学界 | FAIR提出通用音乐转换网络:你的口哨声也能变成交响乐
选自arXiv
作者:Noam Mor等
机器之心编译
参与:乾树、刘晓坤
Facebook AI Research 近日提出了一种基于多域 WaveNet 自编码器的跨乐器、流派、风格的音乐转换方法。在 NSynth 和从专业音乐家收集的数据集上的实验评估上,该网络实现了令人信服的音乐转换,甚至可以转换口哨声;这使得未经训练的人类也具有了创作乐器音乐的潜能。
引言
人类总是在创造和重复音乐——无论是通过唱歌、吹口哨、拍手,还是在经过训练后即兴演奏或标准演奏。这种能力并不是只有人类才有的,世界上还有许多其他能通过听觉重复音乐的声乐模仿物种。
音乐也是第一个通过现代计算机和算法进行数字化和处理的领域之一。因此,在模拟这一核心音乐任务中人工智能竟仍然比生物系统差得多,这实在有些令人惊讶。
在这项工作中,据研究者所知,这是第一次在乐器、风格和流派之间生成高保真的音乐转换。例如,他们把管弦乐队演奏的莫扎特交响乐的音频转换为贝多芬风格的钢琴演奏音频。这种能力建立在最近可用的两种技术上:(i)使用自回归模型合成高质量音频的能力,以及(ii)最近出现的以无监督的方式在域之间转换的方法。
上述第一种技术很重要,主要有两个原因。第一,它使我们能生成高质量、高仿真的音频。第二,使用教师激励技术(teacher forcing technique)进行训练,自回归模型能有效地被训练为解码器。而第二种技术有助于增加解决方案的实用性,因为在监督设置中提出学习问题需要不同乐器的并行数据集。
在本文提出的架构中,研究者采取单一的通用编码器,并将其应用于所有的输入。除了能训练较少神经网络的优势之外,这还能使我们把在训练期间没听过的音乐域转化到任意曾接触的音乐域中去。
单一解码器体系结构可训练的关键在于,确保域特定(domain-specific)的信息不被编码。研究者使用域混淆网络(domain confusion network)为编码器提供对抗信号来实现这一点。此外重要的是,编码器不能记忆输入信号,而是要以语义的方式来编码。研究者通过随机局部音调调制使输入音频失真来实现这一点。
在训练过程中,神经网络被训练为去噪自编码器,它能恢复原始输入的无失真版本。由于失真输入不再处于输出的音乐域,因此网络可以学习将域外的输入投影到所需输出域中去。此外,网络不再受益于记忆输入信号,同时采取了更高级的编码方式。
据作者所知,他们当前结果所展示的能力是前所未见的。在将一种乐器转化为另一种乐器的要求下,该网络比专业音乐家的表现几乎持平或略差一些。很多时候,人们很难分辨哪个是原始音频文件,哪个又是模拟完全不同乐器的转换性输出。在编码方面,该网络能够成功处理未经训练的乐器或其他声源,如口哨声。在输出端,网络能产生相对高质量的音频,并且可以在不需要再训练整个网络的情况下,添加新的乐器选项。
方法
本研究使用的方法基于训练多个自编码器路径(每个音乐域一个路径),这样编码器就可以共享。在训练期间,基于 softmax 的重建损失分别应用于每个域。在应用编码器之前,输入数据被随机增强,这能强制网络提取高级语义特征,而不是简单地记忆数据。另外,对潜空间应用域混淆损失以确保编码不具域特定性。该网络结构图如图 1 所示。
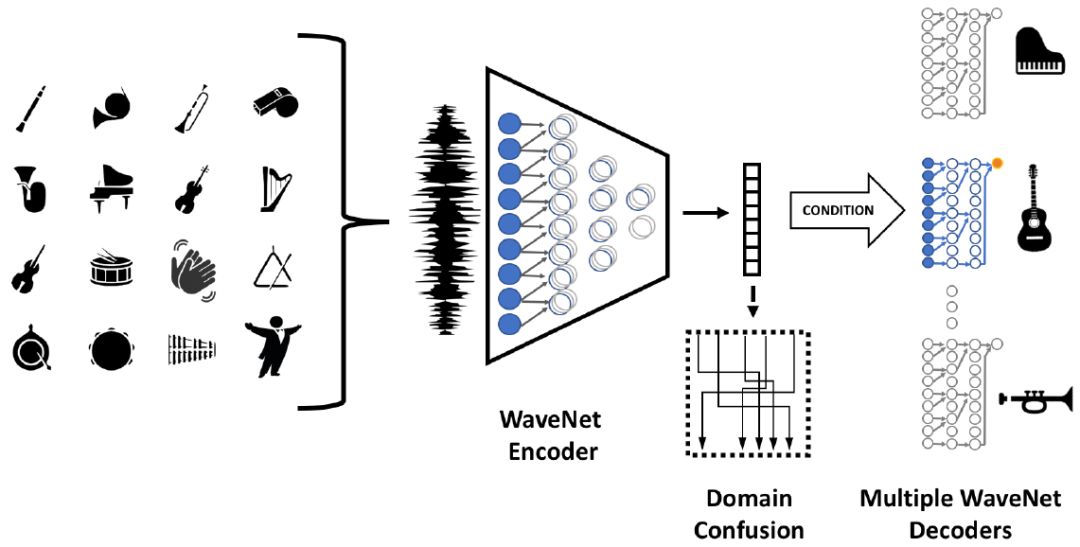
图 1:网络架构。其中混淆块(虚线所示)只在训练中使用。
WaveNet 自编码器
研究者重用了基于 WaveNet 解码器和类似 WaveNet 扩张卷积编码器的现有自编码器架构 [16]。每个解码器的 WaveNet 条件制约于编码器所产生的潜表征。该自编码器和 [16] 之间存在着两个不同之处。首先,该自编码器不以音调为条件,而是让它成为编码本身的一个组成部分。其次,研究者略微修正了 WaveNet 方程,使其架构适合于 NVIDIA 提供的推断时间 CUDA 内核(https://github.com/NVIDIA/nv-wavenet)。
编码器是一个全卷积网络,可以应用于任意序列长度。网络由三个块组成,每个块有 10 个残差层。每一个残差层包含了一个随着核尺寸递增的扩张卷积、一个 RELU 非线性单元,还有一个在第一个 RELU 之前的、跟随在激活值残差和之后的 1×1 卷积。其固定的宽度为 128 个通道。在这三个块之后,还有一个额外的 1×1 层。为了获取 R64 的编码,存在一个平均池化层,其核尺寸为 50 毫秒(800 个样本),实施了一个 ×12.5 因子的时域下采样。
该编码采用最近邻插值法进行时域上采样达到原始音频传输速度,并将其用于决定 WaveNet 解码器,随后紧接一个 1×1 层,该层对每个 WaveNet 层来说是不同的。音频(包括输入和输出)使用 8 位 mu-law 编码进行量化,与 [11,16] 类似,这会导致一些固有的音频品质损失。WaveNet 解码器具有 4 个块,每块 10 个残差层,因此解码器具有包含 4,093 个采样或时长为 250ms 的感受野。
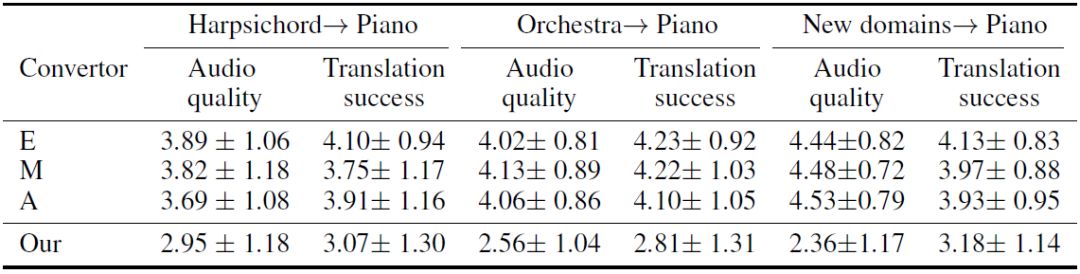
表 1:转换任务的 MOS 分数(均值 ± 标准差)。
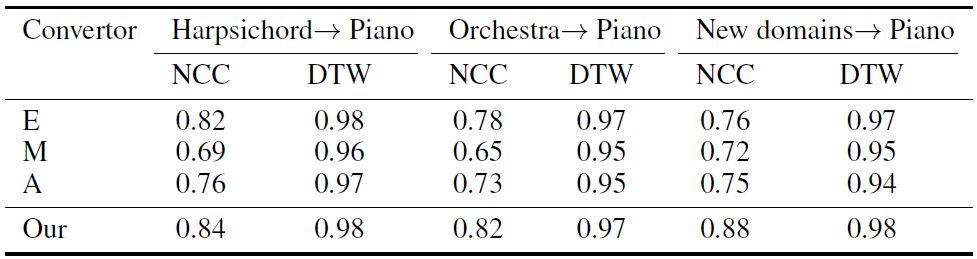
表 2:转换任务的自动化质量分数。
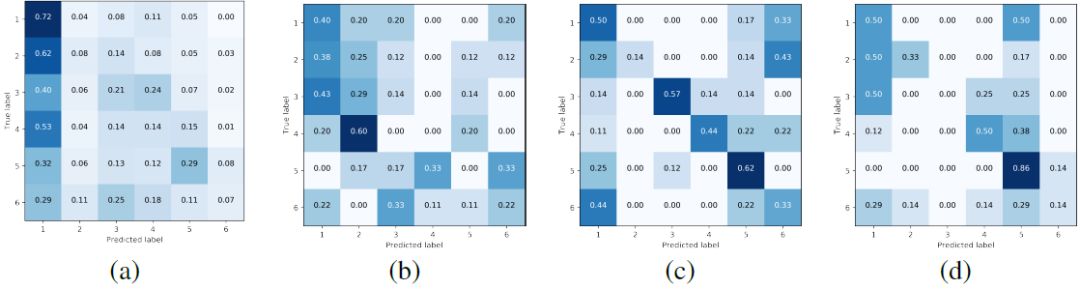
图 2:一组实验结果。(a)普通听众倾向于选择与源相同的域,无论实际源如何。(b)大部分时间下,音乐家 A 都无法识别出源。(c)业余爱好者 T 和(d)业余爱好者 S 也在大部分情况下无法识别,但是 S 的结果更一致。
论文:A Universal Music Translation Network

论文地址:https://arxiv.org/abs/1805.07848
摘要:我们提出了一种跨乐器、流派、风格的音乐转换方法。该方法基于多域 WaveNet 自编码器,具有共享的编码器和一个可以进行端到端波形训练的解缠潜空间(disentangled latent space)。利用多种训练数据集和大规模网络容量,独立于域的编码器使我们甚至能从训练期间未曾见过的音乐域进行转换。该方法是无监督的,它不依赖于域或音乐转录之间的匹配样本的监督。我们在 NSynth 和从专业音乐家收集的数据集上评估本方法,并实现了令人信服的音乐转换,甚至可以转换口哨声;这使得未经训练的人类也具有了创作乐器音乐的潜能。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




