蒙特利尔大学刘邦:基于图学习的热点挖掘与兴趣点建模

分享嘉宾:刘邦博士 蒙特利尔大学
编辑整理:吴祺尧 加州大学
出品平台:DataFunTalk
导读:自然语言处理在现实生活中存在于各种应用中,比如百度、谷歌、雅虎等搜索引擎,以及智能家居的智能助手,虚拟的偶像角色如微软小冰、小米小爱、百度小度。社交网络中如微博、知乎、抖音也会涉及到短文本或者长文本的自然语言分析以及tag聚合等。在自然语言处理中,有两个核心问题:以何种形式表示文本;基于某种形式我们应该如何建模与计算。我们认为图神经网络是这个领域下一个发展方向,因为自然语言是一种具有组合性以及层级结构的事物。今天分享的题目是基于图学习的热点挖掘与兴趣点建模。这些工作是阿尔伯塔大学团队以及腾讯QQ浏览器团队一起合作完成的。
今天的介绍会围绕下面三点展开:
自然语言处理背景介绍
Story Forest: Hot Events Discovery and Tracking
GIANT: Ontology Creation and User Interest Modeling
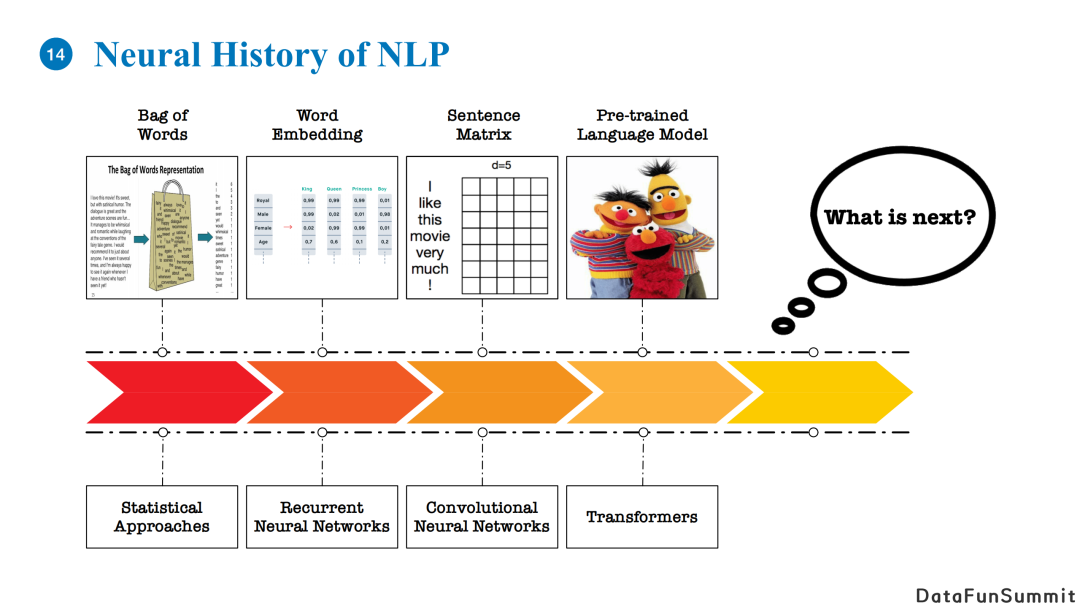
首先和大家分享下自然语言处理的背景。
自然语言处理领域最早对文本的表示方式是bag of words。对于一段文本,我们将它视为一个词的集合。在这种情况下,我们不考虑词与词之间的联系,如顺序结构等,对应计算模型是基于统计的方法。这类方法相当于把每个词当成独立的case,失去了词与词之间的内在联系。
之后,自然语言处理领域提出了基于词向量的表示。如果使用one-hot encoding,假如我们存在一个两万个单词的字典,我们就是要一个两万维的向量表示它。而使用词向量的话我们可以用低维向量(200或者300维)来表达语义信息,这样我们可以使用词向量对两个词计算相似度,且相似的词其相似度会较大。常用的模型有Recurrent Neural Network(RNN)以及Long Short Term Memory(LSTM)。
还有一些工作会把一句句子的词向量垒起来,将其看作一个矩阵。其中,每一个词向量本身是一个维度,句子中每个单词又是另一个维度。通过这种方法,我们可以应用CV领域的卷积神经网络的方法。当然,在自然语言处理领域,我们借鉴了CV的思路,但是针对文本是使用一维的卷积神经网络进行处理,并且按照单词的顺序从左到右进行卷积。
目前比较流行的方法是使用大规模预训练模型做自然语言处理任务。我们会利用堆叠的transformer模型进行建模。这种做法学习出的词向量的特点是每一个单词的表示与上下文相关。比如一个词如果使用固定的词向量进行表示,那么同一个单词出现在不同的句子里就无法表达变化的语义,典型例子就是苹果公司和水果苹果。正是因为同一个词在不同语境下的语义差别,所以我们需要构建一个基于上下文的词向量表达。在最早的BERT被提出之后衍生了很多大家熟知的预训练模型,这里就不一一列举了。
纵览自然语言处理的发展历程,从bag of words到大规模预训练语言模型,下一个能够进一步带给这个领域更多进步的模型应该是什么?我们认为是基于图结构的表达和基于图神经网络的建模。Transformer是对文本进行建模,而GNN可以在此基础之上引入先验的图结构。通过GNN我们可以利用先验知识来建模对应图结构,从而弥补毫无先验信息的文本表达方式。
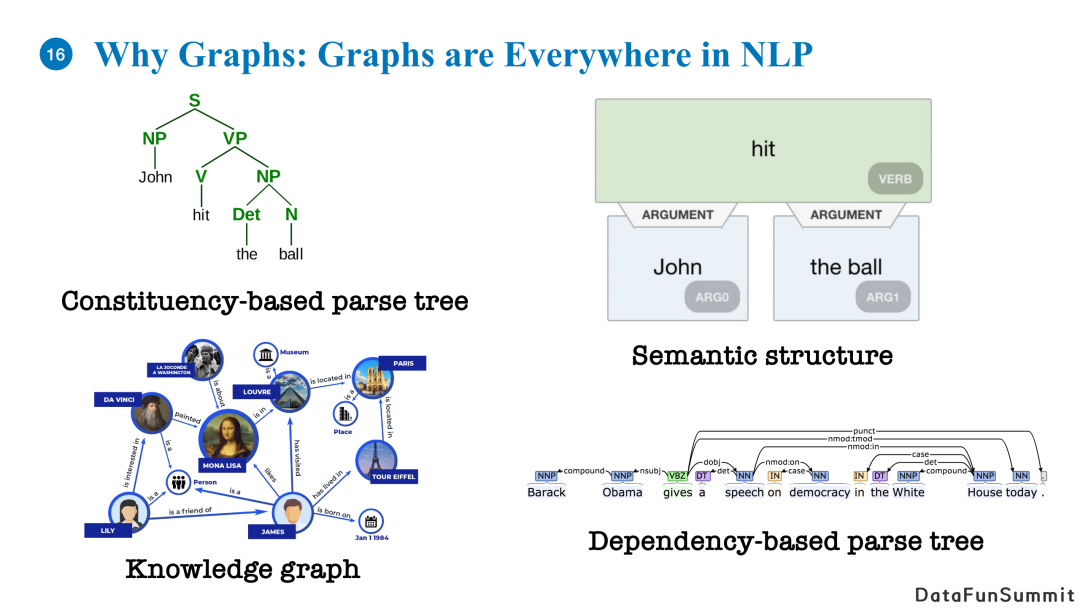
自然语言处理领域其实存在很多图结构,比如语法书、语义图、知识图谱等。从语言本身来说,自然语言是一种非常灵活的、具有可组合性的以及具有层级结构的事物,也就是说一句话的完整语义是可以被不同层级的多个细粒度语义组成的。例如一个相同语义的主动句和被动句,如果我们以一种图的方式来表达它们的话,我们会发现它们的语义层级结构其实是相同的,即使它们的顺序结构存在差异。也就是说图结构能够表达出自然语言的灵活组合性以及层级结构。
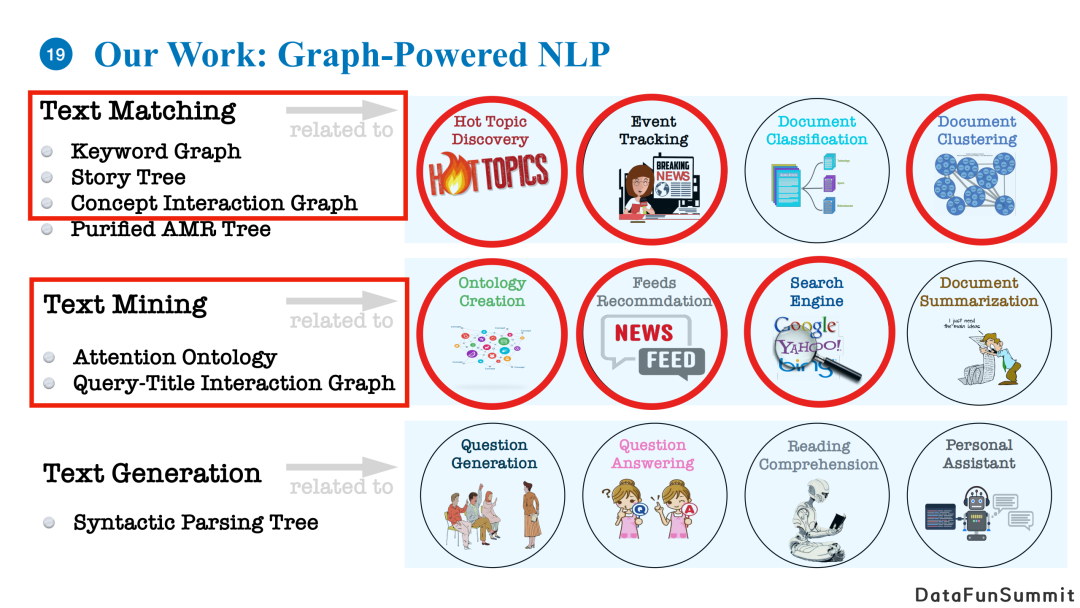
我们之前的工作覆盖了NLP领域内不同的任务,包括文本匹配、文本挖掘和文本生成,并且将它们应用到了一些列不同的应用中。我们今天分享的应用主要是基于图结构进行建模,并将其使用在文本匹配进行热点事件的挖掘和分析,细粒度文本的聚类,以及通过对用户兴趣点的建模来提高信息流的推荐搜索。
我们首先分享story forest系统。这个系统主要是应用于热点事件的挖掘。

在当今时代,我们每天可以从不同渠道接触很多信息。在这么多纷繁复杂的信息中,我们很难快速地获取自己最关心的一类信息。比较传统的做法是在搜索引擎中输入自己感兴趣的事情作为query,得到一些高分的返回结果,或者我们会受到主动的推荐。
但这种做法有一些缺陷。首先,你所得到的文章列表中,文章之间不存在有意义的结构。另外,每个文章刻画的信息是十分细粒度的,文章与文章之间存在重复信息,即对于同一件事情,不同的媒体报道的内容大部分是重合的,这样就形成了信息的冗余。反之,如果两个新闻之间是关于同一个话题的,但是它们的冗余度比较少,你其实并不知道它们之间的关系是什么样的。
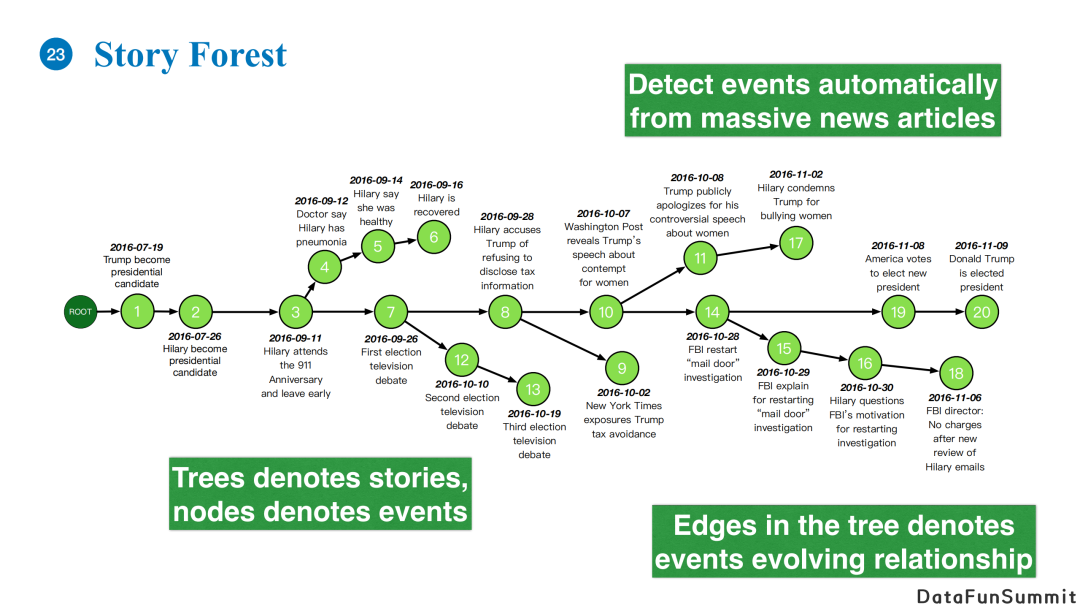
我们提出的story forest系统想利用图结构有效地组织信息,减少它们之间的冗余,并且理清它们之间的发展关系。例如上图的例子,针对2016年美国大选,我们可以把相关事件整理成一个story,每个绿色节点代表一个事件。我们认为一个事件是发生在某一个时间点,包含一群人或者一些实体的一个事情。Story中会包含一些分支,如上图希拉里的健康门,三次电视大选,希拉里的邮件门等。通过一个树形结构,我们能够纵览故事的全局发展,并且追踪其中的某一些分支。每一个节点把关于同一个事件的所有报道都聚类其中,不同事件之间具有相关性,我们可以根据时间点的发展以及事件之间的紧密程度构建如上图所示的树结构。
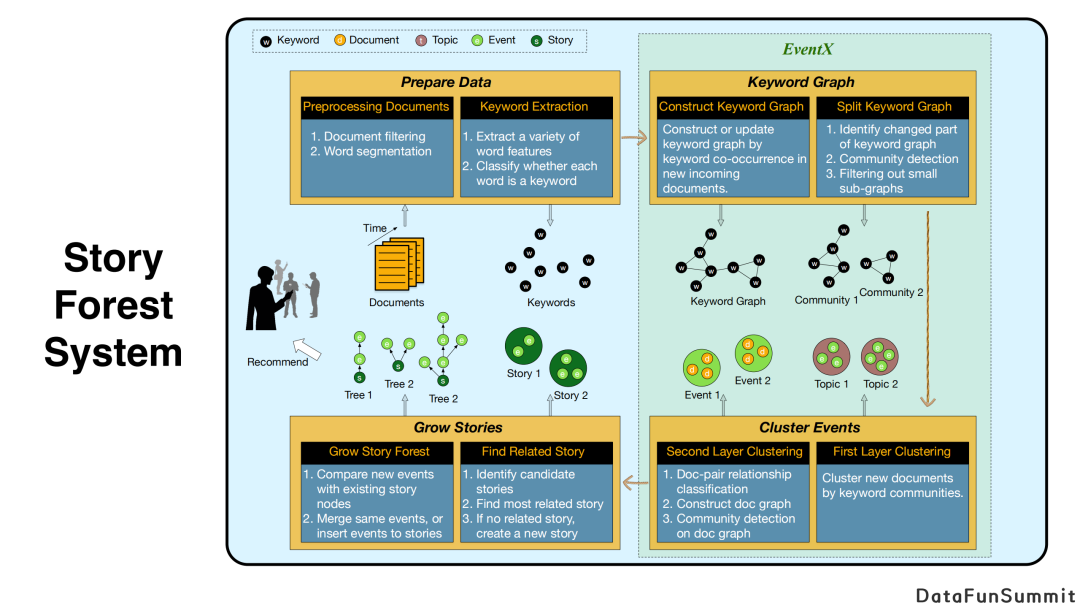
上图展示了story forest系统的总体架构。
首先,第一个模块是预处理,里面包括文本的聚类、文本的过滤、切词、提取关键字等。
接下来最核心的问题是如何对文章进行“事件”粒度的聚类。此前传统方法大部分是对文章进行话题聚类,而我们的目标是将每一个聚类中所有文章所阐述的核心点是围绕同一个事件,其在语义层面是相较于话题来说更为细粒度的。我们在这里提出了EventX基于图结构的双层聚类算法。首先我们会根据关键词的贡献程度建立关键词图,图中每个节点都是一个关键词,节点之间的边代表了关键词的共现次数超过了一定阈值。其次,我们对关键词图使用社区发现算法分割成多个子图,每个子图对应一个话题。
接下来,我们将所有文章按照它们与每一个keyword community的相似度分配到不同的类中,这样就相当于对文章完成了粗粒度的聚类。在下一阶段,我们复用这种算法,将文章当成图中的一个节点,判断两篇文章是不是属于同一个事件,进而形成一个文章图(document graph),并进行第二次社区发现算法,最终将文章分为多个document community。经过以上算法,每个document community描述了同一个事件。
系统的最后,上述结果会输入story模块中,判断事件是否可以插入已有的story树中,或者生成一颗新树。
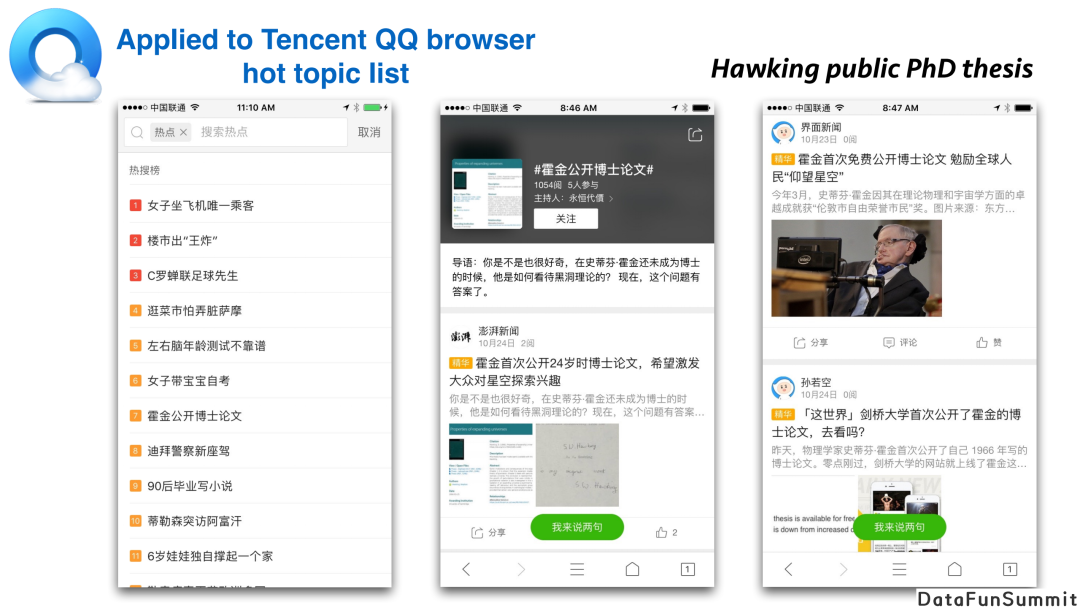
story系统被部署在早期腾讯QQ浏览器的热点话题列表中。在浏览器里,如果你去看热点新闻,每个小时它会更新热点事件列表。对于其中每一个topic,里面包含了所有不同媒体的报道。通过这个做法,用户不需要阅读多篇关于同一个topic的报道,而是可以选择一两篇进行浏览。而热点时间线不仅报道了事件的最新进展,还包含了事件的前序脉络,构成了一个完整的story。
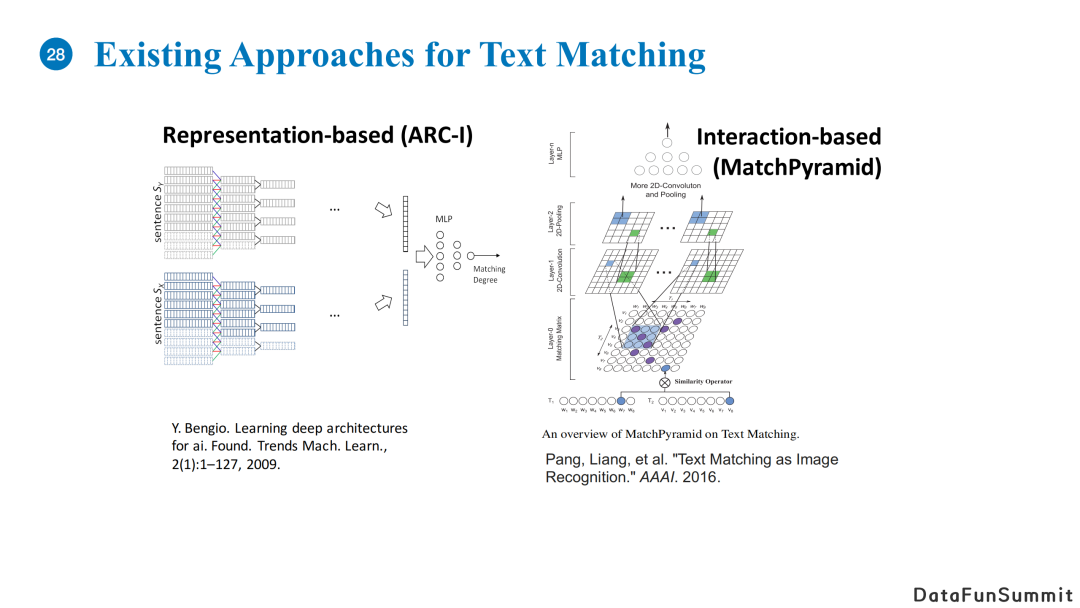
我们刚刚提到的算法流程中需要判断两个文章之间的关系,比如两篇新闻是否在报道同一个事件。这实际上是一个长文本匹配任务,在学术界较少被涉及。
之前文本匹配有两类思想:
基于表示的模型,核心在于设计一个编码器,对于两个输入文本,我们使用编码器得到隐向量表示,进而计算它们之间的匹配度;
基于交互的模型,核心在于通过两句句子每个单词之间的相关性得到相似度矩阵,其类似于一个图片,随后我们可以利用卷积神经网络去计算两句句子的综合相似度。
但是这两类方法对于长文本匹配不适用。首先,对于长文本,模型很难精准地取编码语义信息;第二,如果将一个长文本其中一到两句话进行打乱,实际上对文本的整体语义影响不大,但是对于encoder来说这两种输入截然不同,最终得到的隐向量的差异就很大;第三,这两类方法的时间复杂度较高,例如基于交互的模型在计算相似度时是O(n^2)的复杂度,当文本长度较大时时间消耗就很大。
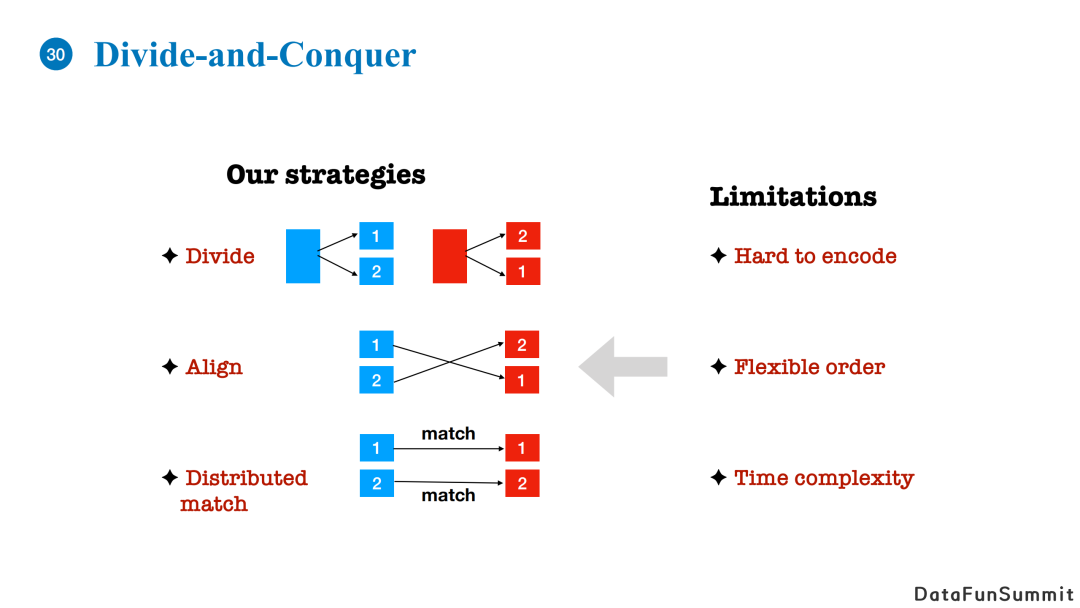
我们的做法是使用分而治之的思想。
首先,对于长文本,我们希望按照文章内容将其分为几个子topic。
其次,我们需要对齐两篇文章的内容。
第三步,我们需要做一个分布式的匹配,如果两篇文章中有多个不同的Topic对齐了,我们可以点对点的进行匹配,并通过聚合子topic的比较结果确定最终的相似度。
通过上述方法,我们就可以相应地解决长文本难以编码,顺序较为灵活以及时间复杂度高的问题。
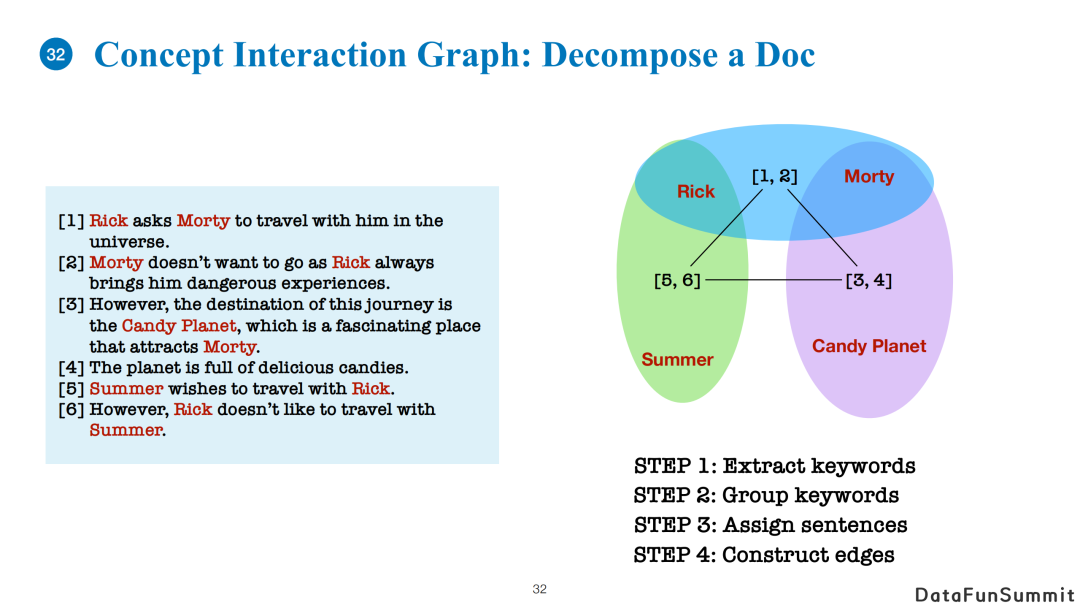
例如一篇文章有六句话。首先我们可以提取文章中所有关键词,并使用关键词构建概念交互图(Concept Interaction Graph)。具体地,我们会将关键词进行聚类(复用community detection的方法),当然分组的算法是可以自由选择的。然后,我们将一篇文章中的每一句话根据相似度分配至不同的关键词群中。最后,我们计算每一组关键词群和其他关键词群之间的相似度,根据计算结果建立带权重的边。
对于两篇文章A和B,构建概念交互图的流程是一致的,只是在分配关键词群的过程中,有些关键词群(即概念交互图中的一个节点)中既有来自文章A的句子又有来自文章B的句子。
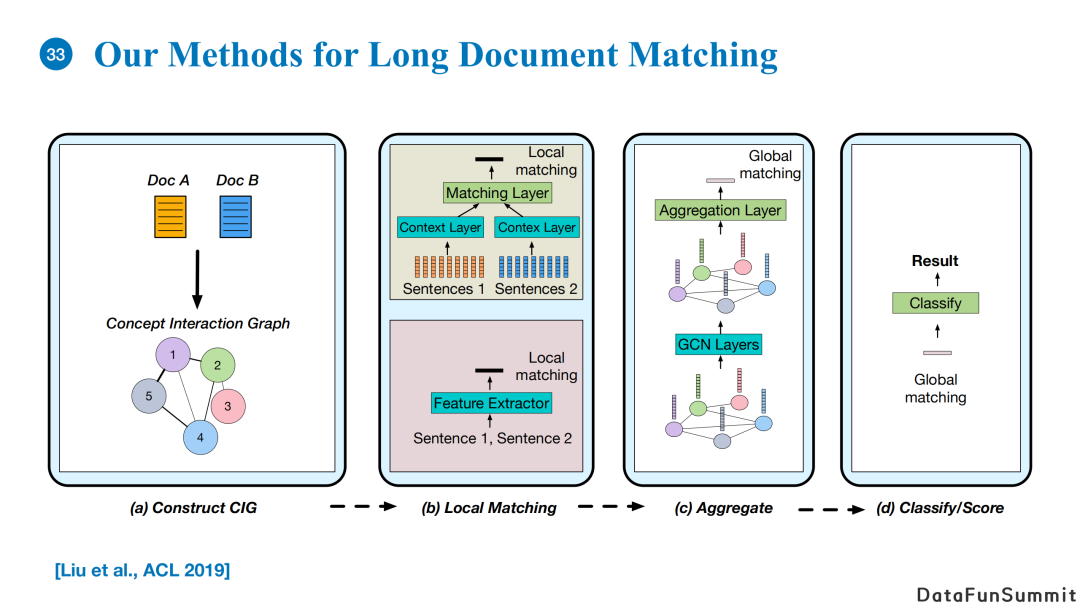
进行长文本匹配时,
首先我们会构建两篇文章的概念交互图。
第二步local matching,我们会对每一个节点中来自于两篇文章的句子进行文本匹配。这里的匹配算法可以复用传统的短文本匹配算法。
Local matching模块输出的向量代表着文章局部匹配的结果,我们可以利用这个结果使用GNN在概念交互图中进行消息传递与聚合(对节点向量进行mean/max pooling),得到global matching的结果。
最后,基于global matching的输出向量,我们可以做一个分类任务得到最终文本匹配结果。
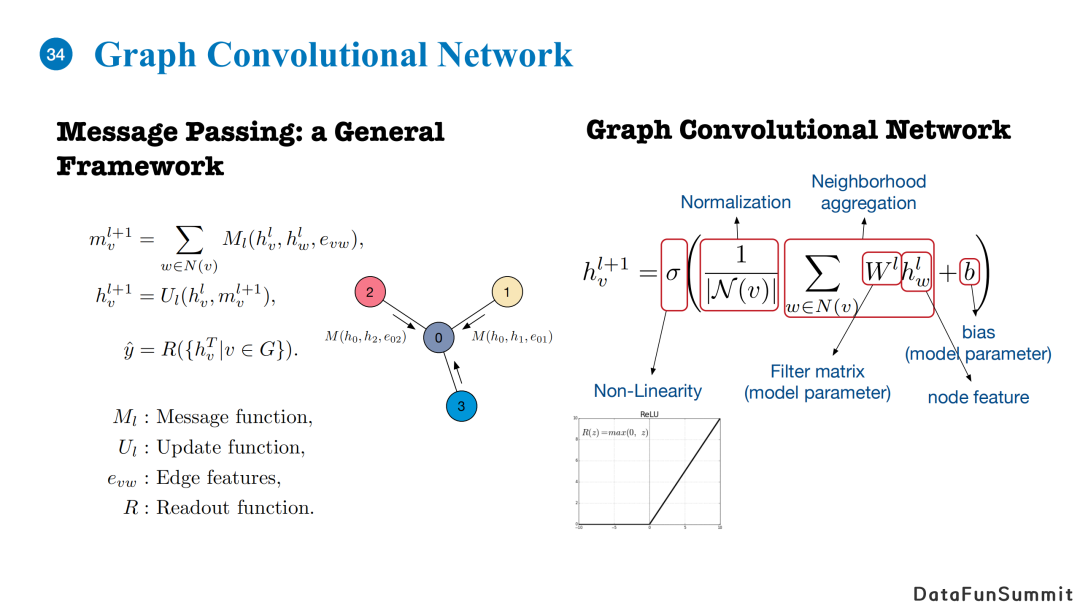
我们使用的图神经网络是Graph Convolutional Network,基于消息传递机制。对于每一个邻居节点,我们可以计算它相对于当前中心节点之间的消息(基于消息函数、两个节点的embedding以及边的embedding)。得到每个节点的当前层的隐向量表示和邻居的消息后,我们使用一个更新函数来更新当前节点的表达。最后,我们使用一个readout函数得到整个图的表达。
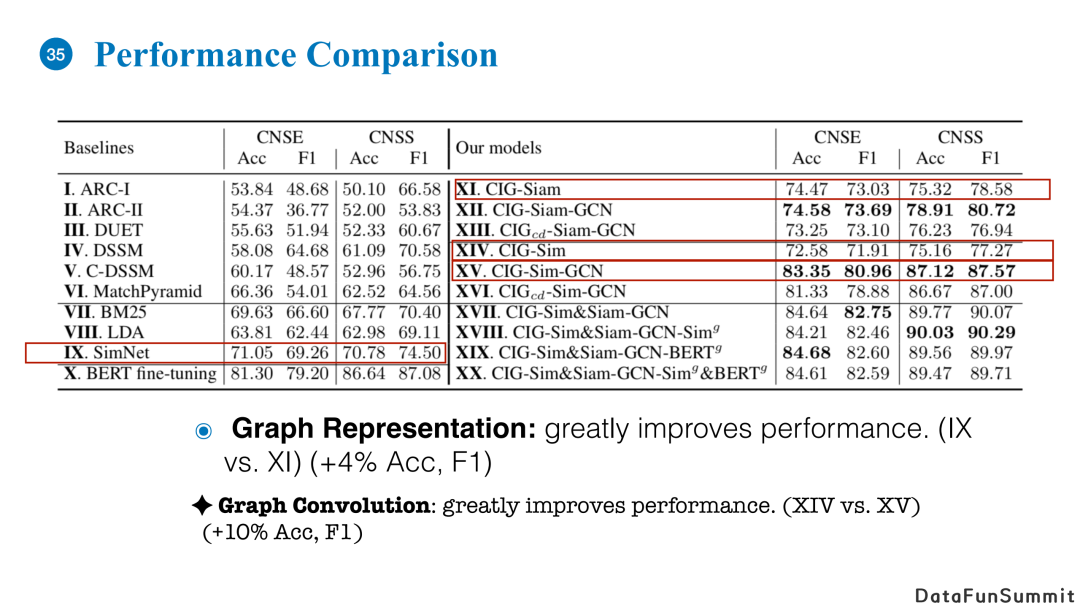
上图是我们在两个长文本数据上进行匹配的实验结果。右侧是我们的模型以及不同变种的效果,左侧是baseline。通过结果我们可以看到使用图的表示和建模的方法,匹配效果优于左侧baseline。
图中SimNet和CIG-siam的唯一区别在于CIG-Siam会将文章的内容分块。我们可以看到仅仅使用内容分解的操作,模型效果就远远超过不分解的匹配方式。
CIG-Siam和CIG-Siam-GCN的区别在于是否使用图卷积神经网络对local matching输出的向量进行聚合。前者使用的是简单的平均聚合,这里可以看到使用图结构和GCN进行聚合可以提升超过10%的精度。所以基于图的建模方式对提升模型效果有着举足轻重的作用。
接下来给大家介绍一下图结构在本体构建中的应用。


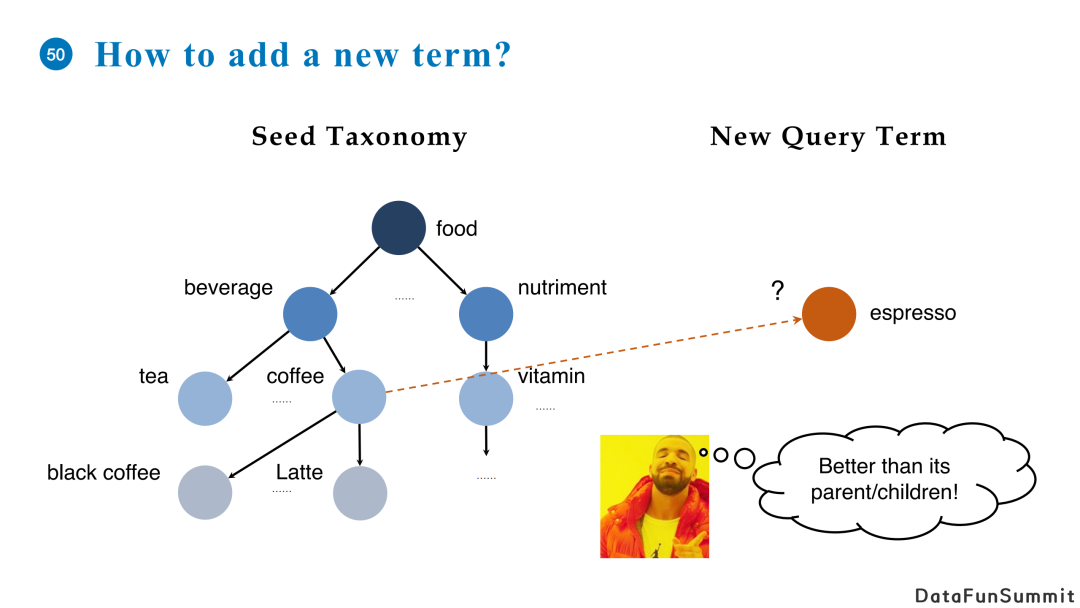
本体用于建模用户的兴趣点。如果一个用户在搜索引擎里的输入框中输入“特瑞莎梅的辞职演讲”,一个搜索引擎给他返回了关于特瑞莎梅的新闻或者特瑞莎梅的辞职演讲,很有可能用户并不感兴趣,或者之前已经观看了几篇类似的新闻。针对这个用户的兴趣点一个比较合理的猜想是推荐关于英国脱欧或者与之相关的事件。
如果想要达到这个效果,我们需要首先识别出“英国脱欧”是用户的一个兴趣点;其次我们需要知道英国脱欧和梅姨的辞职演讲存在上下位关系,即辞职演讲这一事件从属于英国脱欧这个大的话题。
用户感兴趣的有两类东西:
热点的事件,事件是现实生活中发生在人们周围的事情,包含了具体地人或者实体,并且发生在特定的时间空间等;
概念,它可以被定义为一个东西的集合,其中这个集合在某些方面存在共同点,比如两种比较经济实惠的车或者耗油较少的车。
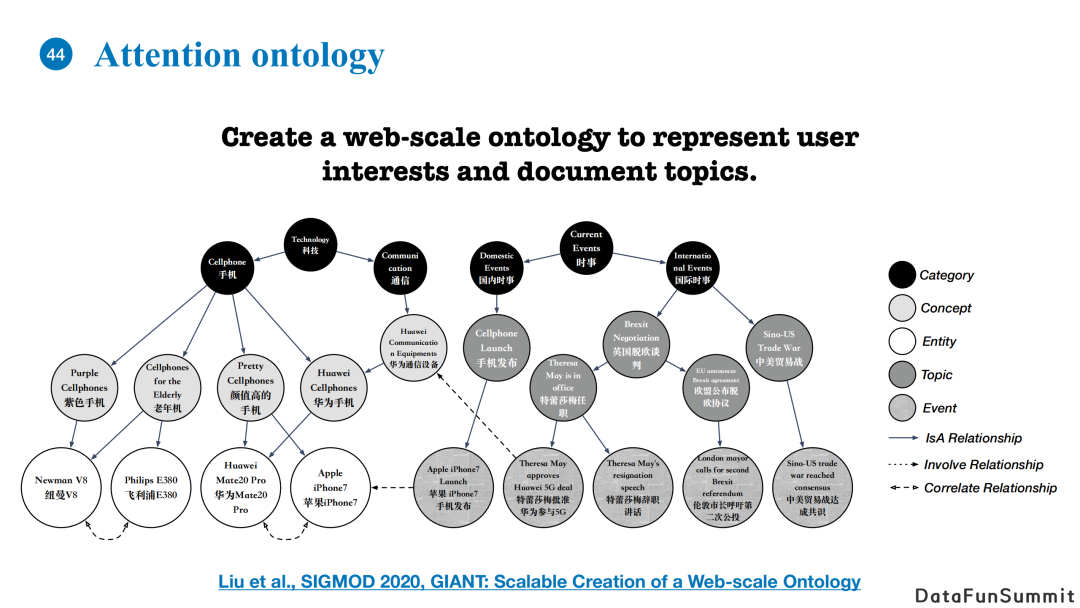
我们发表在SIGMOD 2020的工作主要是建立了一个本体,其利用大量的用户query和相应的点击文章去抽取不同用户的信息点,包括不同的话题短语、事件短语、概念短语、实体,以及人工定义的高层次类目(如科技、时事、手机等)。上图黑色的节点代表着category,即人工定义的类目,灰色节点代表挖掘的概念、事件、话题等,比如颜值高的手机、辞职演讲、欧盟公布脱欧协议等,还有各种实体(如各类手机等)。其中本体图中最主要的关系是上下位关系,它代表着节点之间的从属关系。
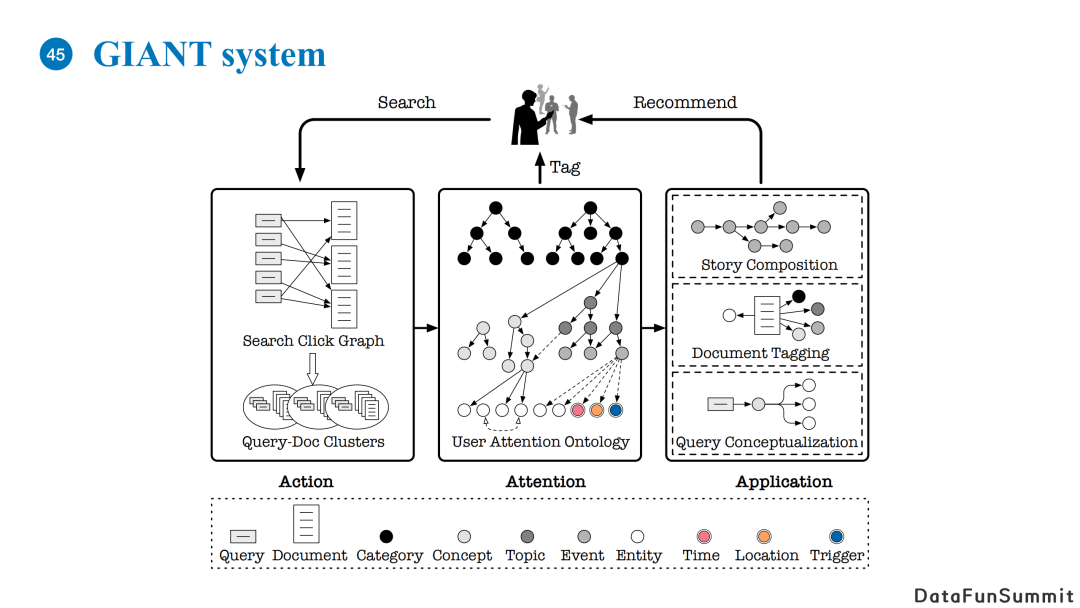
上图展示了创建本体图的GIANT系统的整体架构。
我们在使用应用时搜索、点击文章,或者输入query点击文章的行为可以被建模为一种图结构(Search Click Graph)。上图左侧的灰色矩形节点代表着query,白色矩形代表document。我们可以收集query的TopN点击的文章,构成一个二分图。在此基础之上,我们可以对二分图进行聚类,使得每一个类里包含少量非常相似的query和相关的document。我们在每一个query-doc聚类中可以抽出一个有意义的节点,代表着与这个类高相关的概念短语/事件短语。最后我们可以使用抽取出来的节点在已有的知识图谱或者本体图中寻找一个合适的位置并将其插入,最终构成一个新的本体图。
基于本体图,我们可以对用户的兴趣点做一个tagging。具体的,我们根据用户的浏览记录,来识别用户对哪些事件/概念比较感兴趣。我们也对文本内容进行了tagging,比如针对一篇长文本,我们会为它打上适合的标签。此外,我们还可以对用户的query做概念化,并以此为依据对文章进行筛选。我们对query可以做扩展,使系统可以推荐其他具有类似功能的产品。

这里的核心问题在于如何从query-doc聚类中抽取出不同信息点的短语。例如上图的库组,我们可以抽取出“宫崎骏的动画电影”这一概念。我们经过分析得出短语作为关键信息点的特点:
短语在不同的query和title中呈现一种相似的pattern;
短语出现次数较多;
往往可以使用NER计数来将它们抽取出来(大部分情况下是名字或者形容词);
短语很多情况下是以连续“块”的形式出现的;
短语的语法关系一般来说是固定不变的。
基于以上特点,我们设计了一种图结构来使关键信息点的短语特点被充分放大,进而更有效地对它们进行建模。
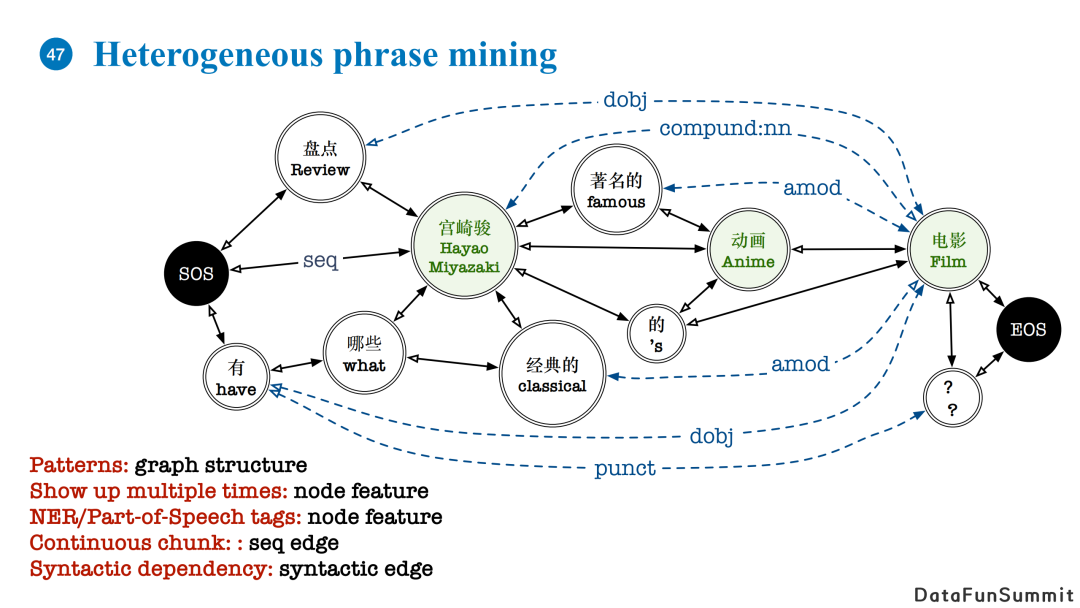
我们的做法是对于每个query或者文章标题,首先加入两个虚拟节点SOS和EOS。随后我们开始建图,图中的节点代表唯一的一个词语,这个词语可以出现在多个query和标题中。如果两个词语在一句话中位置相近,那我们在它们之间加入seq边;如果两个词在句子中位置不相近但存在语法依赖关系,那我们会在词语之间加入代表语法依赖的边。
通过这种构图方式,句子的pattern可以被转化为图结构,而一个词语多次出现的特征以及NER特征可以被建模为节点的feature。连续的关键词块可以被seq边关系表达,语法依赖则可以被语法关系表达。
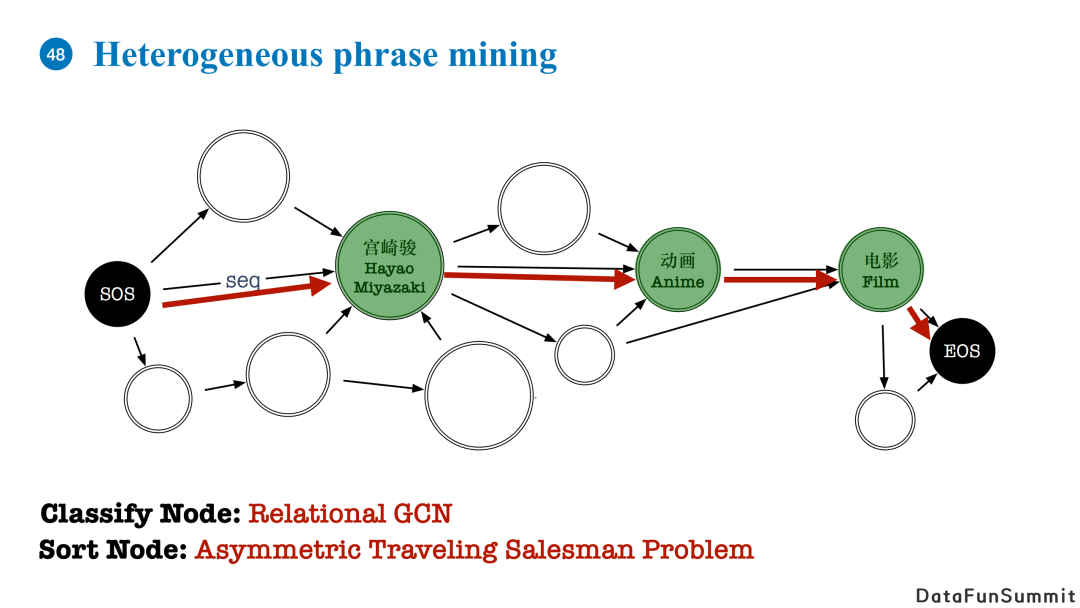
有了这种图结构的输入,我们的任务就是从图中抽出代表关键信息的短语,这相当于两个子任务:
首先,我们需要分辨哪些词可以作为图的关键概念信息,对应的是节点分类问题,我们使用了Relational GCN来解决,Relational GCN相较于普通GCN增加了对边关系的建模参数,聚合时分别对不同关系的消息进行传递计算;
第二,我们需要对抽取的词语做排列,形成一个短语而不是词的集合,我们将其转化为非对称最短旅行商问题,即我们需要从SOS出发EOS结束的路线中找到一条长度最短且经过所有被Relational GCN分类为正的路线。这个问题有现成的算法可以直接使用。
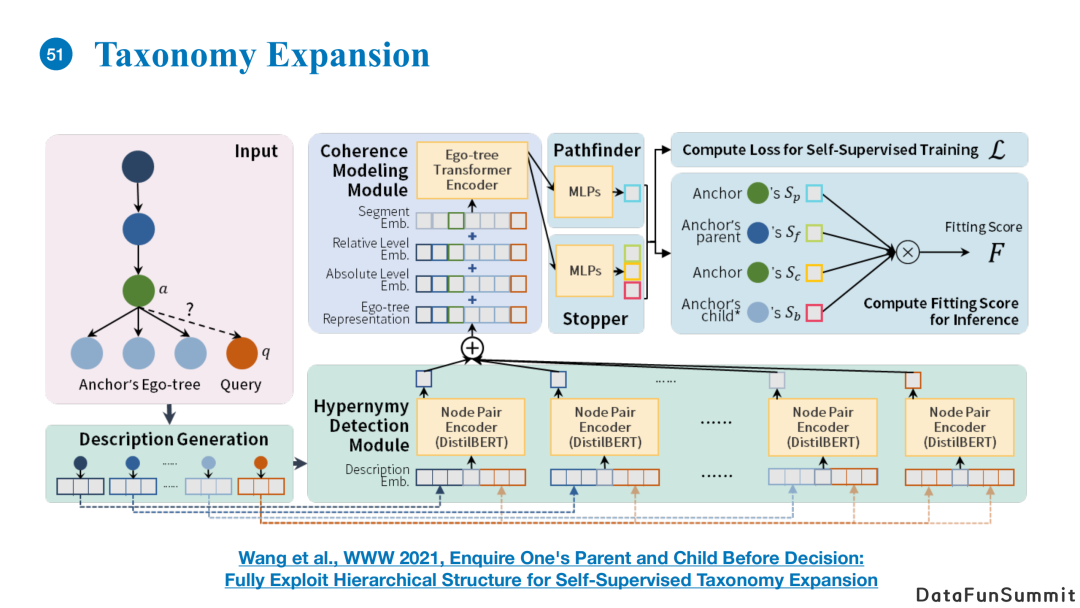
另外一个问题是如何将新的query词语插入至现有的本体结构中。我们在今年WWW2021会议中发表的工作重点探讨了这一问题,这里我只简要描述一下其中的概念。
首先,以前的方法在将新的节点插入已有的知识图谱或者本体结构时主要判断待插入节点和目标节点的关系,并没有考虑兄弟节点和祖辈节点的关系。而我们的想法是认为插入是应该考虑待插入节点和目标节点的孩子之间是不是存在兄弟关系,以及它和目标节点的祖先之间是不是也存在父子关系。这么做的理由是可以使得判断依据更加充分,使得待插入节点可以在图中找到一个适宜的深度进行插入。
其次,我们认为对于每个概念名词本身很难判断其具体语义。我们使用一句话去描述它的语义,例如使用WordNet中对概念的定义去扩增节点的语义描述。这么做相当于使用一句话代替名词本身,使得对语义的刻画更加精准。细节实现可以阅读我们的会议论文。

这里举个例子。比如上图左侧的文章,我们可以对它打一个tag叫做“油耗低的汽车”。这种tag一般在标题甚至内容里可以不出现,但是我们的系统可以判断出这篇文章是在讲述这一主题。这种功能可以应用在QQ浏览器、手机QQ、微信等新闻信息流推送中。
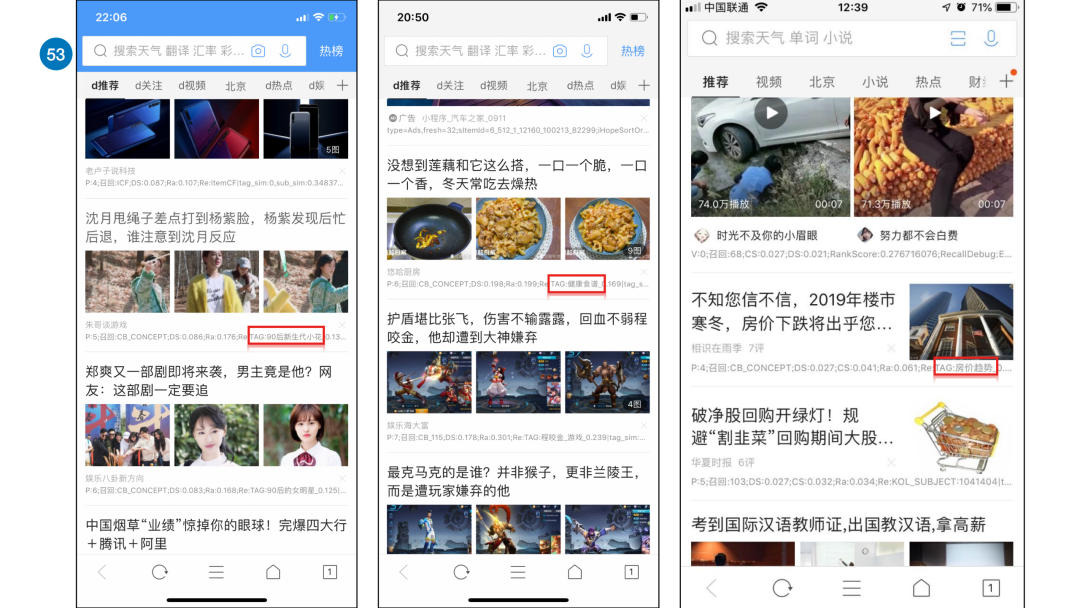
这里有更多的例子,比如上图最左侧“90后新生代小花”、中间的“健康食谱”以及右侧的“房价趋势”,可以看到这些tag并不存在于标题中,但是它们是以一种非常符合用户兴趣点的方式概括了文章的主要内容,使得其更加便于匹配用户的兴趣点,进而推荐更精准的文章。
Q:在topic模型比较火的时候,大家也曾经研究过story forecast问题。请问使用图模型解决这个问题的主要优势在哪里?
A:Story forecast的目标是预测事件的未来走向,它和过去的事件发展相关。如果我们可以对过去的事件进行脉络的梳理,而不是只基于当前发生的情况去预测未来事件,那么我们可以使用一个更全面、更结构化的表达来对历史事件进行建模。因为事件与事件之间不是一个单纯的马尔科夫关系,使用我们这种图结构相当于历史事件有不同的支线,它们都可能会影响未来事件的走势。
Q:提取关键词的有效方法有哪些?
A:现在有很多成熟的工具可以使用。比如清华大学刘知远老师的课题组开发了这类关系抽取的工具;哈工大也开源了命名实体识别的工具来识别中文关键词。我们的工作中使用的关键词提取方法实际上主要是抽取句子中的实体,然后基于热度等特征进行过滤。实际上,对于不同的应用场景来说,你可以根据需求去定义你的应用中的关键词,而不是使用同一个算法解决所有应用问题。
Q:请问分享中介绍的工作里使用的聚类算法和基于聚类的结果分析是一个端到端的过程吗?还是需要把聚类当成一个预处理的阶段来做?
A:在我们的工作中是分开处理的,相当于在storytree的过程中先得到事件节点,然后再将节点插入已有的树中或者与已有的节点进行融合。
Q:您觉得有没有可能将聚类算法以及对于聚类结果的处理做成一个端到端的形式?
A:目前我觉得是没有必要的。因为在实际应用中,新闻文章是实时推送的,即每时每刻都会不断的有新文章进入系统,所以很难做到端到端构建story tree。总的来说,这是一个不断增长、增量的构树过程,不适合使用端到端学习。
Q:Communitydetection的聚类算法与其他密度聚类算法相比有什么优势?
A:我们当初选择这个算法主要是因为它不需要预定义聚类的个数。社区发现算法的聚类依据依赖于不同节点之间的距离计算方式。传统的聚类算法的超参数是设置聚类个数N,而社区发现算法的关键是定义事件与事件之间的紧密度计算方法。这种“超参数”是更加稳定的,不会随着不同事件出现剧烈的变化。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“图学习” 就可以获取《图学习专知资料合集》专知下载链接





