从零开始,搭建一个完善的AI应用

人工智能已经深入我们生活的很多场景,且不说 DeepMind 的 AlphaGo,IBM Waston 这样的原始创新。
电商网站的推荐系统,各种智能硬件的人脸识别,金融平台的风控系统,医疗机构的影像分析……已经在我们看不见的地方提供服务。
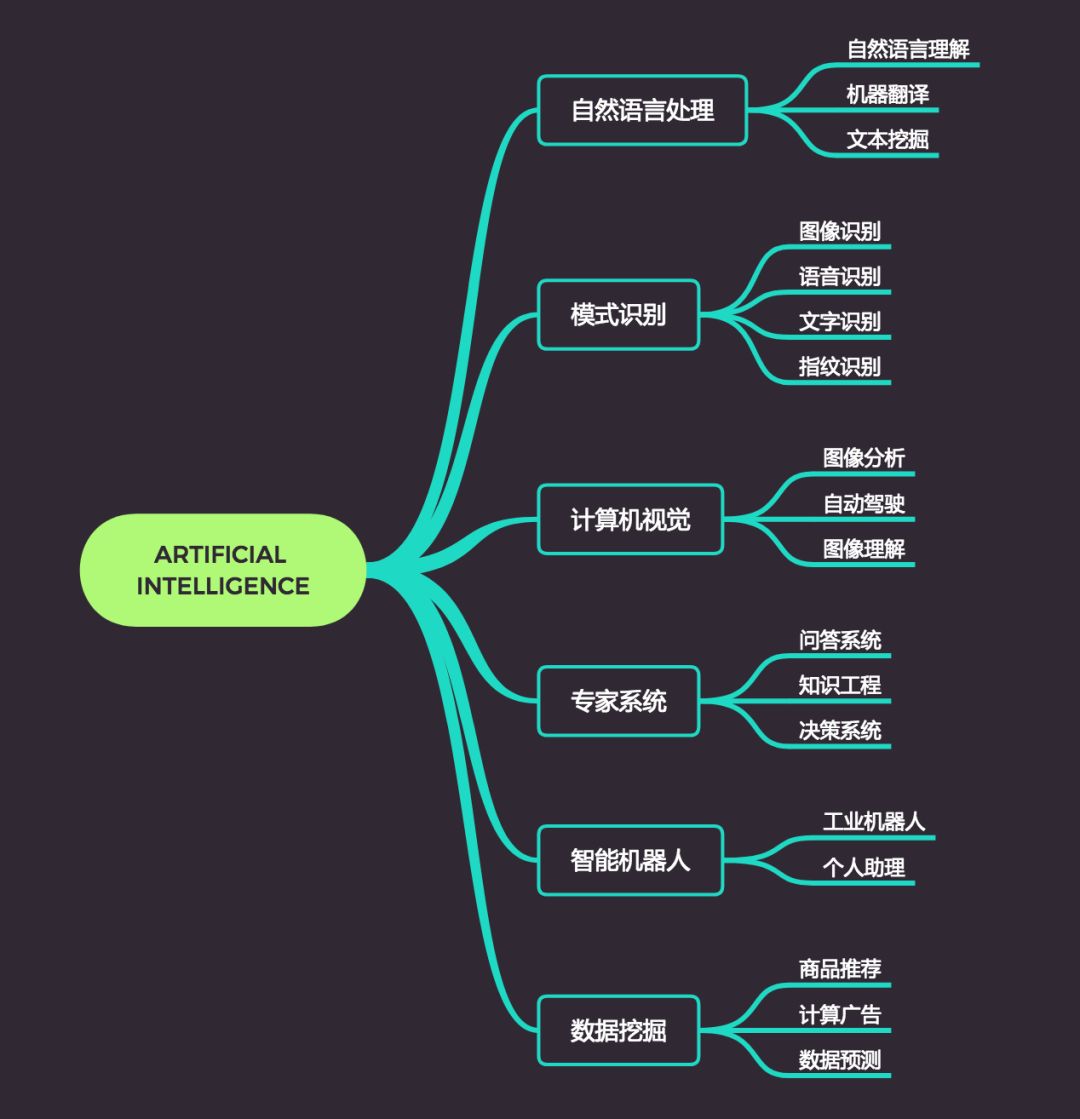
AI应用细分领域
这些看起来高深莫测的应用,背后运作的机制是怎样的?如何从零开始去搭建这样的一些应用?甚至进入AI行业,参与其中的工作?
一个非常重要的目标是,我们应该非常清晰地了解人工智能应用,是通过怎样的流程被创造出来的。一般而言,一个AI应用的形成会至少经过以下几个步骤:
1.问题定义与抽象
2.数据清洗与特征工程
3.算法选择与模型训练
4.模型调优与应用
接下来我们分别来看每个步骤的作用是什么,都在解决哪些问题,以及需要哪些技能。
1.问题定义与抽象
业务问题转化为技术问题,都要经过问题的抽象,映射成数学问题,才能方便用算法模型去解决。
比如要判定是否给用户发放贷款,那其实是去解决一个用户的二分类问题;又比如要给用户推荐更精准的内容,其实要做的就是用户点击率预测……
识别问题的类型,能够有效指导你选择模型的构架,优化方法等等。
其实我们要最终映射到的问题就那么几种:回归、分类、聚类。这个时候就要充分明确我们的业务,适合抽象为哪种问题来进行解决。
在充分理解业务的目标的情况下,我们要提炼出希望优化的目标(最大化…或最小化…),同时要确定我们约束是什么,然后抽象为机器学习模型需要解决的问题。
从某种程度上说,问题的抽象决定了我们整个项目的走向,如果对问题的分析或者界定不好,那么最后应用于业务效果也会大打折扣。这就需要具备以下几点能力:
1.对业务非常深刻的理解,包括商业模式、用户属性、用户行为、内容属性、优化目标等等;
2.对不同类型机器学习模型(回归、分类、聚类)适用性、优缺点非常熟悉;
3.快速明确输入/输出的能力,有哪些数据可以作为输入训练模型,输出的数据是什么?
2.数据清洗与特征工程
拿到数据通常是不干净的,比如大量的缺失值、异常值,以及不规范的数据,都需要进行加工和清洗。
比如异常值的筛除,缺失值的补足,以及数据的归一化处理,这些是为了机器更容易理解数据、提升结果的精确性。
有了比较干净的数据之后,就要对数据进行采样和数据集划分(分为训练集和测试集)。这个时候需要根据业务理解、简单的数据分析以及可视化来帮助采样,去除不合适的样本。
数据和特征工程决定了机器学习的上限,能发挥原始数据的最大效力,往往能够使得算法的效果和性能得到显著的提升,优秀的特征工程能使简单的模型发挥出比复杂的模型更好的效果。
好的特征来源于对业务的深入理解,首先自己要深入理解业务的运作方式,了解影响模型目标的主要业务因素。
其次掌握有效的分析方法也是必须的,比如相关系数、卡方检验、平均互信息、条件熵、后验概率等等。
总结起来,这个部分所需的技能如下:
1.Python基本库(Numpy/Pandas等)的用法,这是数据处理和预分析必备技能;
2.掌握数据采样方法(如bootstrap),掌握基本的数学知识(如各种分布、向量和矩阵等);
3.特征选择方法(Filter/Wrapper等)及分析方法(相关系数、平均互信息、条件熵等)。
4.数据降维方法(PCA/LDA)以及多个特征的融合。
3.模型选择与训练
训练模型之前,要选择一个适合解决我们定义的问题的算法,这就需要我们对主流的算法模型有一个比较深入的了解。
某种算法适合解决什么样的问题,适合什么样(类型/规模)的数据集,性能和效率上如何做取舍,这些都是需要考虑的问题。
开始的时候,我们应该尽量选择一些简单、工业界常用的算法,例如线性回归、逻辑回归、树模型等。
在通过这些简单的模型应用达到一定的效果,或者在其他方面也遇到困难的时候,考虑换一些更复杂的算法,比如神经网络深度学习。
初步选择算法之后,我们的数据就可以喂给算法进行训练了,这也是机器真正进行学习的过程。
对于模型的结果,我们还需要选择合适的指标进行评估,当然这个需要结合自己的业务目标选择适合的评估度量方式。
这个部分需要掌握的技能总结如下:
1.具备基本的数学基础,比如向量与矩阵、各种概率分布、微分与导数的知识等,学习算法必备;
2.熟悉主流算法模型(线性回归/逻辑回归/GBDT/SVM/KNN/K-Means等),适用性及优缺点;
3.掌握模型的调用及训练方法,主要是Python编程以及Sklearn库(或深度学习框架)的使用;
4.了解基本的模型评估度量指标,比如MAP、MAPE、MSE。
4.模型调优与应用
模型优化是一个非常繁杂但又异常重要的步骤,往往为了一点细节的提升,需要付出巨大的努力。通常可以进行模型调参、特征优化、模型融合(集成学习)等多种优化方式的尝试。
调参经常被调侃为“老中医看病”,貌似无据可寻,但对算法原理及公式推导的深入理解,往往能够帮助你更快找到合适的参数,减少不必要的试错。
当然,经验也很重要,可以参考其他优秀工程师的调参经验,网上也有很多分享。
做更深入的特征工程通常是有必要的,比如出现高方差的情况,可以尝试减少特征的数量;比如出现高偏差的情况,可以尝试获取更多的特征或者增加多项式特征。当然,扩展训练集或者正则化的方法,也是可以尝试的方向。
融合多个模型的集成学习,已经被验证是一种有效且可行的方式(实用性强且流程标准)。
在做一个模型的结果优化达到瓶颈之后,可以尝试训练多个模型进行融合,通常会取得一定程度的提升。
总结一下,这个部分需要掌握的技能如下:
1.对算法模型原理、推导的深入,了解各种参数的定义及可能产生的影响;
2.特征优化的方法、正则化的方法,快速定位优化方向的能力;
3.掌握集成学习方法(Boosting/Stacking等),能对多个模型进行融合。
掌握技能框架,高效学习
所以你看,机器学习听起来很复杂,但按照实际的流程拆开来看,也不过如此。基于上述工作流程,我们可以总结,要完成这些工作,需要具备的技能点如下:
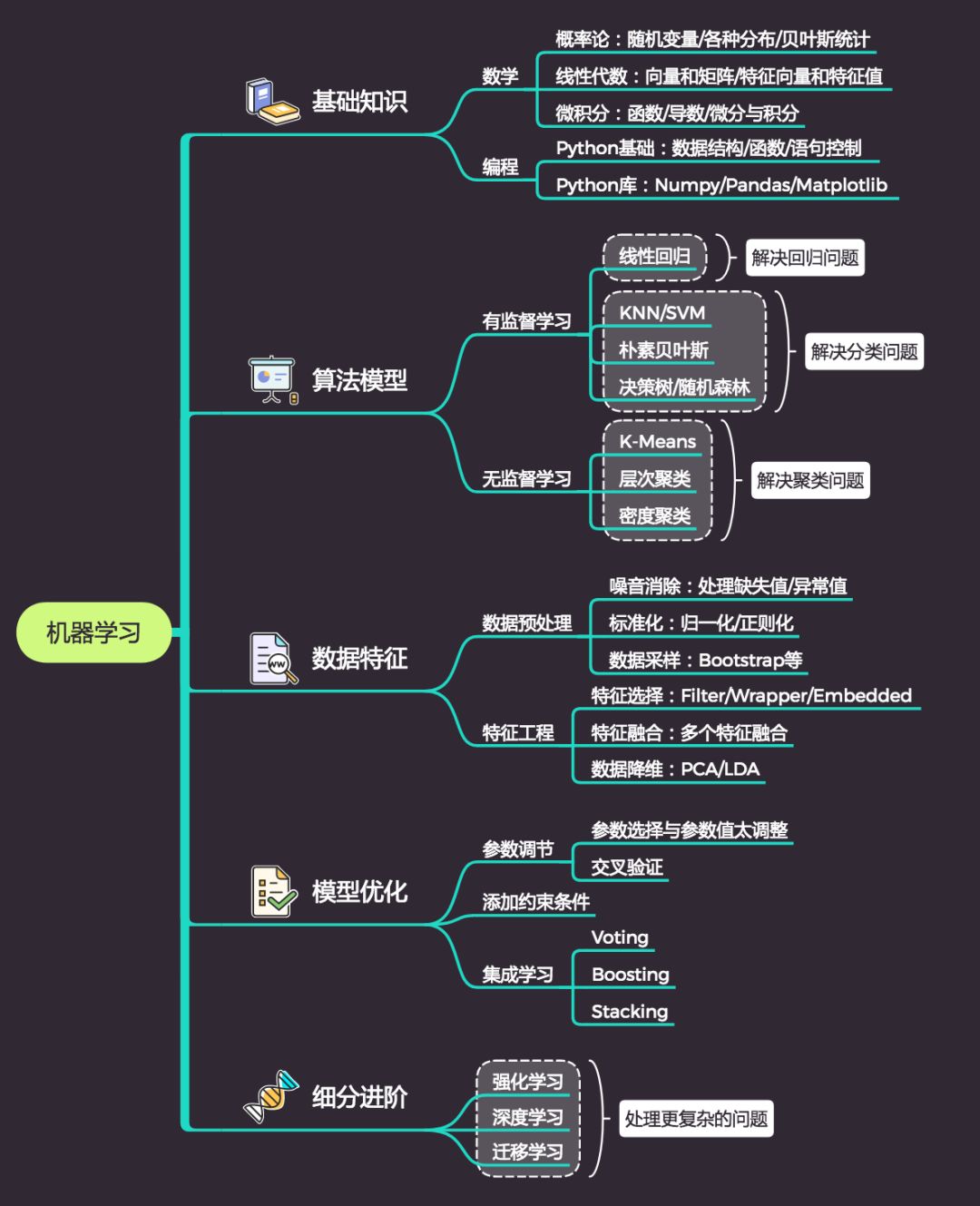
而最有效的学习方式也就是掌握这个框架,按照实际的工作流程,通过解决具体的问题,来实现技能的提升。这样每学习一个部分,你都知道是要去解决哪些问题,并能够在实际的问题中进行应用。
所以我们基于这个框架和流程,设计了一门非常体系的课程。通过平滑的路径,以及清晰的学习框架,短时间内你就可以实现自己的机器学习应用,打败绝大部分所谓的“调包侠”。

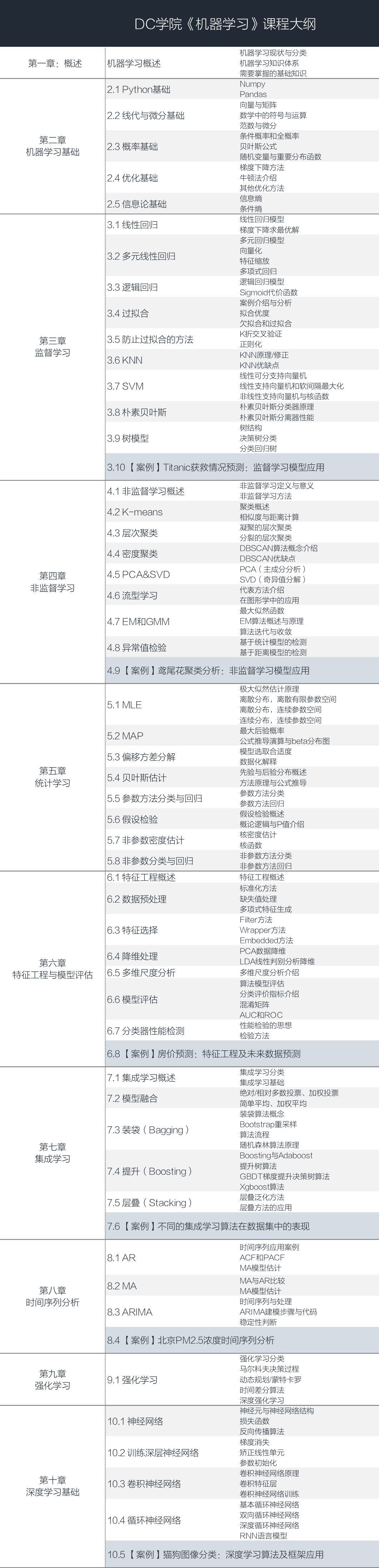
学习框架
课程按照机器学习项目的流程进行路径规划,你可以掌握机器学习技术中最为核心的算法模型、特征工程、模型优化(调参、集成学习)系统知识,同时在强化学习、深度学习、时间序列方面进行深度的延伸,为你打造一个全方位的技能体系。
同时,我们还补充了必备的数学基础(微积分、线性代数、概率统计、信息论、优化理论)和编程基础(Numpy/Pandas/Sklearn等库的使用),即便你基础薄弱,也可以顺利掌握。
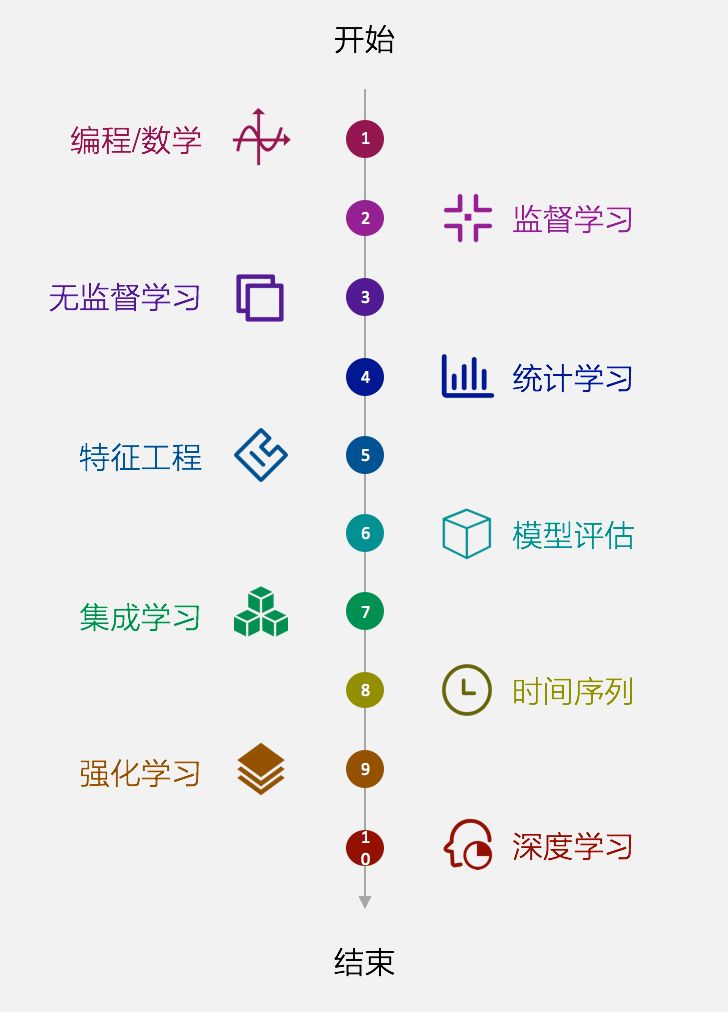
学习目标
只是用Sklearn调个包肯定不是正经讲机器学习,课程目标是让你知道原理,能解决实际工作问题。比如机器学习算法,课程中不仅会讲如何应用,更会深入原理和公式推导,理解其深刻的内涵。
机器学习岗位的工作大多是模型的训练及优化,而课程将会主要在这方面深入。调参、特征工程、集成学习、强化学习等方法都是形成你核心竞争力的关键。
所以我们的目标不仅仅是会用,而是如何去实现优秀的机器学习模型。
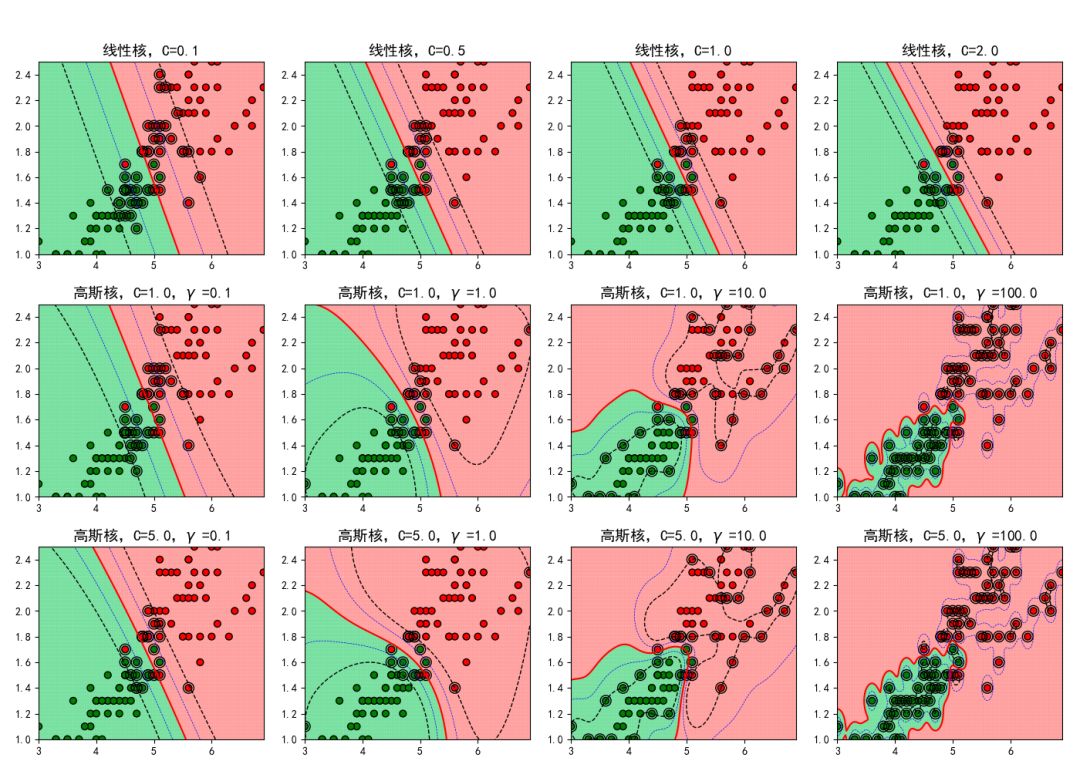
课程案例
除了每个算法后附带的针对性实践案例,每章都设置了体系完整的实战项目,让你学习具体的知识点的同时,熟悉机器学习的基本套路。
具体的案例老师都会详细讲解,细化到每一个操作,案例的思路、实现过程以及全部的代码我们都会分享出来,通过jupyter notebook的形式,下载后你可以直接在你本地的环境中运行。
课程中将包含但不限于以下案例/项目:
课程资料
你已经收集了数G的资料从未打开?我们要做的是节约筛选有效信息的时间,课程资料已经帮你找到最有用的那部分,你可以把更多的时间用来做更多的练习和实践。主要包含四个部分:
课程中重要知识点,资料中会进行详细阐述,帮助理解和复习;
默认你是个小白,补充所有基础知识,比如数学/编程知识;
课程中老师的参考代码打包,让你有能力去复现案例;
提供超多延伸资料和更多问题的思路和实践代码。
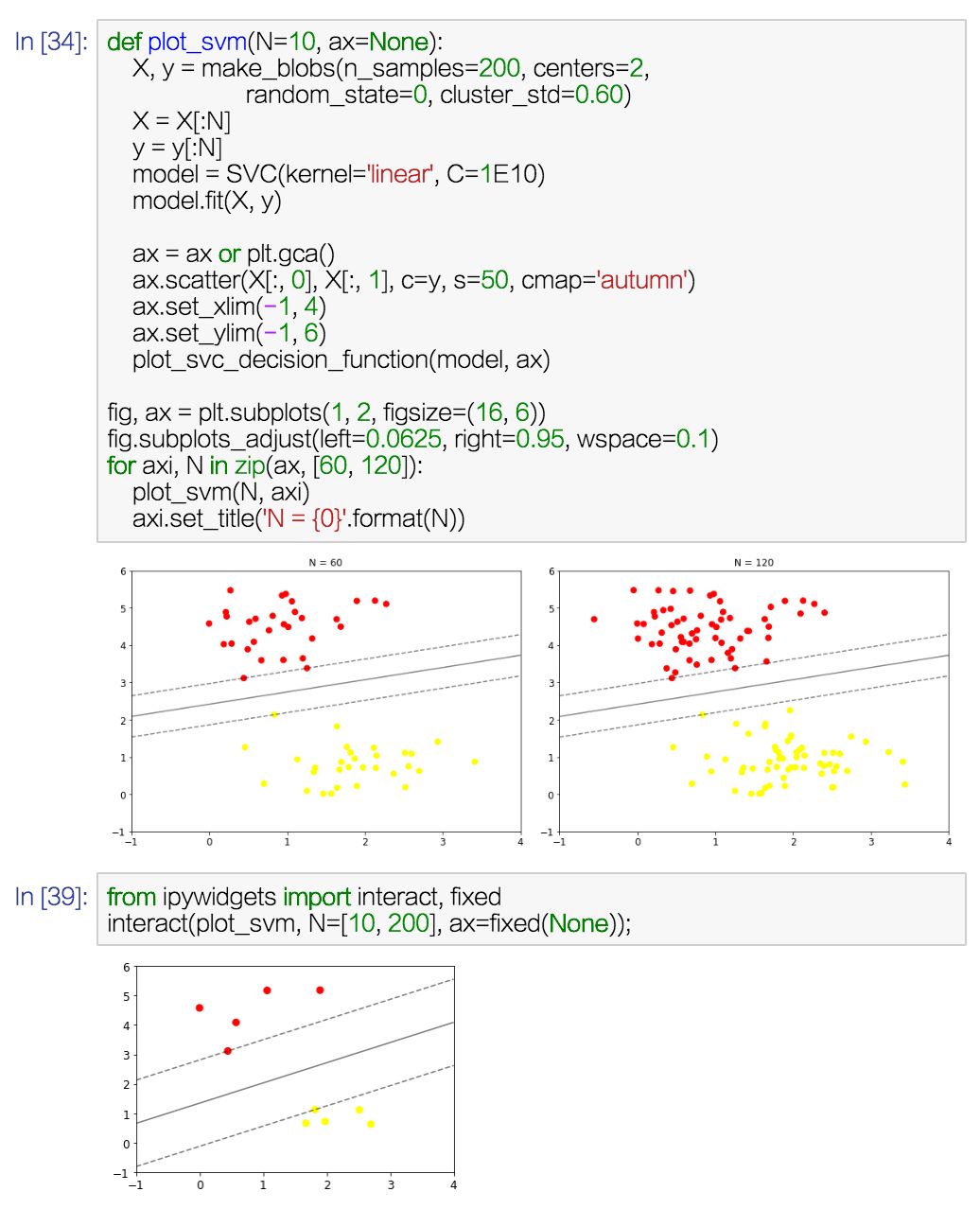
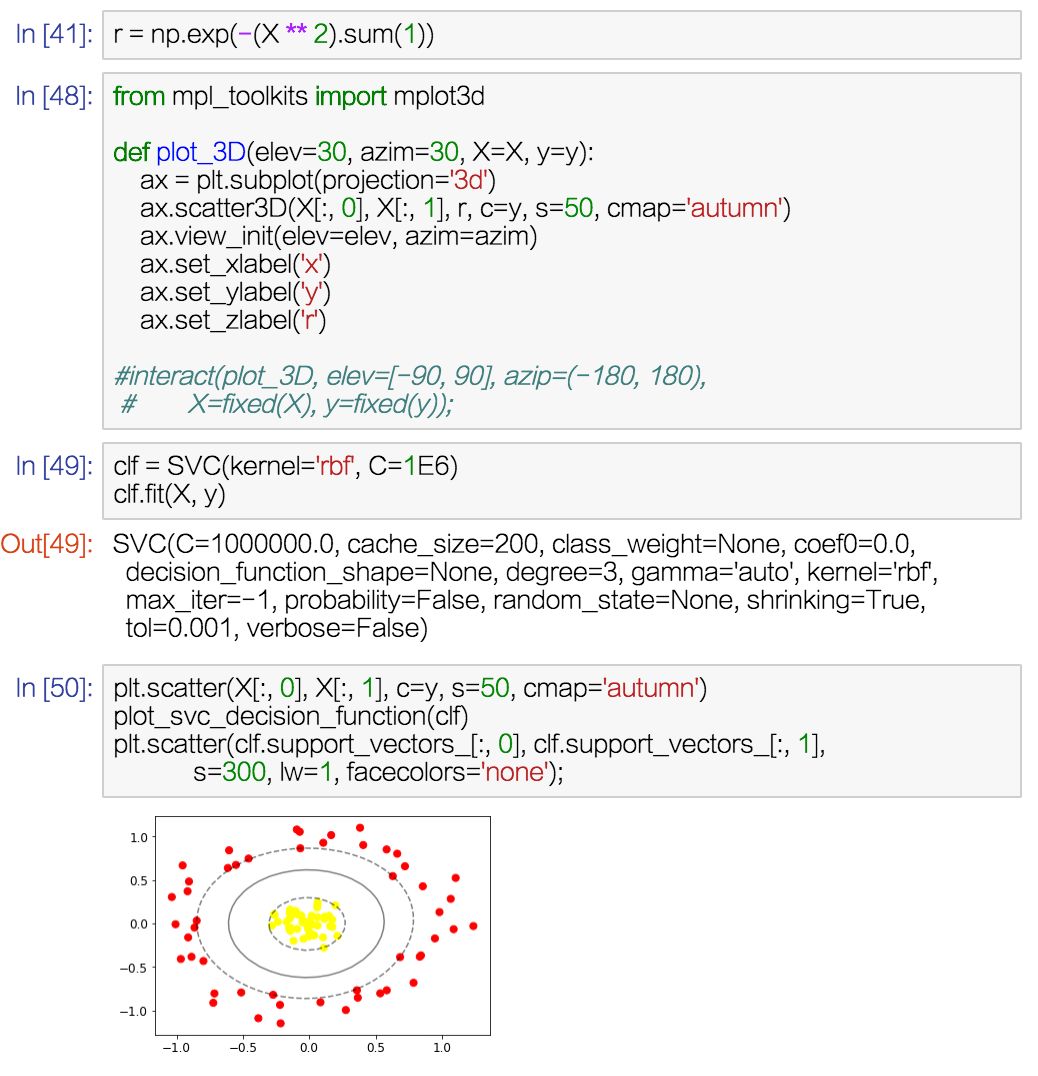
某节部分课程资料
课程答疑
在学习群里,你的问题能够得到快速解答(助教老师实时答疑),即便是最初级的问题。还有一群未来的优秀攻城狮,跟你一起,探索机器学习技术。在短时间内,有不少同学都有了从0到1的进步,能够训练自己的模型。

【课程信息】
「 上课形式 」
录播课程,可随时开始,反复观看
「 课时信息 」
60+课时,每课时20-60分钟,讲懂为止
(课程已更新4章,一个月左右更新完毕)
「 学习路径 」
数学基础-算法模型-特征工程-集成学习-深度学习
「 编程语言 」
人生苦短,用Python3.6,不解释
「 所需基础 」
具备基础数学知识,对导数/微分/向量/矩阵有所了解
「 答疑形式 」
学习群老师随时答疑,即便是最初级的问题
「 课程资料 」
重点笔记、操作详解、参考代码、课后拓展
限额底价:¥599(原价899),限前100名
长按下方二维码,了解详情&名额预定

咨询、资料领取、免费试听,请加下方微信群
若群满,加Alice小姐姐微信:datacastle2017

你以为你是在看课程
其实是在看未来的自己
▼点击下方“阅读原文”也可以加入课程哦




