CVPR 2020 Oral | DeepCap:基于单目RGB视频的人体动作捕捉方案
DeepCap
本文转载自:人脸人体重建
人体动作捕捉一直以来都是一个重要的研究热点,在诸如电影制作、虚拟试衣、混合现实等众多领域都有着重要的应用,本文提出了一种基于单目RGB视频的人体捕捉方案,文章已被CVPR 2020接收。

文章作者来自德国马普所、德国萨尔大学和美国斯坦福大学,作者提出了一个基于弱监督神经网络的单目人体动作捕捉方法。整个网络架构分为两个网络,分别进行人体姿态估计和非刚性表面变形,训练基于多视角图像以弱监督的方式进行。
项目主页:https://people.mpi-inf.mpg.de/~mhaberma/projects/2020-cvpr-deepcap/

下面是文章的视频
Method
给定一个穿着普通衣服的运动中的人体的RGB视频,目标是捕获整个人体的稠密变形表面。作者训练了一个神经网络来达到这个目的,整个网络由两个部分组成:
-
PoseNet:从单目图像估计人体骨架的姿态 (基于关节点角度表达) -
DefNet:即变形网络 (Deformation Network),回归人体表面的非刚性形变 (基于嵌入变形图 (Embedded Deformation Graph) 表达)
为了避免3D标注数据的使用,整个网络以弱监督的方向训练,为此作者提出了一个可微 (differentiable) 的人体变形和渲染模型,使得可以渲染人体模型并将其与2D图像进行比较,以此来反向传播损失。作者在经过校准的带有绿幕的多相机工作室中捕捉视频序列作为训练数据,但在测试阶段,只需要单目RGB视频便可以进行人体动作捕捉。整个方法流程如下图所示:
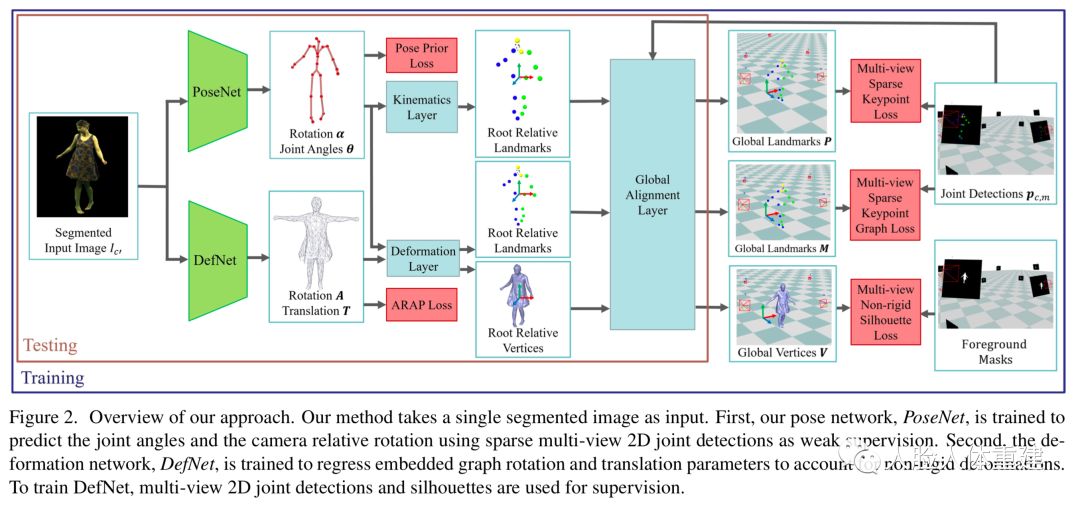
Template and Data Acquisition
Character Model
文章方法依赖个体相关的3D模板网格,作者首先使用3D扫描仪扫描出目标人体的带纹理的网格,然后再自动绑定一个骨架,该骨架相关的参数包含关节点角度 ,相对于相机的旋转 和平移 。为了对人体表面的非刚性形变进行建模,作者自动计算了一个包含 个节点的嵌入变形图 ,节点参数包含欧拉角 和平移 。与 LiveCap[2] 一致作者将人体网格划分为不同的非刚性类别,得到每个顶点的刚性权重 ,这样便可以根据不同的表面材质来建模变形,如皮肤变形的幅度会比衣服更小。下图展示了两个角色模型。
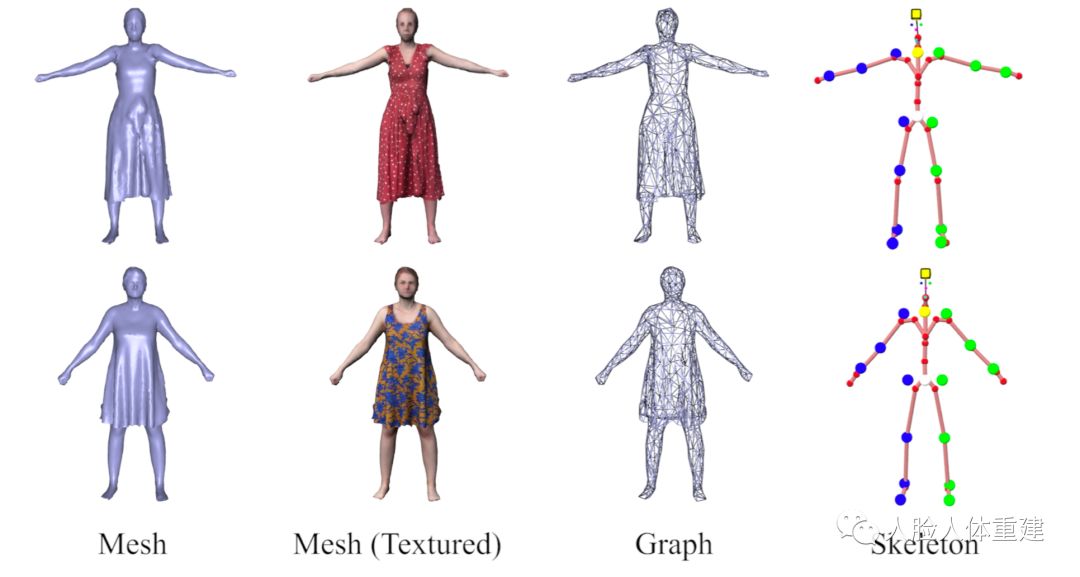
Template Mesh
人体模板网格是通过商业软件 Agisoft Metashape 重建的,作者使用134个彩色相机同时采集了T-Pose下的静态人体图片,该软件从这134张彩色图片重建出带纹理的人体模型,然后作者对重建后的网格进行了简化和重建网格化,以得到质量更好地三角网格。
Embedded Deformation Graph
为了得到人体的嵌入变形图,作者对人体模板网格进行了简化,得到了大约含有500个顶点的简化网格,通过简化后的网格的拓扑关系计算每个节点的相邻节点集合 ,通过在模板网格寻找每个简化网格顶点的最近点作为嵌入变形图的节点位置 ,通过计算节点 到顶点 的测地距离 (geodesic distance) 来计算影响顶点 的节点集合 。
Skeleton
作者通过拟合 SMPL 人体模型 到模板网格来将其骨架嵌入到人体中,对于与皮肤比较近的模板网格顶点如裤子短袖等,直接将 SMPL 的蒙皮权重迁移到模板网格顶点上,对于离得比较远的顶点如裙子等,通过 Blender 软件自动计算蒙皮权重。人体骨架一共有23个关节点包含27个角度参数,并含有21个关键点 (17个人体和4个人脸关键点)。
Training Data
作者使用带有绿幕的标定好的多相机系统来采集表演者各种动作的多视角视频,并使用 OpenPose 检测图片中的2D人体关键点并进行时序滤波。然后计算前景人体Mask并计算对应的距离变换图 (distance transform image) ,其中 和 分别表示视频帧序号和相机编号。在训练阶段,随机采样一个相机视角 和 视频帧 ,并使用基于2D关键点计算的人体包围盒裁剪图片。最终训练时的输入图片 是去除背景后,并随机亮度、色相、对比度和饱和度来增强前景而获得的。
Pose Network
PoseNet 使用在 ImageNet 上预训练的 ResNet50 作为骨干网,最后一个全连接层改为输出关节点角度 和相对相机的旋转 。由于要想得到真实的 和 非常困难,作者将人体骨架去拟合检测的多视角2D关键点来进行弱监督训练。
Kinematics Layer
作者介绍了一种人体动力学网络层 (Kinematics Layer),将角度 和旋转 作为输入,计算骨架的 个 3D 关键点 (包括17个人体关键点和4个人脸关键点) 位置 ,这里 是相对于相机坐标系的,如果要将其投影到其他视角,需要先将其变换到世界坐标系
其中 是相机 的旋转矩阵, 是骨架的整体平移。
Global Alignment Layer
作者在 Kinematics Layer 之后加入一个全局对齐网络层 (Global Alignment Layer) 计算整体平移 ,来确定骨架模型在世界坐标系中的位置。通过极小化旋转后的关键点 到对应的从相机中心 到2D关键点的射线的距离来得到
其中 是从相机 到第 个2D关键点的射线:
这里 是相机 的投影矩阵, 。每个点到射线的距离用检测的2D关键点的置信度 来做权重,对于置信度低于0.4的直接设为0。极小化这个目标函数的意思是对于世界坐标系中的3D人体关键点,其从每个相机视角看过去,应该和图片中检测的2D关键点一致。
该目标函数可以直接计算一个闭式解:
其中
这里 是 的单位阵, 。注意该闭式解的计算相对于关键点位置 是完全可微的。
Sparse Keypoint Loss
PoseNet 使用的2D关键点损失函数是
其保证每个关键点能够投影到各个相机视角下对应的检测到的2D关键点 上, 是相机 的投影公式, 是一个基于关节链的权重,在训练时动态变化以更好地收敛。
Pose Prior Loss
为了避免出现不自然的姿态,作者针对关节点的角度施加了一个姿态先验损失:
以使得每个关节点角度 处于 的范围内。
Deformation Network
只有 PoseNet 预测的骨架姿态并不能表达皮肤、衣服的非刚性形变,因此作者将骨架运动和非刚性变形解耦,通过 DefNet 从输入图片 回归基于嵌入变形图表达的非刚性形变参数,即每个图节点的旋转角度 和平移向量 。DefNet 使用和 PoseNet 一样的骨干网络,最后一个全连接层输出一个 维的向量。在训练 DefNet 期间固定 PoseNet 的网络权重。同样,这里不直接使用 和 作为监督,而是借助一个带有可微渲染 (differentiable rendering) 的变形网络层,使用 多视角人体轮廓图 作为弱监督。
Deformation Layer
变形层使用 DefNet 输出的 和 作为输入来非刚性地变形人体表面
这里 是变形后和变形前模板网格的顶点坐标, 是基于测地距离 (geodesic distances) 的网格顶点相对于变形图节点的权重, 是未变形的图节点的位置, 是所有影响顶点 的图节点集合, 将欧拉角转化为旋转矩阵的函数。在变形后的网格上进一步作用骨架姿态,可以得到给定相机坐标的网格顶点位置:
这里 和 分别是基于对偶四元数蒙皮 (Dual Quaternion Skinning, DQS) 从姿态参数计算的节点旋转和平移。这里两个公式对于骨架姿态参数和图节点参数也都是可微的,因此可以直接继承到深度学习框架中。此时计算的 还是处于相机坐标系下,通过公式 可以将其变换到世界坐标系下。
Non-rigid Silhouette Loss
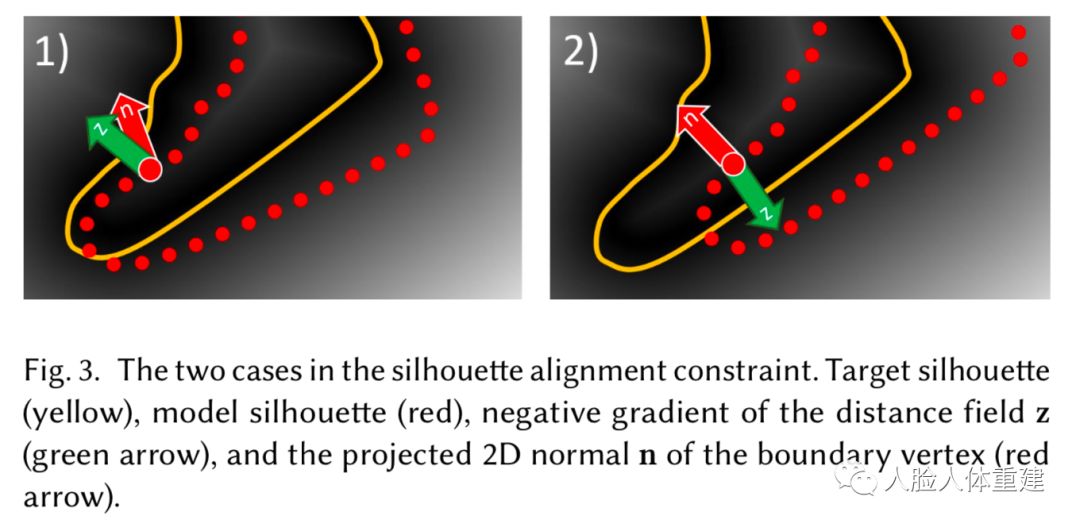
轮廓损失促使非刚性形变的网格与所有相机视角下的人体轮廓相匹配,其通过距离变换表示来计算
这里 是变形后的3D网格投影到相机 下的距离变换图 后的边界顶点集合, 是与 LiveCap[2] 中类似的方向权重,指导边界顶点沿着 的梯度方向运动。轮廓损失确保投影的网格边界处于距离变换图的零等值面,也就是与人体前景轮廓对齐。
Sparse Keypoint Graph Loss
仅仅使用轮廓损失可能会导致错误的网格到图像的对齐,特别是对于姿态复杂的运动情况。因此作者提出了一个与 PoseNet 中类似的稀疏关键点损失来约束网格变形:
与 PoseNet 中不同,这里的关键点 是通过嵌入变形图计算得到的,首先在标准姿态下找到离关键点 最近的节点 ,然后取 通过上面小节的公式计算变形后的关键点 ,然后将其变换到世界坐标系 。
As-rigid-as-possible Loss
为了增强变形后网格表面的局部光滑性,作者进一步施加了尽可能刚性 (As-rigid-as-possible, ARAP)损失:
其中
是节点 的相邻节点集合,权重因子 影响变形图中每个部分的刚性程度,通过对所有与节点 和 相连的网格顶点的刚性权重 平均得到。这样网格能够基于表面材质进行相应程度的变形,如影响裙子的节点比影响皮肤的节点有更大的变形空间。
下图展示了 DefNet 的改进效果,其能够使得网格更加贴合图像中的人体轮廓。

In-the-wild Domain Adaptation
由于文章的训练集都是在绿幕场景下采集的,而测试阶段使用的都是自然场景下的视频,因此由于光照条件和相机的不同,两者之间存在明显的差异。为了提高在自然图片下的表现,作者使用2D关键点和轮廓损失在单目测试图片上进行少量迭代以对网络微调,这样可以大大提高测试时的性能。

Results
文章所有实验都是在带有 NVIDIA Tesla V100 GPU 的计算机上进行,整个方法前向推理一次需要 50ms,其中 PoseNet 和 DefNet 分别消耗 25ms。在测试阶段使用现有的视频分割方法来去除输入图像中的背景。作者最后还对得到的网格顶点进行了高斯核为 5 帧的时序光滑。
下图展示了文章方法的一些图片结果。

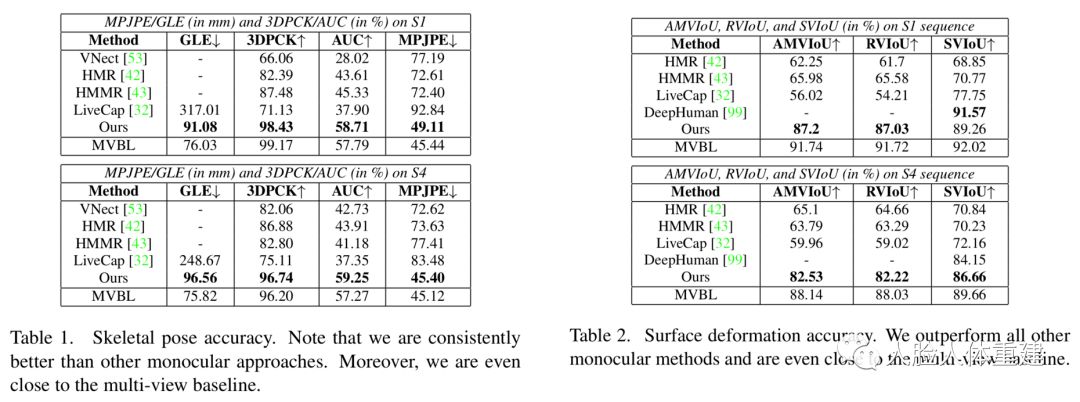
作者还将文章方法与之前方法包括 HMR [CVPR 2018]、LiveCap [SIGGRAPH 2019]、PIFu [ICCV 2019] 和 DeepHuman [ICCV 2019] 进行了定性和定量的比较,下面展示了定性比较的结果,本文的结果更加准确,在追踪阶段更加稳定鲁棒。

下面的两个表格展示了文章方法在骨架姿态准确性和重建网格准确性方面与其他方法的比较,文章方法都取得了更好地结果。
参考
-
DeepCap: Monocular Human Performance Capture Using Weak Supervision. Marc Habermann, Weipeng Xu, Michael Zollhoefer, Gerard Pons-Moll, Christian Theobalt. CVPR 2020 (Oral). -
LiveCap: Real-time Human Performance Capture from Monocular Video. Marc Habermann, Weipeng Xu, Michael Zollhoefer, Gerard Pons-Moll, Christian Theobalt. SIGGRAPH 2019. -
DeepHuman-基于彩色图片的人体重建
重磅!CVer-论文写作与投稿 交流群已成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满1250+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
麻烦给我一个在看!




