陈丹琦“简单到令人沮丧”的屠榜之作:关系抽取新SOTA!
陈丹琦大佬(女神)最近发表了一篇最新的关系抽取SOTA《A Frustratingly Easy Approach for Joint Entity and Relation Extraction》,光看题目就让人眼前一亮:是啥子简单方法,让实体关系的联合抽取方法“沮丧”了?
仔细阅读原文后,发现这篇paper采取pipeline方式就超越了一众联合抽取模型(joint model),登顶ACE04/05、SciERC榜首!
也许你会问:咦?现在的关系抽取SOTA不都是各种joint方式吗?有木有搞错?JayJay也有各种疑问:
现在的关系抽取不是都采取joint方式、魔改各种Tag框架和解码方式吗?
不是说pipeline方式存在误差积累吗,还会增加计算复杂度(实体冗余计算)吗?
不是说pipeline方式存在交互缺失,忽略实体和关系两个任务之间的内在联系吗?
不是说......
其实在这篇paper中,丹琦大佬并没有只是简单地刷刷SOTA而已,而就上述等若干问题进行了仔细探究~不过还是先po一下这篇SOTA的主要贡献和结论(开始正经,划重点):
设计了一种非常简单的end2end关系抽取方法,即采取2个独立的编码器分别用于实体抽取和关系识别,使用相同的预训练模型就超越了之前所有的joint模型~
分别学习实体和关系的不同上下文表示,比联合学习它们更有效~
在关系模型的输入层融合实体类别信息十分重要~
提出了一种新颖并且有效的近似方法,在精度下降很小的情况下,就实现8-16倍的推断提速~
看到上述结论,也许我们需要打破这些刻板印象,重新审视所谓的“joint就一定好于pipeline”吧~下面赶紧和JayJay一起去膜(shen)拜(shi)一下这篇SOTA吧~
论文链接:
https://arxiv.org/pdf/2010.12812.pdf
这些年我们魔改过的joint模型
正式介绍本文的pipeline方法之前,我们先来回顾一下这些年我们魔改过的joint模型。实体关系的joint抽取模型可分为2大类:
第1类:多任务学习(共享参数的联合抽取模型)
多任务学习机制中,实体和关系共享同一个网络编码,但本质上仍然是采取pipeline的解码方式(故仍然存在误差传播问题)。近年来的大部分joint都采取这种共享参数的模式,集中在魔改各种Tag框架和解码方式。这里简单归纳几篇被大家熟知且容易实践的paper:
多头选择[1]:构建
的关系分类器对每一个实体pair进行关系预测(N为序列长度,C为关系类别总数),输入的实体pair其实是每一个抽取实体的最后一个token。后续基于多头选择机制,也有paper引入预训练语言模型和bilinear分类。
-
层叠式指针标注 [2]:将关系看作是SPO(Subject-Prediction-Object)抽取,先抽取主体Subject,然后对主体感知编码,最后通过层叠式的指针网络抽取关系及其对应的Object。 -
Span-level NER[3]:通过片段排列抽取实体,然后提取实体对进行关系分类。

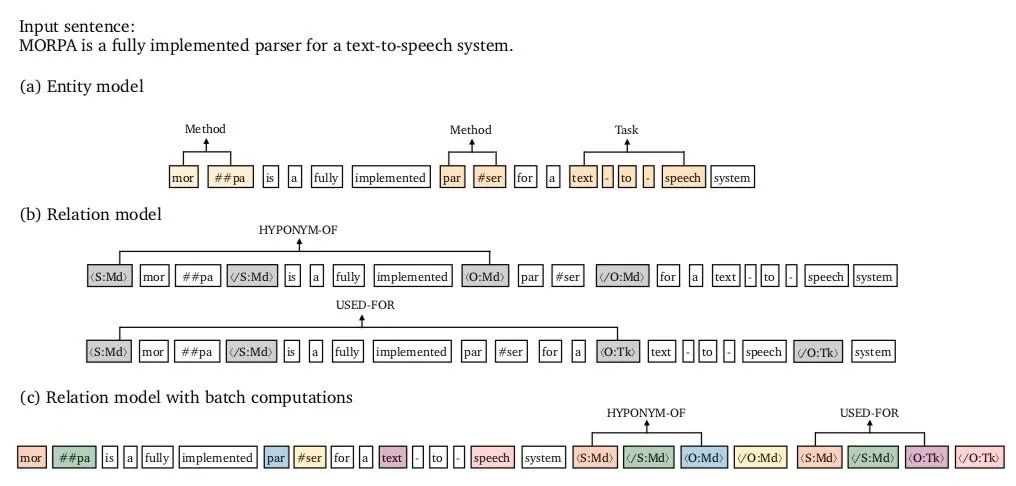
实体模型:如上图(a)所示,采取Span-level NER的方式,即基于片段排列的方式,提取所有可能的片段排列,通过SoftMax对每一个Span进行实体类型判断。这样做的好处是可以解决嵌套实体问题,但计算复杂度较高,因此需要限制Span长度(对于含n个token的文本,理论上共有
种片段排列)。
-
关系模型 :如上图(b)所示,对所有的实体pair进行关系分类。 其中最重要的一点改进,就是将实体边界和类型作为标识符加入到实体Span前后,然后作为关系模型的input。 例如,对于实体pair(Subject和Object)可分别在其对应的实体前后插入以下标识符: -
<S:Md>和</S:Md>:代表实体类型为Method的Subject,S是实体span的第一个token,/S是最后一个token; -
<O:Md>和</O:Md>:代表实体类型为Method的Object,O是实体span的第一个token,/O是最后一个token;
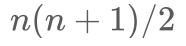
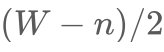 个words,
个words,
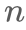 为文本长度,
为文本长度,
 为固定窗口大小。
为固定窗口大小。
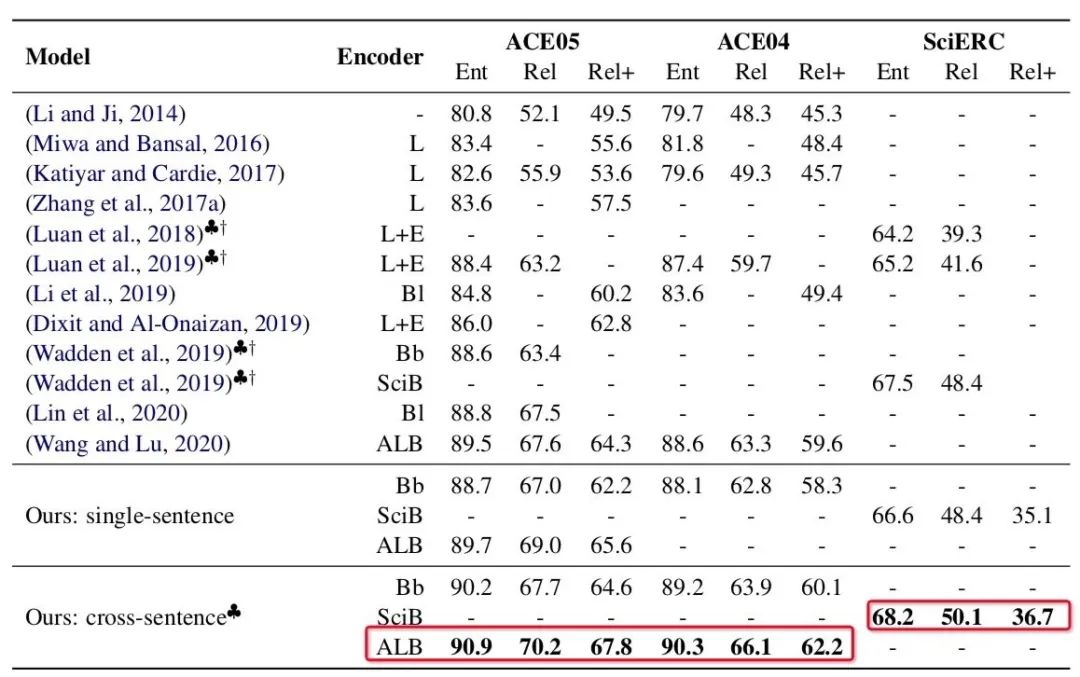
-
不使用跨句信息(单句设置)就超越了ACE04/ACE05曾经的SOTA(使用同一预训练模型),使用跨句信息更是了不得啊。 -
使用跨句信息登顶了SciERC(文档级)的SOTA;
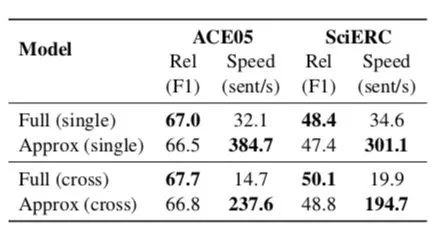
-
在单句设置中,ACE05和SciERC分别提速11.9倍和8.7倍,而指标仅仅下降0.5%和1.0%。 -
「近似模型」加速明显(划重点) :我们先不要考虑是不是SOTA的事情,这个「近似模型」one-pass编码的的方式就足够让我们眼前一亮,这种方式 与预训练模型兼容的恰到好处,权衡性能和准确性 ,相信在实际应用中具有重要意义!
pipeline如此强悍,自有它的道理,也有“先兆”
-
TEXT:直接提取原始文本中,实体span所对应的编码表示。 -
TEXTETYPE:在TEXT的基础上,concatenate实体类别向量。 -
MARKERS:将标识符S、/S、O、/O插入到原始文本中,但是标识符没有实体类别信息。 -
MARKERSETYPE:在MARKERS的基础上,concatenate实体类别向量,这是一种隐式的融入实体类别的方法。 -
MARKERSELOSS:在关系模型中,构建判别实体类别的辅助loss。 -
TYPEDMARKERS:就是本文所采取的方法,实体类别“显式”地插入到文本input中,如<S:Md> 和</S:Md>、<O:Md>和</O:Md>。
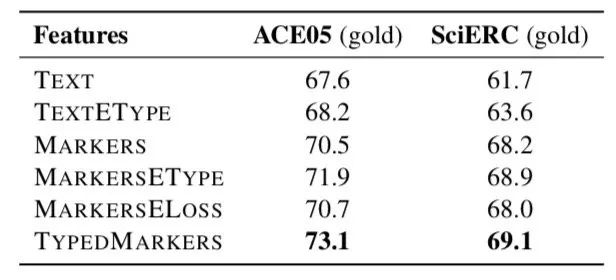
-
本文采取的 TYPEDMARKERS实体表征方式 ,秒杀其余方式; -
实体类别信息对关系模型很重要 ,“显式”地编码实体类别信息好于隐式编码;在构造标识符时,不仅要区分span边界、更要显示融入实体类别信息。 -
MARKERSETYPE比MARKERSELOSS好 ,说明直接引入实体类型特征好于辅助loss的设计。
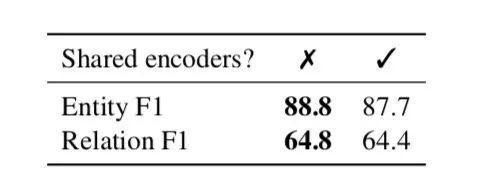
你打破“joint好于pipeline”的刻板印象了吗?
-
引入实体类别信息会让你的关系模型有提升~ -
对于实体关系抽取,2个独立的编码器也许 会更好~
-
怎么减轻/避免误差传播呢? -
pipeline是不是推断效率还是慢?比如,还是会存在冗余实体的计算? -
落地场景中,是不是pipeline更容易迭代优化呢? -
下一个重新登顶SOTA的joint模型长啥样子啊?






