如何使用 CGI 脚本生成网页 | Linux 中国
作者 | David Both
译者 | Lv Feng (ucasFL) 🌟 🌟 🌟 🌟 🌟 共计翻译:64 篇 贡献时间:537 天
通用网关接口(CGI)提供了使用任何语言生成动态网站的简易方法。
回到互联网的开端,当我第一次创建了我的第一个商业网站,生活是如此的美好。
我安装 Apache 并写了一些简单的 HTML 网页,网页上列出了一些关于我的业务的重要信息,比如产品概览以及如何联系我。这是一个静态网站,因为内容很少改变。由于网站的内容很少发生改变这一性质,因此维护起来也很简单。
静态内容
静态内容很简单,同时也很常见。让我们快速的浏览一些静态网页的例子。你不需要一个可运行网站来执行这些小实验,只需要把这些文件放到家目录,然后使用浏览器打开。你所看到的内容将和通过 Web 服务器提供这一文件看到的内容一样。
对于一个静态网站,你需要的第一件东西就是 index.html 文件,该文件通常放置在 /var/www/html 目录下。这个文件的内容可以非常简单,比如可以是像 “Hello, world” 这样一句短文本,没有任何 HTML 标记。它将简单的展示文本串内容。在你的家目录创建 index.html 文件,并添加 “hello, world” 作为内容(不需要引号)。在浏览器中通过下面的链接来打开这一文件:
file:///home/<你的家目录>/index.html
所以 HTML 不是必须的,但是,如果你有大量需要格式化的文本,那么,不用 HTML 编码的网页的结果将会令人难以理解。
所以,下一步就是通过使用一些 HTML 编码来提供格式化,从而使内容更加可读。下面这一命令创建了一个具有 HTML 静态网页所需要的绝对最小标记的页面。你也可以使用你最喜欢的编辑器来创建这一内容。
echo "<h1>Hello World</h1>" > test1.html
现在,再次查看 index.html 文件,将会看到和刚才有些不同。
当然,你可以在实际的内容行上添加大量的 HTML 标记,以形成更加完整和标准的网页。下面展示的是更加完整的版本,尽管在浏览器中会看到同样的内容,但这也为更加标准化的网站奠定了基础。继续在 index.html 中写入这些内容并通过浏览器查看。
<!DOCTYPE HTML PUBLIC "-//w3c//DD HTML 4.0//EN">
<html>
<head>
<title>My Web Page</title>
</head>
<body>
<h1>Hello World</h1>
</body>
</html>
我使用这些技术搭建了一些静态网站,但我的生活正在改变。
动态网页
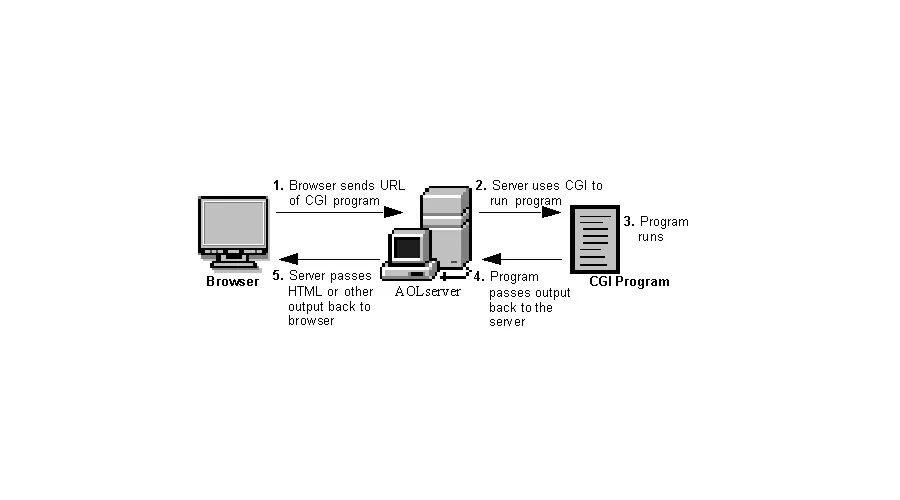
我找了一份新工作,这份工作的主要任务就是创建并维护用于一个动态网站的 CGI(公共网关接口[1])代码。字面意思来看,动态意味着在浏览器中生成的网页所需要的 HTML 是由每次访问页面时不同的数据所生成的。这些数据包括网页表单中的用户输入,以用来在数据库中进行数据查找,结果数据被一些恰当的 HTML 包围着并展示在所请求的浏览器中。但是这不需要非常复杂。
通过使用 CGI 脚本,你可以创建一些简单或复杂的交互式程序,通过运行这些程序能够生成基于输入、计算、服务器的当前条件等改变的动态页面。有许多种语言可以用来写 CGI 脚本,在这篇文章中,我将谈到的是 Perl 和 Bash ,其他非常受欢迎的 CGI 语言包括 PHP 和 Python 。
这篇文章不会介绍 Apache 或其他任何 web 服务器的安装和配置。如果你能够访问一个你可以进行实验的 Web 服务器,那么你可以直接查看它们在浏览器中出现的结果。否则,你可以在命令行中运行程序来查看它们所创建的 HTML 文本。你也可以重定向 HTML 输出到一个文件中,然后通过浏览器查看结果文件。
使用 Perl
Perl 是一门非常受欢迎的 CGI 脚本语言,它的优势是强大的文本操作能力。
为了使 CGI 脚本可执行,你需要在你的网站的 httpd.conf 中添加下面这行内容。这会告诉服务器可执行 CGI 文件的位置。在这次实验中,不必担心这个问题。
ScriptAlias /cgi-bin/ "/var/www/cgi-bin/"
把下面的 Perl 代码添加到文件 index.cgi,在这次实验中,这个文件应该放在你的家目录下。如果你使用 Web 服务器,那么应把文件的所有者更改为 apache.apache,同时将文件权限设置为 755,因为无论位于哪,它必须是可执行的。
#!/usr/bin/perl
print "Content-type: text/html\n\n";
print "<html><body>\n";
print "<h1>Hello World</h1>\n";
print "Using Perl<p>\n";
print "</body></html>\n";
在命令行中运行这个程序并查看结果,它将会展示出它所生成的 HTML 内容
现在,在浏览器中查看 index.cgi 文件,你所看到的只是文件的内容。浏览器需要将它看做 CGI 内容,但是,Apache 不知道需要将这个文件作为 CGI 程序运行,除非 Apache 的配置中包括上面所展示的 ScriptAlias 定义。没有这一配置,Apache 只会简单地将文件中的数据发送给浏览器。如果你能够访问 Web 服务器,那么你可以将可执行文件放到 /var/www/cgi-bin 目录下。
如果想知道这个脚本的运行结果在浏览器中长什么样,那么,重新运行程序并把输出重定向到一个新文件,名字可以是任何你想要的。然后使用浏览器来查看这一文件,它包含了脚本所生成的内容。
上面这个 CGI 程序依旧生成静态内容,因为它总是生成相同的输出。把下面这行内容添加到 CGI 程序中 “Hello, world” 这一行后面。Perl 的 system 命令将会执行跟在它后面的 shell 命令,并把结果返回给程序。此时,我们将会通过 free 命令获得当前的内存使用量。
system "free | grep Mem\n";
现在,重新运行这个程序,并把结果重定向到一个文件,在浏览器中重新加载这个文件。你将会看到额外的一行,它展示了系统的内存统计数据。多次运行程序并刷新浏览器,你将会发现,内存使用量应该是不断变化的。
使用 Bash
Bash 可能是用于 CGI 脚本中最简单的语言。用 Bash 来进行 CGI 编程的最大优势是它能够直接访问所有的标准 GNU 工具和系统程序。
把已经存在的 index.cgi 文件重命名为 Perl.index.cgi,然后创建一个新的 `index.cgi 文件并添加下面这些内容。记得设置权限使它可执行。
#!/bin/bash
echo "Content-type: text/html"
echo ""
echo '<html>'
echo '<head>'
echo '<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">'
echo '<title>Hello World</title>'
echo '</head>'
echo '<body>'
echo '<h1>Hello World</h1><p>'
echo 'Using Bash<p>'
free | grep Mem
echo '</body>'
echo '</html>'
exit 0
在命令行中执行这个文件并查看输出,然后再次运行并把结果重定向到一个临时结果文件中。然后,刷新浏览器查看它所展示的网页是什么样子。
结论
创建能够生成许多种动态网页的 CGI 程序实际上非常简单。尽管这是一个很简单的例子,但是现在你应该看到一些可能性了。
via: https://opensource.com/article/17/12/cgi-scripts
作者:David Both[3] 译者:ucasFL 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出





