让Python性能超过一切语言?当然可行,为什么不可行呢?

本文的核心思想是,编程语言的语法简洁度和该语言的运行效率之间其实没有必然的联系,没有理由认为Python注定比C运行得慢。只要在LLVM层更好地实现针对硬件平台的性能优化,Python的执行效率完全可以与C相媲美。(当然这种优化技术上并不简单,所以目前还迟迟没有实现,但是理论上是可行的。)
此文承接“超越C语言元编程的LAPACK”和“大大优于C++元编程的LAPACK”。这两篇文章描述了使用编译器为你生成高性能代码的语言技巧。但是你真的需要编译器吗?
另一种方法是用普通的汇编程序设计。虽然它现在已经被吹到天上去了,但这种方法还是有两个主要缺陷。
1.汇编代码不可移植。
2.虽然使用现代工具变得更容易,但汇编程序设计仍然需要大量繁琐的工作。
值得庆幸的是,我们都生活在二十一世纪,这两个问题都已得到解决。
第一个解决方案是LLVM。 最初,它意味着“低级虚拟机”,这正是我们想要确保可移植性的原因。 简而言之,它需要一些用非常低级别的硬件无关语言编写的代码,并为特定的硬件平台返回一些高度优化的本机代码。使用LLVM,我们既具有低级编程的强大功能,又具有面向硬件的微优化的自动化。
第二个问题的解决方案是您想要的任何“脚本”语言。Scheme,Python,Perl,甚至bash或AWK都可以。它们都是为了消除繁琐的工作而诞生的。您每天用于自动化的所有内容都可用于生成高性能的代码。
让我们重复我之前在帖子中对C和C ++所做的相同实验。让我们生成一个完全内联的完全展开的解决方案,并将其嵌入到基准测试代码中。该计划如下。
1.使用Clang为基准生成LLVM中间代码,该基准应该测量名为solve_5的不存在的函数。
2.使Python在LLVM中生成线性求解器代码。
3.使用Python脚本劫持基准,用生成的求解器替换solve_5调用。
4.使用LLVM静态编译器将中间代码转换为机器代码。
5.使用GNU汇编器和Clang的链接器将机器代码转换为可执行的二进制文件。
这就是它在Makefile中的样子:

Python部分
我们需要Python中的线性求解器,就像我们使用C和C ++一样。 这里是:

当我们用数字运行时,我们得到了数字。但我们想要代码。因此,让我们制作一个假装成数字的对象来监视算法。写下算法希望它在准备好组装LLVM中间语言时执行的每个操作的对象。
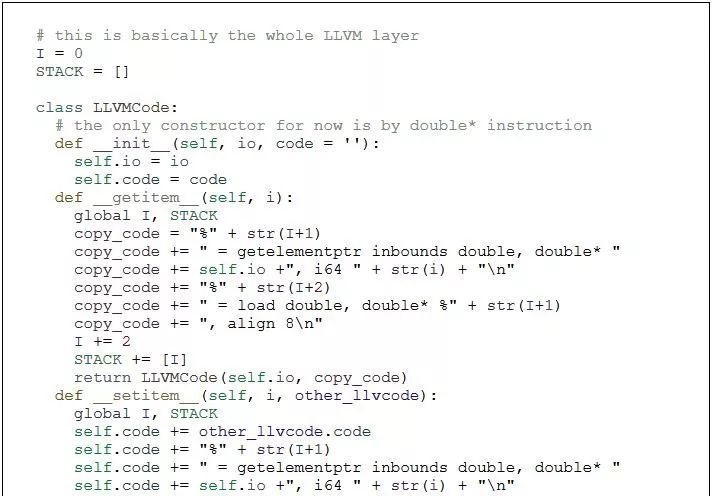
现在,当我们使用这种对象运行求解器时,我们得到了一个用LLVM中间语言编写的全功能线性求解器。然后我们将它放入基准代码中,看它有多快。
LLVM中的指令已编号,我们希望保留此枚举,因此将我们的代码插入到我们的基准测试中的功能并非易事。但它也不是很复杂。
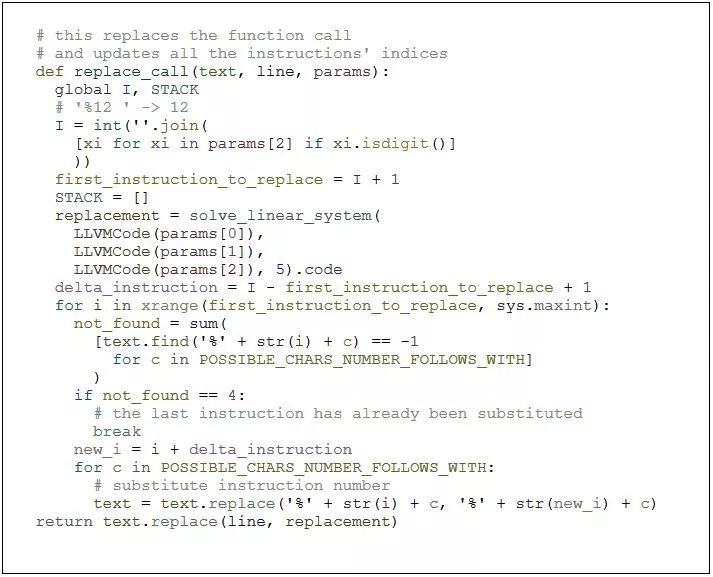
实现求解器的整段代码提供了Python-to-LLVM层,代码插入只有100行! 你可以在GitHub上看到它。
基准
基准测试本身在C中。当我们运行Makefile时,它对solve_5的调用被Python生成的LLVM代码所取代。

最值得注意的是Python脚本生成的超详细中间代码如何变成一些非常紧凑且非常有效的硬件代码。它也是高度超级标量化的。但它是否足以与C和C ++解决方案竞争?
以下是三种情况的近似数字:带有技巧的C,带有技巧的C ++和带有Python-LLVM。
C的技巧对Clang来说并不适用,因此测量GCC版本。 它平均运行大约70毫秒。
C ++版本是用Clang构建的,运行时间为60毫秒。
Python版本(此处描述的版本)仅运行55毫秒。

当然,这种加速并不是你想要追求的东西。但它表明你可以用Python编写的程序胜过用C或C ++编写的程序。您不必学习一些特殊语言来创建高性能的应用程序或库。
结论
我认为快速编译语言和慢速脚本语言之间的二分法是虚张声势。本机代码生成可能不是核心功能,而是类似可插拔选项。像一个图书馆。就像Numba for Python一样。想想它的好处:您可以用一种语言进行研究和快速原型设计,然后使用相同的语言生成高性能的代码。
高性能计算没有理由保留编译语言的特权。编译器只是用于代码生成的软机器。您可以使用您想要的任何语言生成代码。我相信如果你愿意,你可以教Matlab生成超快的LLVM代码。
所有测量均在Intel(R)Core(TM)i7-7700HQ CPU @ 2.80GHz上进行,代码使用clang版本3.8.0-2ubuntu4和g ++ 5.4.0编译,-march = native -O2。基准测试的源代码可在Github上获得。
英文原文:https://wordsandbuttons.online/outperforming_everything_with_anything.html
译者:游骑兵




