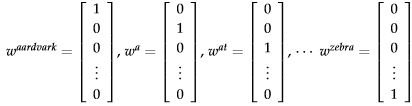
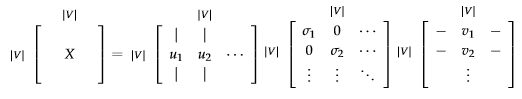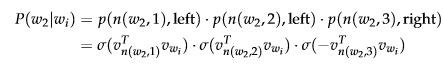Select the first k columns of U to get a k-dimensional word vectors.
indicates the amount of variance captured by the first k dimensions
使用svd
虽然思路很好,但是还有一些问题需要解决
However, count-based method make an efficient use of the statisticsSome solutions to exist to resolve some of the issues discussed above:---------上述问题的解决方法
Ignore function words such as "the", "he", "has", etc.---忽略功能词语
Apply a ramp window – i.e. weight the co-occurrence count based on distance between the words in the document.---采用加权方法
Use Pearson correlation and set negative counts to 0 instead of using just raw count.---采用皮尔逊相关系数(数据分析方法中有)
The dimensions of the matrix change very often (new words are added very frequently and corpus changes in size).---矩阵维度经常变化
The matrix is extremely sparse since most words do not co-occur.---矩阵太过稀疏
The matrix is very high dimensional in general (≈)----维度太高
Quadratic cost to train (i.e. to perform SVD)-----训练成本高
Requires the incorporation of some hacks on X to account for the drastic imbalance in word frequency
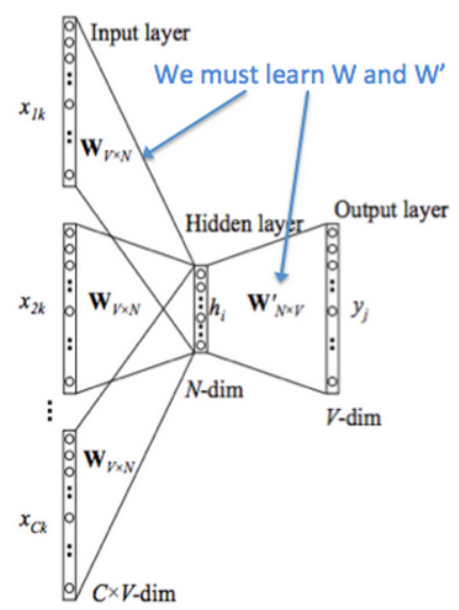
{"The", "cat", ’over", "the’, "puddle"} as a context and from these words, be able to predict or generate the center word "jumped". This type of model we call a Continuous Bag of Words (CBOW) Model. -----预测中心词语
We desire our probabilities generated, $ \hat
y} \in \mathbb{R}^{
y \in \mathbf{R}^{|V|}$, which also happens to be the one hot vector of the actual word.---就是希望均值能够和我们向量相匹配
损失和优化方法
上述式子中损失函数
但是y是one-hot向量,所以上面损失函数优化为:
对于概率分布,交叉熵很好的为我们提供了一个度量,所以优化函数为:
我们采用sgd来更新优化
其实我们主要更新的就是w和w‘,并且w代表的是词嵌入矩阵
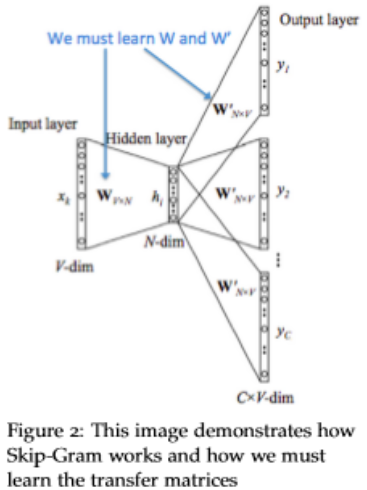
Skip-Gram Model
同一样,我们定义的参数和cbow一样
定义:
We generate our one hot input vector
of the center word. ---中心词识别
我们从上下文
得到输入入向量
生成分数向量
将分数向量转化为概率
注意
是每个上下词观寨到的概率
我们把我们生成的概率匹配真实概率
图示:
优化函数: 我们引用一个强力的朴素贝叶斯假设:In other words, given the center word, all output words are completely independent,输入向量时候,输出向量是完全独立的
Negative Sampling(负采样)
For every training step, instead of looping over the entire vocabulary, we can just sample several negative examples! We "sample" from a noise distribution (Pn(w)) whose probabilities match the ordering of the frequency of the vocabulary. -----对于每一个训练的时间步长,我们仅仅抽取一些负样本,并且跟新它们的目标函数,梯度,更新规则
目标函数优化:考虑一对中心词和上下文词 (w, c) 。这词对是来自训练集吗? 我们通过 表示 (w, c) 是来自语料库。相应地, 表示 (w, c) 不是来自语料库。对此我们采用sigmod建模
对于 Skip-Gram 模型,我们对给定中心词 c 来观祭的上下文单词 c-m+j 的新目标函数为
对 CBOW 模型,我们对给定上下文向量 来观察中心词 的新的目标函数
但是负采样在0.75的时候效果最好
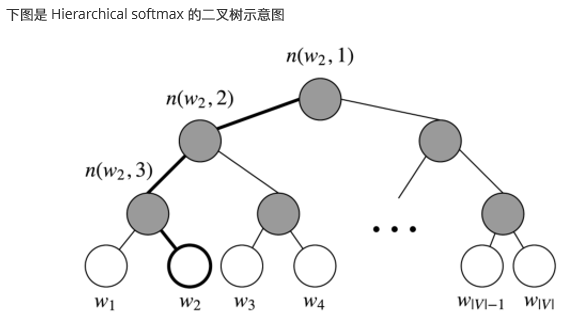
Hierarchical Softmax
, hierarchical softmax tends to be better for infrequent words, while negative sampling works better for frequent words and lower dimensional vectors.Hierarchical Softmax 对低频词往往表现得更好,而负采样对高频词和低维度向量表现的更好
Finally, we compare the similarity of our input vector to each inner node vector using a dot product. Let's run through an example. Taking in Figure 4, we must take two left edges and then a right edge to reach