CVPR2019 | 港中文&腾讯优图等提出:暗光下的图像增强
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者: 刘浪
https://zhuanlan.zhihu.com/p/67785574
本文已授权,未经允许,不得二次转载
Underexposed Photo Enhancement using Deep Illumination Estimation
基于深度学习优化光照的暗光下的图像增强

论文地址:http://jiaya.me/papers/photoenhance_cvpr19.pdf
暗光拍照也清晰,这是手机厂商目前激烈竞争的新拍照目标。
提出基于深度学习优化光照的暗光下的图像增强模型,用端到端网络增强曝光不足的照片。
而且不是像以前的工作那样,直接学习图像到图像的映射,而是在新网络中引入中间照明,将输入与预期的增强结果相关联,增强网络从专家修饰的输入/输出图像学习复杂的摄影调整的能力。在此模型的基础上,构造了一个对光照采用约束和先验的损失函数,结果证明,新算法模型,效果超过了市面上一众当红的多摄多硬手机
传统夜景图像增强算法大致可以分为几个方面: 直方图均衡化(Histogram equalization) ,这种方法简单的利用了图像整体的统计性质,通常不能对复杂场景达到理想效果。
基于Retinex理论的增强算法,通常只能用单通道进行光照优化,颜色无法很好地回复,在光照复杂的情况下还容易出现过曝的现象。
这些传统方法还容易在增加图像亮度的同时,放大噪声等瑕疵,影响图像质量。
基于深度学习的方法,通常是直接训练回归(regression)模型,由于数据本身的特性,这种方法得到的结果通常清晰度、对比度比较低,而且会有一些人工痕迹。

提出了一种新的端到端图像增强网络。特别地,没有直接学习图像到图像的映射,而是设计网络,首先估计一个图像到光照的映射来建模各种光照条件,然后使用光照映射来照亮曝光不足的照片。此外,为了降低计算成本,我们采用了基于双网格的上采样,并设计了一个在光照上采用各种约束条件和先验的损失函数,使我们能够有效地恢复自然曝光、对比度合适、细节清晰、色彩鲜艳的低曝光照片。
方法
图像增强的任务可以被看作是寻求一个映射函数 




这里S建模为RGB三通道是为了增强其对颜色增强的建模能力,特别是对不同颜色通道的非线性处理能力。 
网络架构
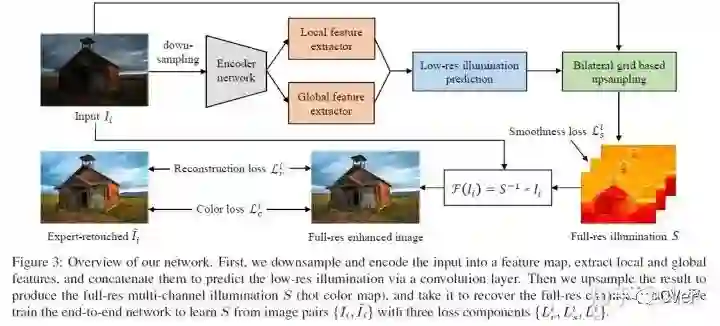
网络分成了 全分辨率分支 和 低分辨率分支 。其中低分辨率分支用于学习到全图光照的整体信息,低分辨率图像的使用,有助于增大网络感受野,提高算法速度。
低分辨率分支的结果将会传递给高分辨率网络分支,用于重建全分辨率下的亮度图,并最终得到增强后的图像。
损失函数
从N对图片 





Reconstruction Loss:
为了得到预测的S,我们定义 
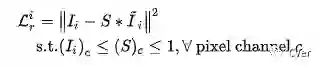
其中, 







Smoothness Loss:
根据先验光滑性,自然图像中的光照一般为局部光滑。在我们的网络中采用这种优先级有两个优点。首先,它有助于减少过度拟合,提高网络的泛化能力。其次,它增强了图像的对比度。当相邻像素点p和q的光照值相似时,它们在增强图像中的对比度可以估计为 


其中对所有像素的所有通道(c)求和, 

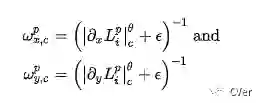
这里, 


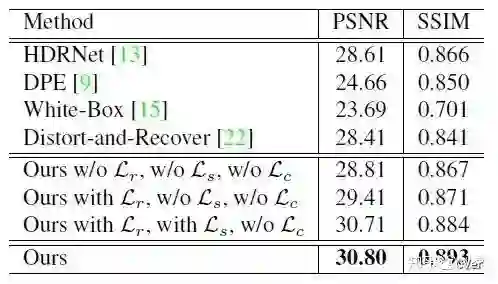
直观地说,平滑度损失鼓励光照在小梯度的像素上是平滑的,而在大梯度的像素上是不连续的。有趣的是,对于曝光不足的照片,图像内容和细节往往很弱。较大的梯度更可能是由不一致的光照造成的。如图4中的第4幅图像所示,通过进一步加入平滑度损失,我们恢复了良好的图像对比度,与仅重建损失的结果相比,细节更加清晰。
Color Loss
接下来,设计颜色损失来使生成的图像



我们在其他颜色空间中使用这个简单的公式而不是L2距离的原因如下。首先,重构损失已经隐含地测量了L2色差。其次,由于L2度规仅用数值方法测量色差,因此不能保证颜色向量具有相同的方向。
并在NVidia Titan X Pascal GPU上以mini-batch为16进行40个epoch的训练。优化器使用Adam,固定学习率为 


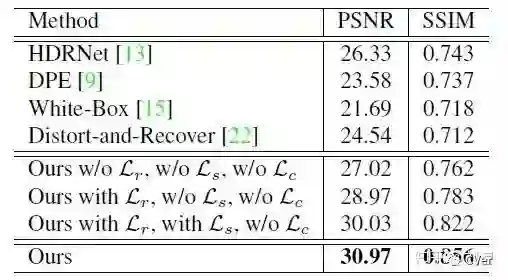
结果


使用了两个常用的度量标准(即,PSNR和SSIM)来定量评估我们的网络性能,根据预测结果和相应的专家润色图像之间的颜色和结构相似性。虽然这不是绝对的指示性,但总的来说,高的PSNR和SSIM值对应着相当好的结果。

CVer学术交流群
扫码添加CVer助手,可申请加入CVer-目标检测交流群、图像分割、目标跟踪、人脸检测&识别、OCR、超分辨率、SLAM、医疗影像、Re-ID和GAN等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群
这么硬的论文精读,麻烦给我一个在在看

▲长按关注我们
麻烦给我一个在看!

