论文浅尝 - ACL2020 | Segmented Embedding of Knowledge Graphs

来源:ACL2020
链接:https://arxiv.org/pdf/2005.00856.pdf
摘要
知识图谱的嵌入愈发变成AI的热点之一,对许多下游任务至关重要(如个性化推荐、问答等)
同时,此模型强调两个关键特性:
利用足够多的特征进行交叉计算(分块)
同时在计算时,区别对称关系、非对称关系特征
本文的贡献有两个:
1.提出了轻量级框架SEEK,同时满足模型低复杂性、高表达力
2.提出了新的打分函数,同时完成特征整合、关系留存
1 引言
知识图谱 knowledge graph (KG)含有大量的实体和关系,表示为三元组(h, r, t),即(头实体 , 关系, 尾实体)
知识图谱嵌入(KGE)是为了,把大量相关的三元组映射到低维空间(保留潜在的语义信息)现有的KGE模型存在的问题:不能很好地平衡模型复杂性(模型参数的数量)和模型表达力(获取语义信息的能力),如下分为两类:
1)模型简单、表达有限
如:TransE、DistMult (简单易用,获取语义信息的能力欠佳)
2)模型复杂、表达力强
如:TransH、TransR、Single DistMult、ConvE、InteractE (模型复杂,需要大量向量计算,扩展性差)
本文的轻量级KGE框架SEEK有如下特性:特征有交互、保留关系特性、高效的打分函数、
特征交互:把嵌入空间分为多块,让各块之间有关联(而不用增加模型参数)
关系特性:同时保留对称的、非对称的关系(对称关系:双向关系;非对称关系:单向关系)
打分函数:结合上述两种特征,计算得分(来自于3个模型的打分函数:DistMult、HoIE、ComplEx)
2 SEEK的框架
各种打分函数是KGE(knowledge graph embedding )的基础,基于此我们建立了SEEK本文提出的SEEK模型的参数和TransE、DistMult一样少,却能更好地表达图谱。
2.1 得分函数的Design
SEEK在得分函数的设计中,迭代了四个版本,逐一看下。
f1: Multi-linear Dot Product:
下图是公式,具体是计算头实体h,尾实体 t,关系 r 之间的点乘。这个是以下公式的基础。
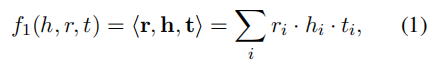
f2: Multi-linear Dot Product Among Segments:
将嵌入维度划分为多段,考虑段与段之间的信息交互。其中 k 是段的个数,d是维度,x 代表关系向量 r 切分后的第 x 段,y 代表头实体向量 h 切分后的第 y 段,w 代表尾实体向量 t 切分后的第 w 段。
例如,我们可以将关系向量嵌入表示为:
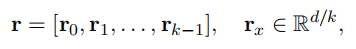
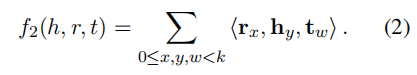
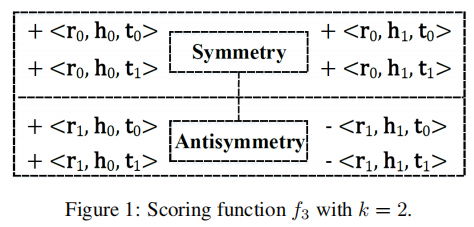
f3: Modeling both Symmetric and Antisymmetric Relations:
我们需要考虑关系的对称性和反对称性。
对于f2模型来说,当给一个具有对称性的关系 r 和一个三元组 (h, r, t),存在f2(h, r, t) = f2(t, r, h),但是对于给定一个反对称关系 r ,仍然存在f2(h, r, t) = f2(t, r, h),这就是不对的,因为此时的 f2(t, r, h)是一个错的三元组。
为了考虑关系的对称性和反对称性,将关系向量 r的切割分为奇数和偶数两部分,并引入变量 Sx,y,偶数部分能够捕捉对称性,并且奇数部分能够捕捉反对称性。
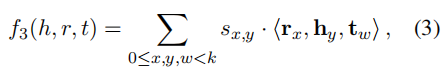
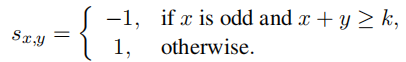
其中Sx,y控制了关系向量的切割点为奇数与偶数时三元组的正负关系。下面是分成 2 段的一个例子
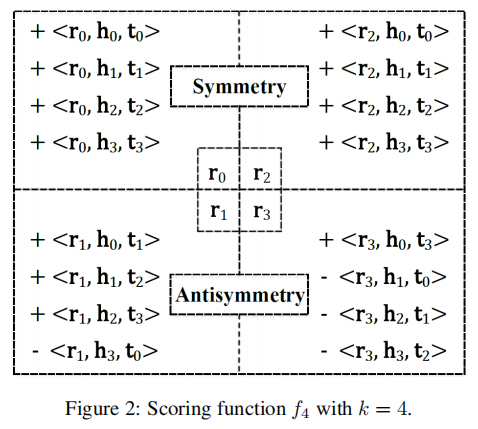
f4: Reducing Computing Overheads
优化计算复杂度。
f3 算法的时间复杂度是O(n2)级别的,还是较高,f4优化了其复杂度,降至O(n2)。
对尾实体 t 引入变量Wx,y,具体的计算公式如下,也是分为奇数偶数部分, k 为分割段数,Sx,y计算和f3一样。
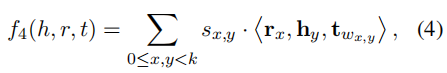
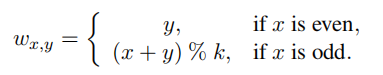
其中由于Wx,y的计算只与x和y存在关系,因此时间复杂度降为了O(n2),下面是分成 4 段的一个例子
r 的下标为偶数的情况下,考虑了对称性,Sx,y计算和f3一样,都是正(+),偶数的情况下 t 也没有变化。
r 的下标为奇数的情况下,考虑了反对称性,Sxy 计算和 f3 一样,x + y 大于等于 4 的时候为负,其余为正,t 的计算是 (x + y) % k 取余,替换尾实体,段之间的特征交互随着k的增大而增多。
2.2 模型训练
损失函数为-log函数,L2正则化,激活函数sigmoid
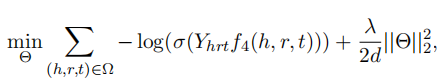
Θ:向量嵌入时的参数
Ω:图谱中本来的三元组、生成的负样本三元组
梯度的计算公式:
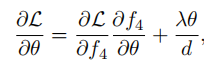
L目标函数,Θ参数,对f4求导时:
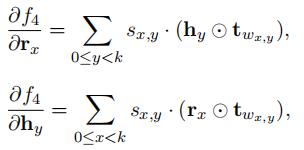
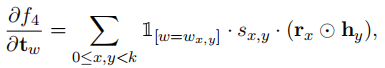
3 实验效果
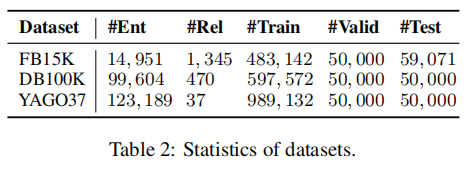
验证效果采用的数据集是 FB15K,DB100K 和 YAGO37,FB15K 是 Freebase 的子集,DB100K来自DBpedia,YAGO37 来自 YAGO3,具体数据如下:
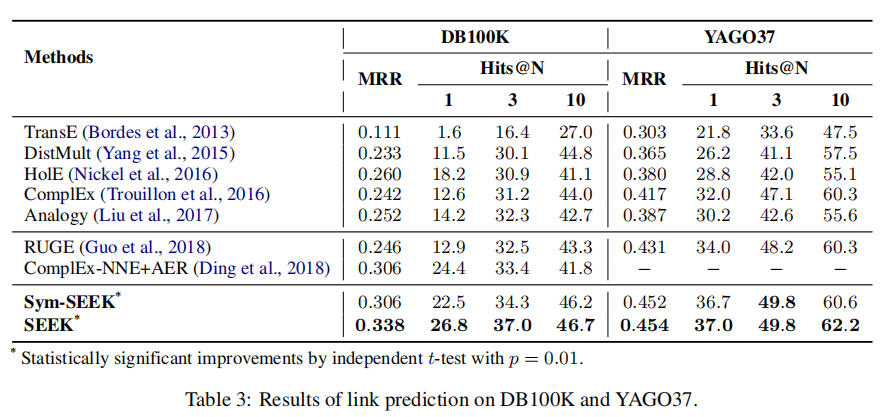
采用的评测任务是链接预测,在三个数据集上面的效果如下图,其中k和d 的设置在三个数据集上面都不一致,是采用网格搜索找到的最优超参数。
评测指标,MRR:所有正确实例排名的倒数的平均值;Hits@N:正确实例的排名中不大于 N 的比例。
4 总结
本文提出一个轻量级框架SEEK,利用打分函数,在不增加模型参数的情况下,提高了模型对知识图谱的嵌入表示效果。主要原理是:1.分块并利用不同块之间的特征交叉计算 2.区分并保留多种关系 。同时SEEK是一个普适性更强的模型,DistMult, ComplEx, HolE可作为SEEK的特例。本文从效率、效果、鲁棒性方面阐述了SEEK的性能。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 网站。



