【论文】PathQG: 基于事实的神经问题生成
![]()
引言
![]()

引言

EMNLP2020中,复旦大学数据智能与社会计算实验室 (Fudan DISC) 提出了一篇基于事实的问题生成工作,论文题目为:PathQG: Neural Question Generation from Facts,被录取为长文。
![]()
文章摘要
![]()
文章摘要

关于问题生成的当前研究通常将输入文本作为序列直接编码,而没有明确建模其中的事实信息,这会导致生成的问题和文本不太相关或者信息量较少。在这篇论文中,我们考虑结合文本中的事实以帮助问题生成。我们基于输入文本的事实信息构造了知识图,并提出了一个新任务:给定知识图中的一条query路径生成问题。任务可以被分为两个步骤,(1)对query表示的学习;(2)基于query的问题生成。我们首先将query表示学习定义为序列标记问题,以识别涉及的事实从而学习到一个query表示,之后使用基于RNN的生成器进行问题生成。我们以端到端的方式共同训练这两个模块,并提出通过变分框架加强这两个模块之间的交互。我们基于SQuAD构造了实验数据集,实验结果表明我们的模型优于其他方法,并且当目标问题复杂时,性能提升更多。通过人工评估,也验证了我们生成的问题的确和文本更相关且信息更丰富。
![]()
研究动机
![]()
研究动机
本文关注基于文本的问题生成任务(Question Generation from Text):输入一段文本,自动生成对应的问题。
当前端到端的问题生成研究,通常对输入文本直接编码并学习一个隐表示,而没有对其中的语义信息进行明确建模,这会使得生成过程有较大不确定性,导致生成的问题包含和给定文本不相关的信息或者信息量较少,如下图显示,生成的问题Q2包含了不相关的信息“Everton Fc”,而Q1虽然正确但是缺少特定的信息描述,显得比较简略。
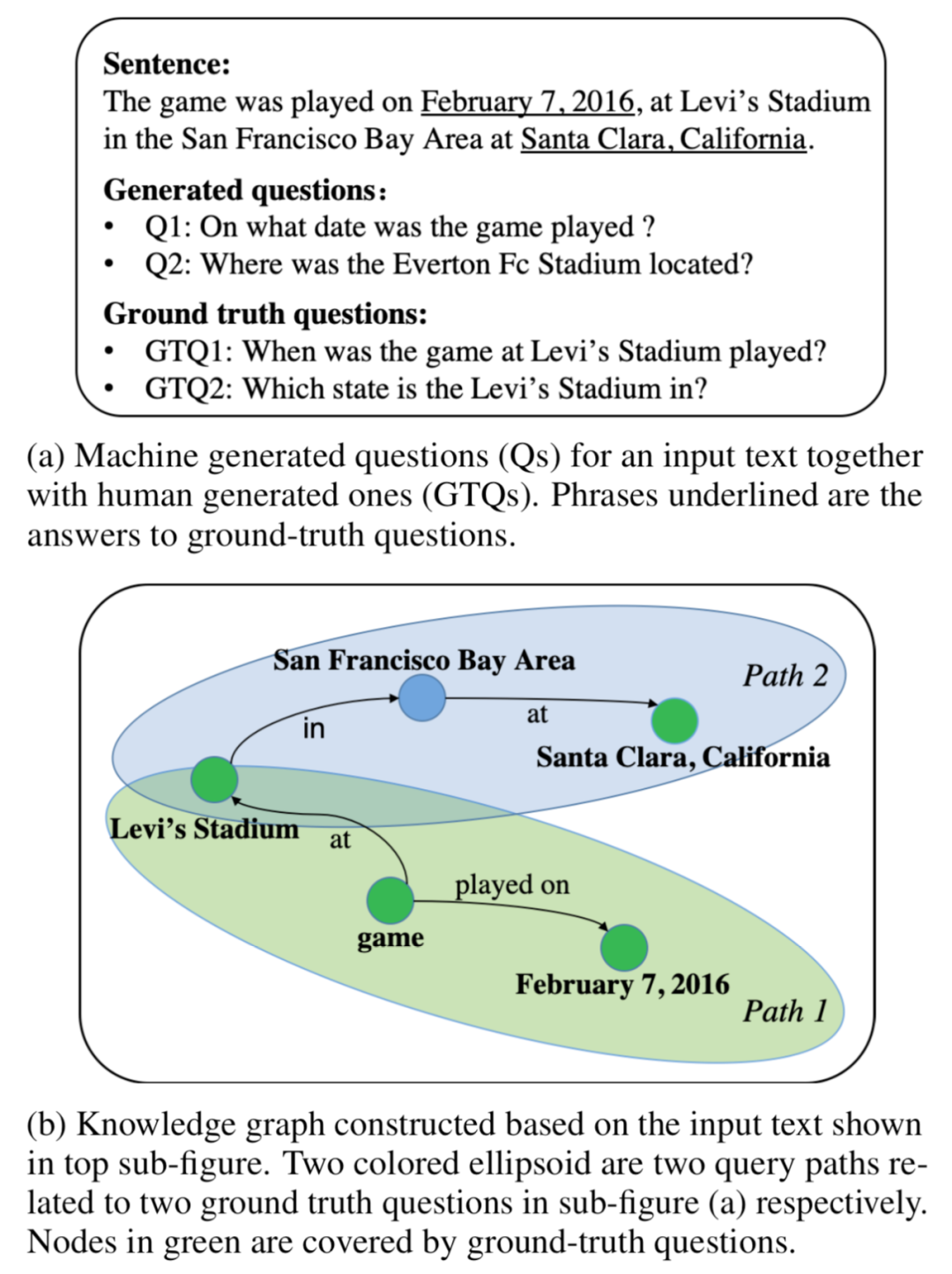
先对输入文本中的事实(facts)进行建模可以减轻这些问题,并且针对文本中的多个事实,可以生成较为复杂(complex)的问题。我们通过对给定文本构建知识图谱(Knowledge Graph,KG)来表示其中的事实,并提出一个新任务:给定知识图谱中的一条query path来生成问题,其中query path是一条由多个事实三元组构成的序列,每个事实三元组包含两个实体以及它们的关系。如上图(b)显示了一个KG以及其中的两条query paths。
由于query path中并非所有事实都会在目标问题中被提及,我们首先需要学习一个query representation来表示query path中会被提及的事实信息,并基于此生成对应的问题,因此任务可以分成两个步骤:(1)对query representation的学习;(2)基于query的问题生成。我们以端到端的方式共同训练这两个模块,并提出通过变分框架加强这两个模块之间的交互。
我们使用了数据集SQuAD,并且为了验证模型在复杂问题生成上的效果,基于SQuAD构造了一个复杂问题数据集,并分别进行了实验。
![]()
模型
![]()
模型
Path-based Question Generation
给定query path的问题生成任务包含两个步骤,我们设计两个模块:Query Representation Learner和Query-based Question Generator 分别进行任务中的两个步骤。我们首先以端到端的框架PathQG共同训练这两个模块,具体结构如下图显示。
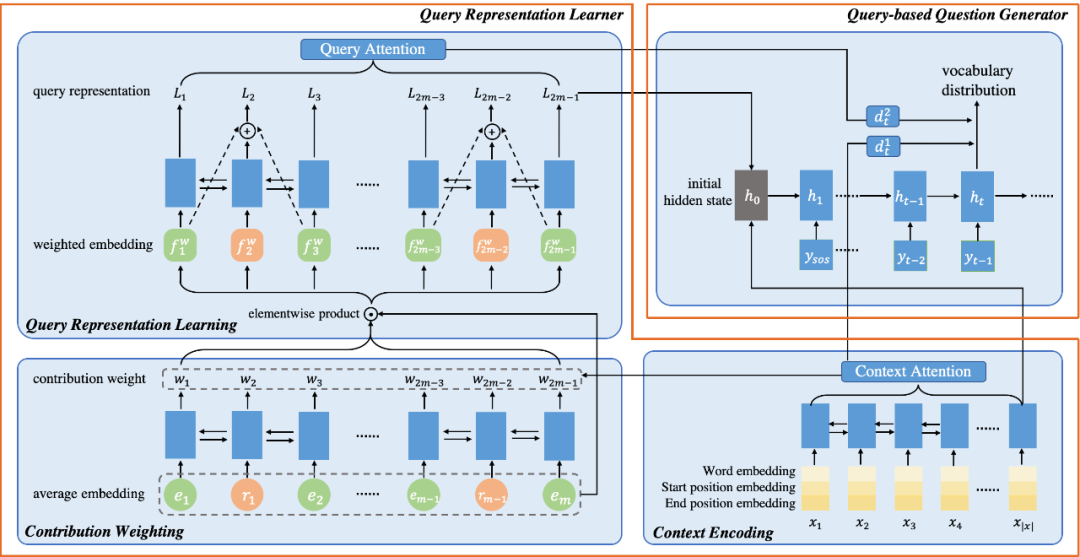
1. Query Representation Learner
由于query path中的不同的实体和关系会对生成目标问题有不同的贡献度,我们首先计算它们各自的贡献权重,从而学到一个query representation来表示目标问题将涉及的事实信息。
贡献权重计算:将query path看作是一条由实体和关系相间构成的序列,并将query path中各个成分的贡献度计算看作是一个序列标记过程。并且对输入文本进行编码作为context,通过attention帮助序列标记的概率计算,最后将各个位置的sigmoid概率作为各自的贡献权重。
Query表示学习:得到query path的各个成分的贡献权重后,我们以加权的方式对query path编码,学习到对应的query representation L。考虑到query path由实体和关系相间构成的特殊结构,我们使用循环跳跃网络(recurrent skipping network, RSN)来对路径序列进行编码。
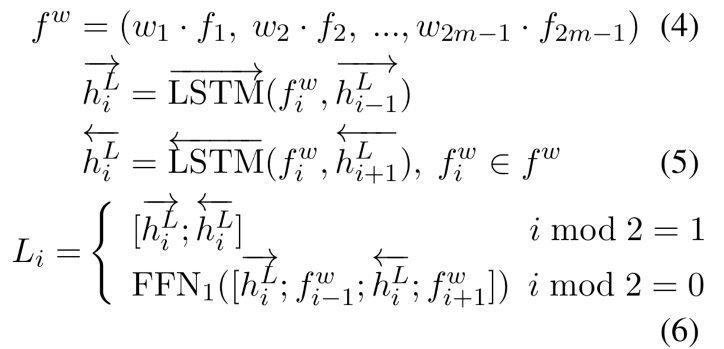
2. Query-based Question Generator
基于学到的query representation L,解码生成对应的问题。将最后的query representation和context表示联合作为解码器的初始状态,并分别对他们执行注意力机制,逐步生成问题。
Variational Path-based Question Generation
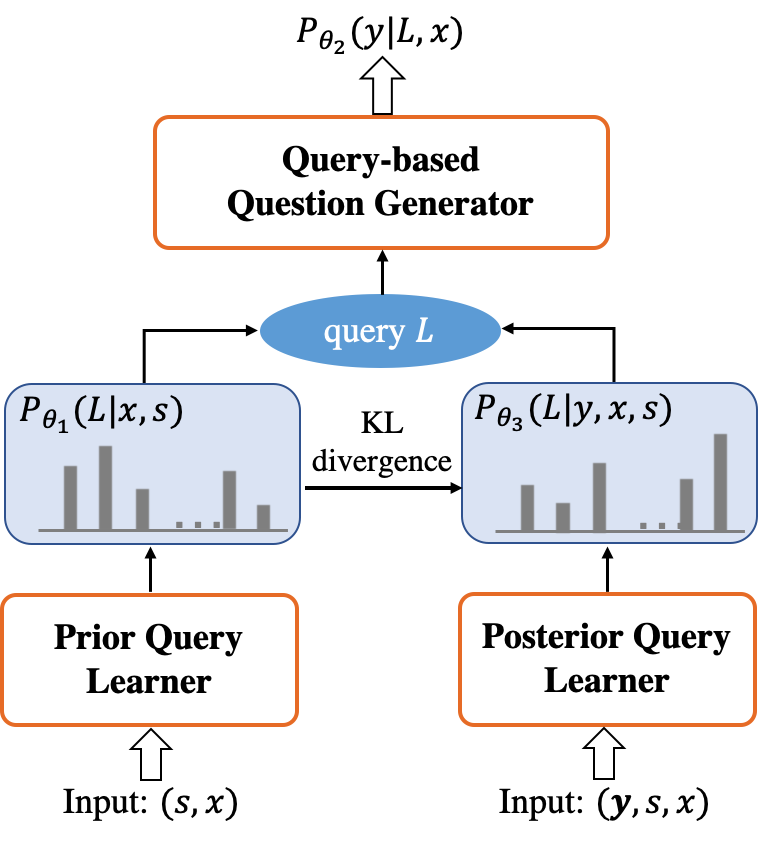
对query representation的学习可以看成是对query path的一个推断过程,参考变分推断的思想,我们将query representation的学习看作是推导query的先验分布(prior query distribution),而基于query的问题生成是在计算目标问题的likelihood,我们又引入了一个额外的后验query分布(posterior query distribution),通过将目标问题作为指导来帮助减少query representation学习的不确定性。并且通过训练,使得query的先验分布不断靠近后验分布,最终提升生成的问题质量。变分PathQG的结构如下图。
![]()
实验
![]()
实验
我们在SQuAD数据集上进行了实验,对每一条文本,通过场景图解析器(scene garph parser)和词性标注器(part-of-speech tagger)自动构建了知识图谱,并且根据参考问题从知识图谱中抽取出对应的query path。为了进一步验证模型在复杂问题生成上的效果,我们还根据query path中事实三元组的个数从SQuAD中划分了一个复杂问题数据集。在全数据集和复杂数据集上的实验结果显示我们的模型都优于其他模型。
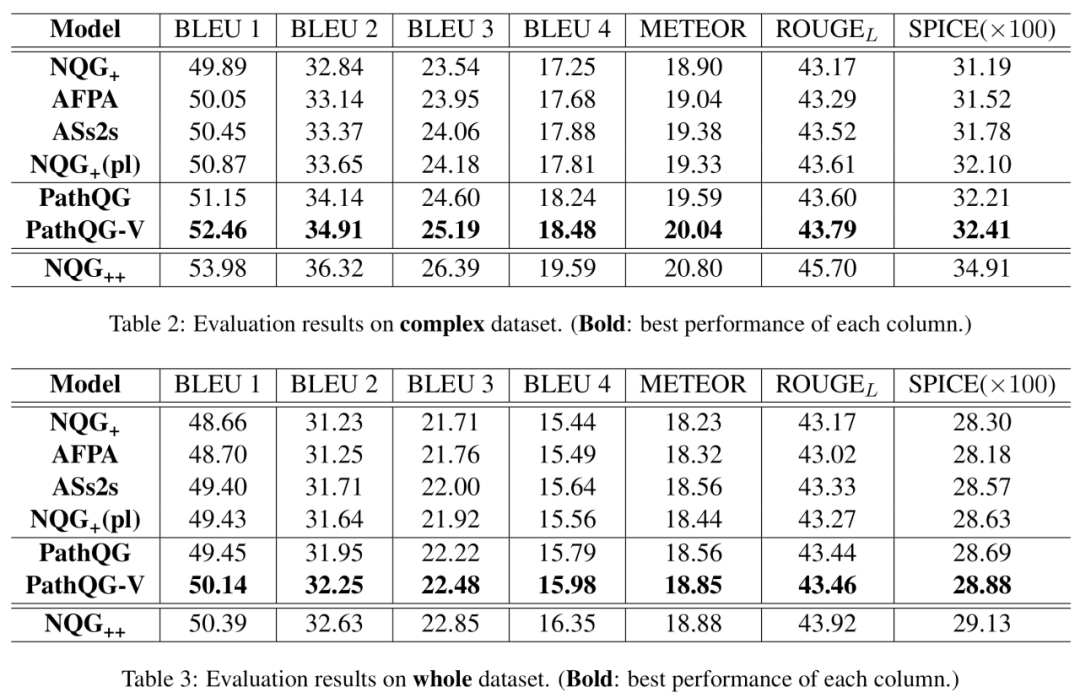
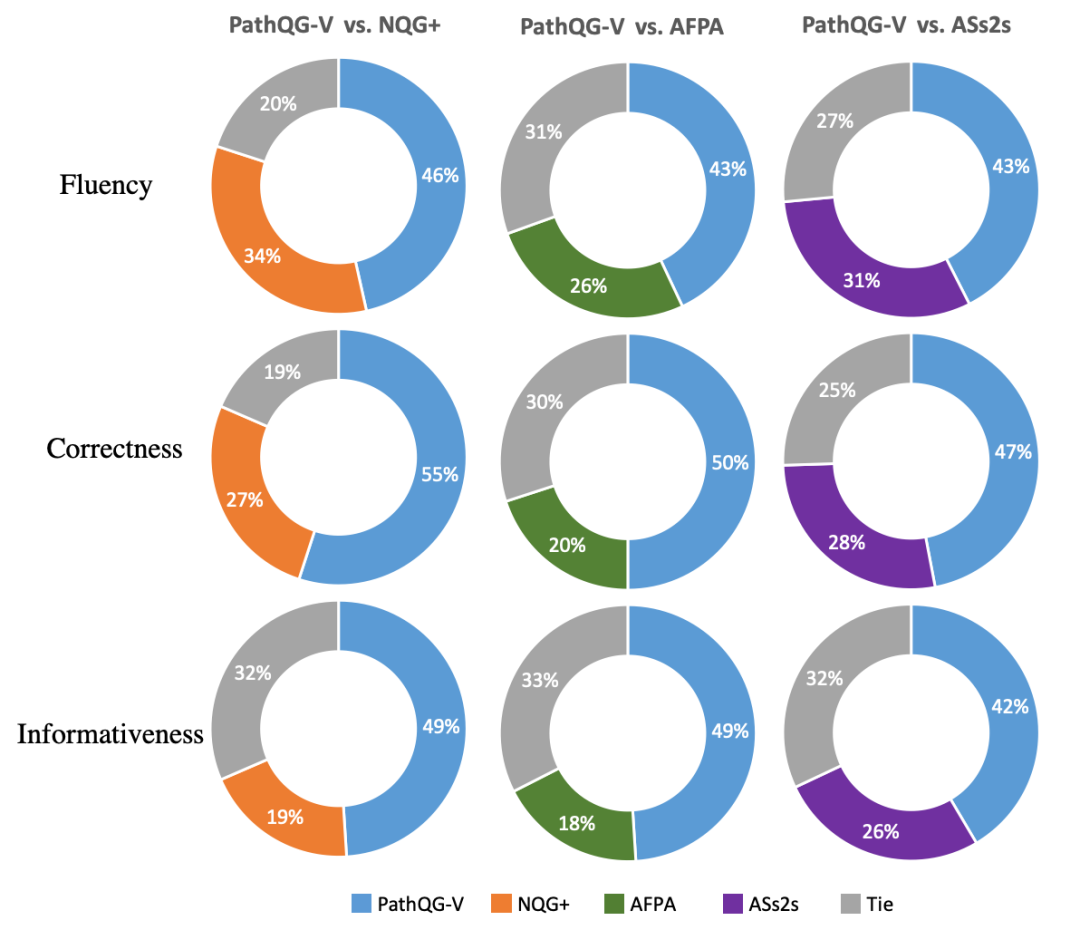
除了自动评估,我们还通过Amazon Mechanical Turk (AMT)进行了人工评估,分别从问题的流利度、正确性(和给定文本和答案一致)、信息量对不同模型生成的问题进行了两两比较,结果显示我们的模型也取得不错效果。
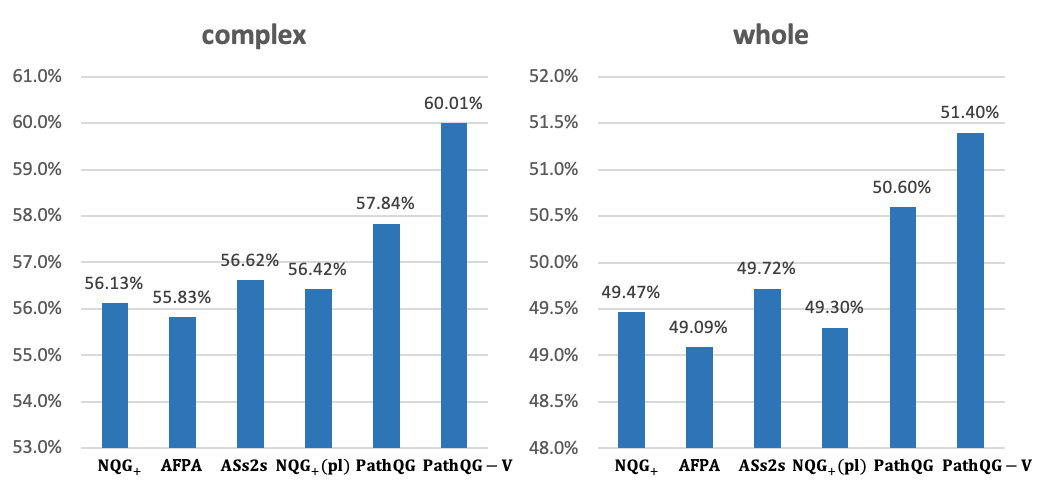
我们还通过对不同模型生成的问题和给定文本之间的重叠率进行比较,来评估生成问题和给定文本的相关性。
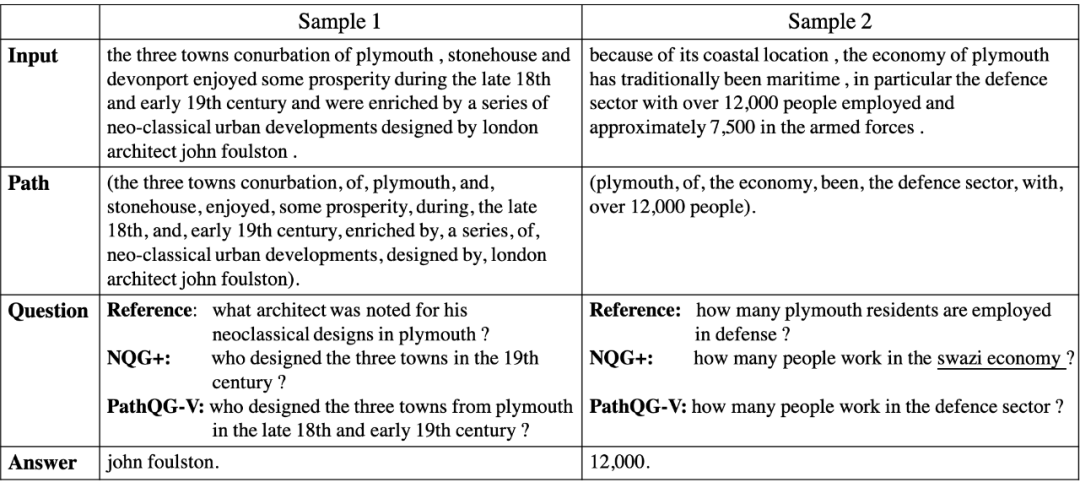
最后还进行了一些案例分析,可以看出相对模型NQG+,我们生成的问题更加和文本相关和有信息量。在第一个样例中,我们生成的问题包含有特定信息“plymouth”和“late 18th”而*NQG+没有,而在第二个例子中NQG+*生成的问题包含不相关的“swazi economye”而我们生成的和给定文本更一致。
![]()
总结
![]()
总结
这篇文章中,我们通过知识图谱对文本中的事实建模用于问题生成,并提出一个新任务:给定知识图谱中的一条query path,生成对应的问题。我们提出先学习一个query representation来表示问题中可能涉及的事实,再生成问题,将这两个模块联合进行训练并提出一个变分模型提升问题的生成。我们通过自动构建知识图谱并抽取出对应的query path构建了我们的实验数据集,结果验证了我们模型的有效性。
供稿人:王思远丨研究生三年级丨研究方向:基于文本的问题生成、知识建模
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套!
![]()
![]()
![]()
后台回复【五件套】
下载二:南大模式识别PPT
![]()
后台回复【南大模式识别】




由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!





