国内首次零样本学习算法大赛开启报名,零样本数据集免费下载

去年,由创新工场、搜狗、头条联合主办的 AI Challenger(简称 AIC)全球 AI 挑战赛吸引了来自 65 个国家 8892 支团队参赛,经过激烈的角逐,最终胜出的团队共同瓜分了大赛提供的百万奖金。
2018,AIC 全新赛季开启预热。3 月 22 日起,零样本学习(zero-shot learning)竞赛正式在线开启比赛。
这次的零样本学习竞赛同样发布大规模图像属性数据集,包含 78017 张图片、230 个类别、359 种属性。与目前主流的用于 zero-shot learning 的数据集相比,图片量更大、属性更丰富、类别与 ImageNet 重合度更低。
零样本学习(zero-shot learning)
什么是零样本学习?简单来说就是识别从未见过的数据类别,即训练的分类器不仅仅能够识别出训练集中已有的数据类别,还可以对于来自未见过的类别的数据进行区分。例如识别一张猫的图片,但在训练时没有训练到猫的图片和对应猫的标签。那么就可以通过比较这张猫的图片和训练过程中的哪些图片相近,进而找到相近图片的标签,再通过这些相近标签去找到猫的标签。本质上,零样本学习属于迁移学习的一种。
零样本学习的意义也显而易见:在传统图像识别任务中,训练阶段和测试阶段的类别是相同的,但每次为了识别新类别的样本需要在训练集中加入这种类别的数据。一些类别的样本收集代价大,即使收集到足够的训练样本,也需要对整个模型进行重新训练。这都会加大识别系统的成本,零样本学习方法便能很好的解决这个问题。
零样本学习研究现状
早期的零样本学习研究可以追溯到 2008 年。那时,Larochelle 等人针对字符分类问题提出了零样本学习(zero shot learning)方法,并且识别准确率达到了 60%。
2009 年 Lampert 等人提出了 Animals with Attributes 数据集和经典的基于属性学习的算法,才算真正打开零样本学习的关注度。
2013 年,发表在 NIPS 上的论文《DeViSE: A Deep Visual-Semantic Embedding Model》,解决了如何将已有的图像分类模型应用到训练中未涉及到的图像分类中。
2014 年,在 ICLR 2014 上的发表的《Zero-Shot Learning by Convex Combination of Semantic Embeddings》继承了前人研究方法中的主要思想(CNN+word2vec),但使用了更简单的方法,从而保留了整个 CNN 结构,且不需要 linear transformation。
之后,发表在 ICCV 2015 上的《Objects2action: Classifying and localizing actions without any video example》将零样本学习研究又向前推动了一步。
如果读了上面提到的三篇论文,大概会对零样本学习的研究方法有所了解。但最经典的零样本学习方法是 Lampert 发表在 CVPR 2009 上的一篇论文《Learning To Detect Unseen Object Classes by Between-Class Attribute Transfer 》提出的直接属性预测模型 (DAP)。
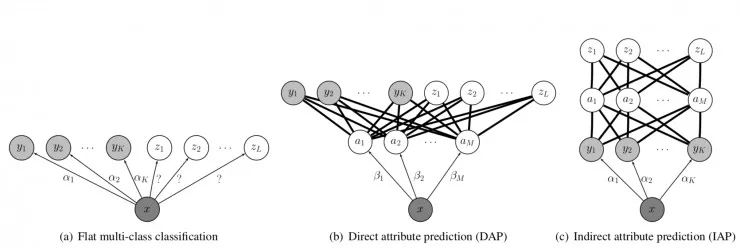
模型中属性训练是在传统特征提取的基础上的进行的,首先使用颜色直方图、局部自相似直方图、SIFT 和 PHOG 等 6 种方法来提取样本图像的底层特征,这几种特征包含了图像的颜色、形状和纹理等方面,所以通过这种特征提取方法得到的特征可以良好的表达图像中的信息。这几种图像特征不仅适用与线性分类器,而且在非线性分类器中也能达到良好的表现。在 DAP 方法中,通过上述的特征提取方法得到样本的图像特征后,将特征用于属性分类器的训练,然后将训练得出的模型用于属性的预测,最后采用贝叶斯方法推算测试样本的类别。近年来深度特征的使用大幅提高了零样本识别的准确率。
零样本学习潜在应用场景
零样本学习是希望借助辅助知识(如属性、词向量、文本描述等)学习从未见过的新概念。因此,在一些场景下,如细粒度物体识别、任意语言之间的翻译等,难以获得足够的有标注的数据来训练识别或预测模型可以尝试使用零样本学习来解决。
物体识别
例如,模型在「马」、「牛」等类别上训练过,因此模型能够准确地识别「马」、「牛」的图片。当模型遇到「象」这个新类别,由于从未见过,模型无法作出判断。传统解决方案是收集大量「象」的图片,与原数据集一起重新训练。这种解决方案的代价高、速度慢。然而,人类能够从描述性知识中快速学习一个新概念。例如,一个儿童即使没有见过「象」,当提供他文本描述「象是一种的大型食草类动物,有长鼻和长牙」。儿童能够根据描述快速学会「象」这一新类别,并能在第一次见到「象」时识别出来。零样本学习与之类似,在没有任何训练样本的情况下,借助辅助知识(如属性、词向量、文本描述等)学习一些从未见过的新概念(类别)。
语言翻译
比如说要进行三种语言之间的翻译,按照传统的方法需要分别训练六个网络,在日语和韩语之间没有那么多样本的情况下,训练英语→特征空间→日语,韩语→特征空间→英语这两个网络,那么就可以自动学会韩语→特征空间→日语这个翻译过程。
图像合成
近年来,对抗网络 GAN 被用于图像合成,取得了以假乱真的效果。但传统图像合成仅能合成见过的类别的图像。零样本图像合成希望模型能够合成从未见过的类别的图像。目前已有一些算法通过条件 GAN 网络实现了零样本图像合成。
图像哈希
传统图像哈希算法利用一些训练样本来学习针对某些类别的哈希算法。但这些学习到的哈希算法无法用于新类别。零样本图像哈希,希望在已知类别上学到哈希算法能够运用到新的未知类别上。目前,一些基于属性的零样本哈希算法已经被提出。
零样本学习竞赛
最后,欢迎对零样本学习有研究的同学们来参加此次比赛。
目前 AI Challenger 官网已开通报名参赛通道,报名截止日期在 4 月 23 日。感兴趣的同学一定要计划时间,不要错过这次报名!

比赛所用的数据集也已开放下载。
更多关于比赛的相关信息,请关注 https://challenger.ai/competitions 。
附竞赛奖励标准:
以下提及金额为税前金额,详细规则请参考《竞赛选手报名协议》
冠军:30,000 人民币,颁发获奖证书
亚军:10,000 人民币,颁发获奖证书
季军:3,000 人民币,颁发获奖证书
双周冠军:3,000 人民币
双周亚军:2,000 人民币
双周季军:1,000 人民币
数据集下载地址:https://challenger.ai/datasets

NLP 工程师入门实践班
三大模块,五大应用,知识点全覆盖;
海外博士讲师,丰富项目分享经验;
理论 + 实践,带你实战典型行业应用;
专业答疑社群,结交志同道合伙伴。
▼▼▼

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
产生和防御对抗样本的新方法
▼▼▼




