tremendous progress has been made for static 3D scene understanding over the last decade. However, detecting or segmenting 3D objects from static scenes fails to satisfy the needs of more and more critical applications such as human-assistant robots and augmented reality where the perception of interactions from dynamic 4D sensory inputs (e.g., temporal streams of colored point clouds) is required. Such 4D perception should unify semantic understanding with extraction and tracking of actionable information (e.g., parts, affordance, pose), which poses challenges to today’s 3D computer vision systems. We tackle these challenges from 4D dataset construction, 4D learning backbone design, and actionable information perception. In this talk, I will introduce our recent efforts on a large-scale 4D category-level human-object interaction dataset named HOI4D, which is designed to accelerate the understanding of dynamic human-object interaction in real scenes from a first-person perspective. I will also talk about our novel architecture design to support more effective and efficient deep learning on 4D point cloud sequences.

Xiaoguang Han
The Chinese University of Hong Kong, Shenzhen
Dr.Xiaoguang Han is now an Assistant Professor and President Young Scholar of the Chinese University of Hong Kong (Shenzhen) and the Future Intelligence Network Research Institute. He received his PhD degree from the University of Hong Kong in 2017. His research interests include computer vision and computer graphics. He has published nearly 50 papers in well-known international journals and conferences, including top conferences and journals SIGGRAPH(Asia), CVPR, ICCV, ECCV, NeurIPS, ACM TOG, IEEE TPAMI, etc. He is currently a guest editor of Frontiers of Virtual Reality. He won the 2021 Wu Wenjun Artificial Intelligence Outstanding Youth Award, the IEEE TVCG 2021 Best Reviewer Honorable Mention, his work has won the CCF Graphics Open Source Dataset Award (DeepFashion3D), his two works were selected as the best paper candidate in CVPR 2019 and 2020(the selection rate is 0.8% and 0.4% respectively), he also won the best paper honorable mention in IEEE VR 2021, the best presentation award for emerging technologies in Siggraph Asia 2013. More information can be reached via: https://gaplab.cuhk.edu.cn/
Talk title: Semantic Instance Reconstruction for 3D Scene Understanding
Abstract: 3D scene understanding and reconstruction plays very important roles in many application scenarios, like robot perception and also AR/VR etc. Currently, most of existing works treated the 3D scene as a whole unit for reconstruction. In this talk, I will introduce our recent techniques that conducted reconstruction together with instance understanding, which is termed as “Semantic Instance Reconstruction”. The main content includes two published works: Total3DUnderstanding (CVPR 2020) and RfD-Net (CVPR 2021). They are all aiming to semantic instance reconstruction, but Total3D focuses on reconstruction from single images while RfD-Net takes point cloud as input. In the next, I will also introduce an advanced technique for high-fidelity single-view 3D instance reconstruction.

He Wang
Peking University
Dr. He Wang is a tenure-track assistant professor in the Center on Frontiers of Computing Studies (CFCS) at Peking University, where he founds and leads Embodied Perception and InteraCtion (EPIC) Lab. Prior to joining Peking University, he received his Ph.D. degree from Stanford University in 2021 under the advisory of Prof. Leonidas J. Guibas and his Bachelor's degree in 2014 from Tsinghua University. His research interests span 3D vision, robotics, and machine learning, with a special focus on embodied AI. His research objective is to endow robots working in complex real-world scenes with generalizable 3D vision and interaction policies. He has published more than 20 papers on top vision and learning conferences (CVPR/ICCV/ECCV/NeurIPS) with 8 of his works receiving CVPR/ICCV orals and one work receiving Eurographics 2019 best paper honorable mention. He serves as an area chair in CVPR 2022 and WACV 2022.
Talk title: Accurate and Annotation-Efficient Deep 3D Rotation Regression
Abstract: 3D rotation estimation is an important technique in computer vision, graphics and robotics. In the deep learning era, deep 3D rotation regression modules become more and more popular and have been widely deployed to improve understanding of objects, humans, cameras and interactions in 3D scenes, thanks to its plug-and-play nature and end-to-end behavior. Despite of being widely used, deep rotation regression is still facing several major challenges that significantly limits its performance and usage. First, compared to coordinate-based approaches, directly regressing rotations has been suffering from low accuracy, given that rotations lie in SO(3), which is a non-Euclidean manifold and therefore very challenging to be directly regressed. Furthermore, fully supervised 3D rotation learning can’t be easily scaled up, since accurate 3D rotation anotations are very expensive and time-consuming to obtain. In this talk, I would introduce our recent efforts to make deep 3D rotation regressions more accurate and more annotation-efficient, including one CVPR 2022 oral work that introduces the first semi-supervised rotation regression framework, FisherMatch , along with another CVPR 2022 work, Regularized Projective Manifold Gradient (RPMG), that significantly improves the accuracy of rotation regression on a wide range of 3D scene understanding tasks via proposing a novel gradient layer.
主持人简介

Kai Xu
National University of Defense Technology
Kai Xu is a Professor at the School of Computer, National University of Defense Technology, where he received his Ph.D. in 2011. He is an adjunct professor of Simon Fraser University. During 2017-2018, he was a visiting research scientist at Princeton University. His research interests include geometric modeling and shape analysis, especially on data-driven approaches to the problems in those directions, as well as 3D vision and robotic applications. He has published over 100 research papers, including 27 SIGGRAPH/TOG papers. He serves on the editorial board of ACM Transactions on Graphics, and several other international journals. He also served as program co-chair and PC member for several prestigious conferences. He has co-organized many SIGGRAPH courses, Eurographics STAR tutorials and CVPR workshops. His personal website is: www.kevinkaixu.net
来源:CSIG国际合作与交流工委会



