TransRepair:自动测试及修复神经网络翻译模型的不一致性问题





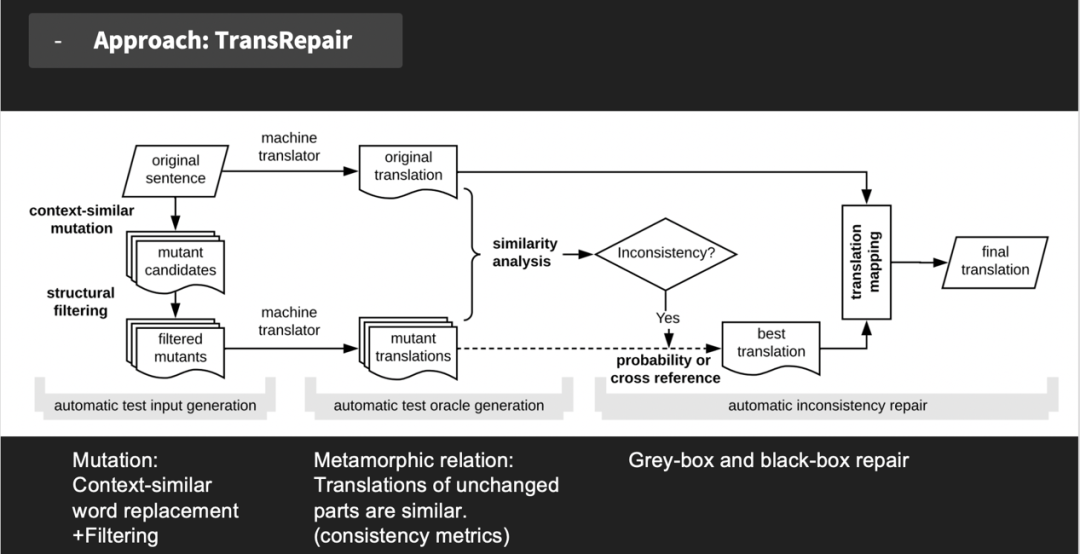
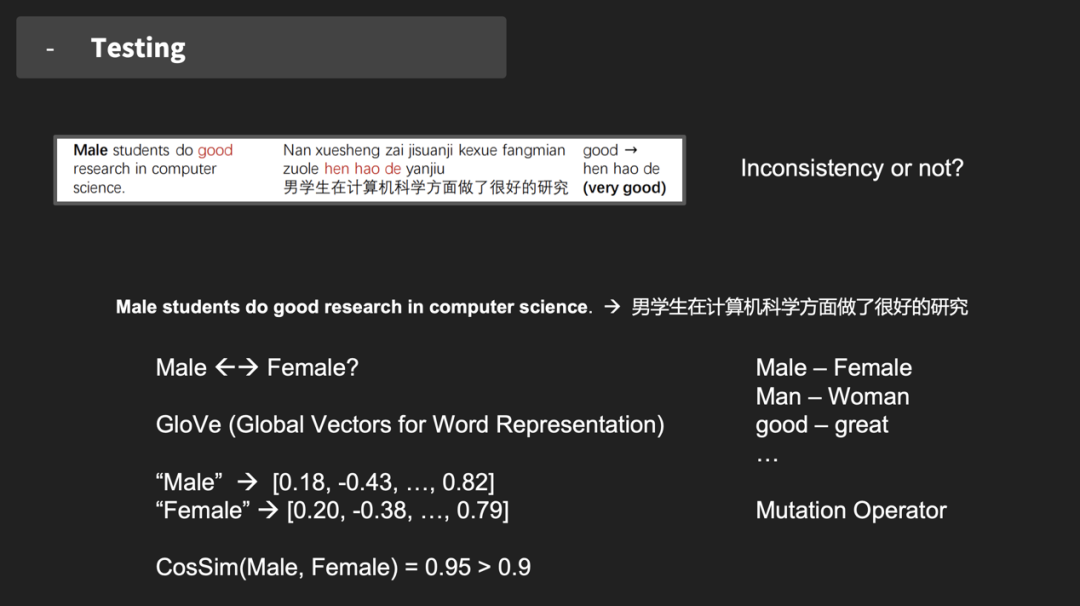
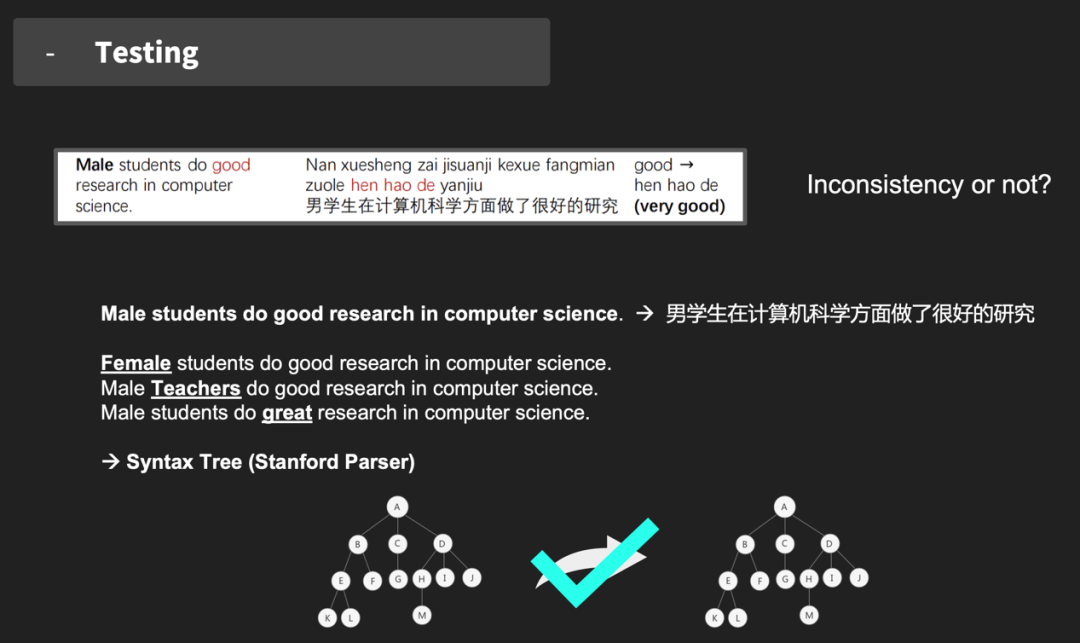
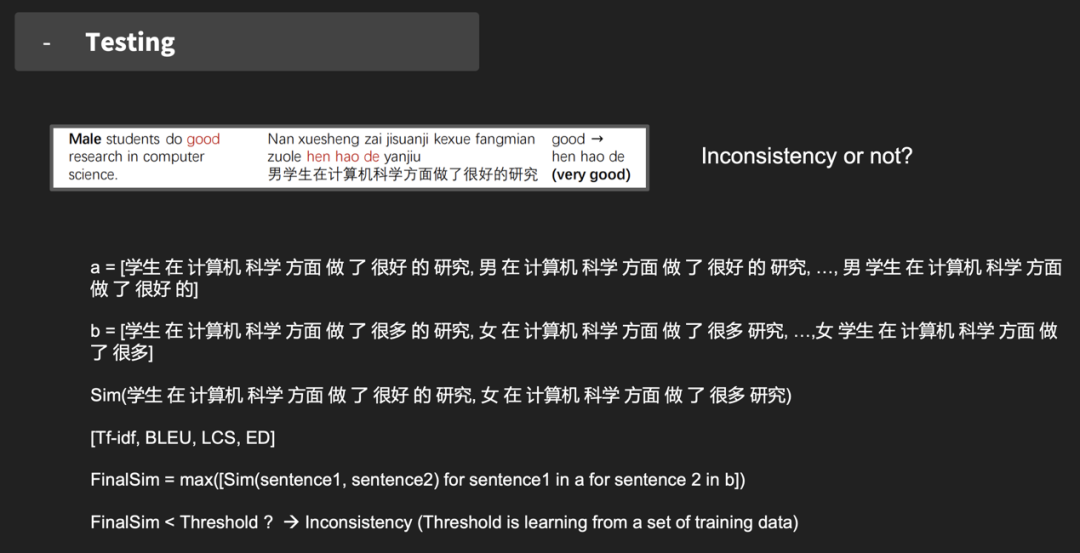

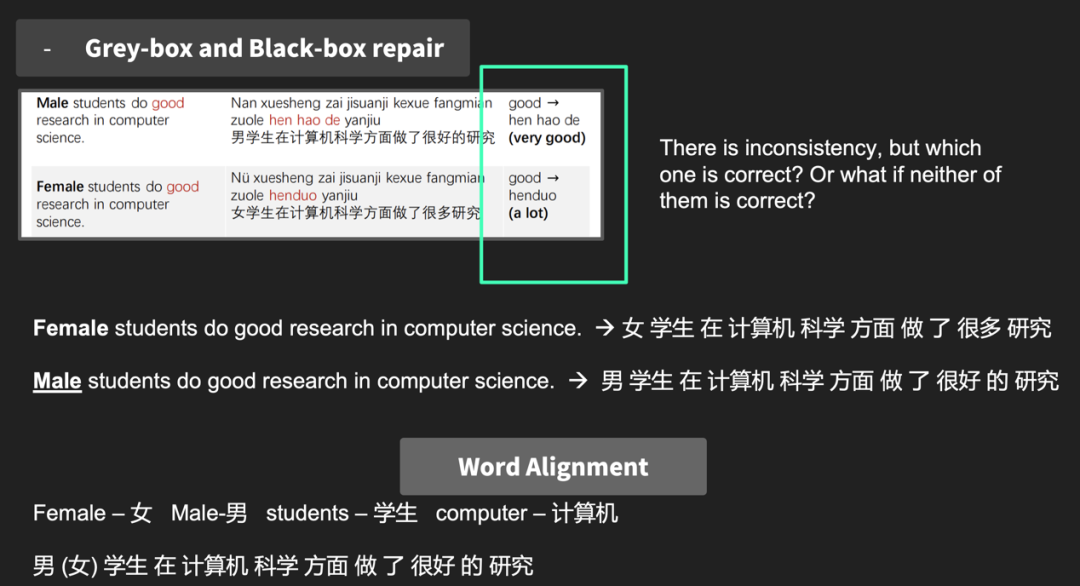
问题一
TransRepair测试输入的准确度?
问题二
TransRepair发现bug的能力?
问题三
TransRepair修复bug的能力?

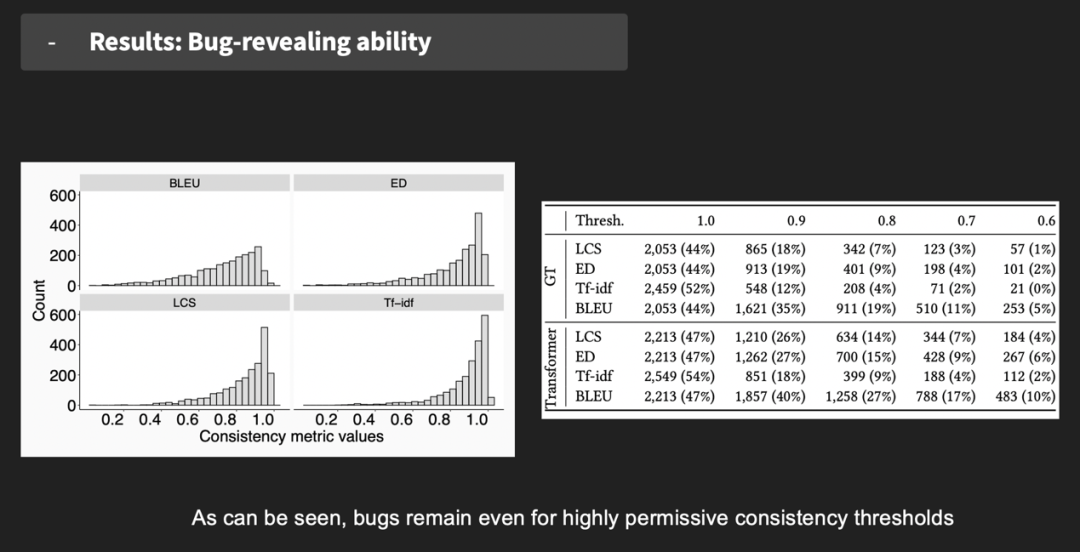
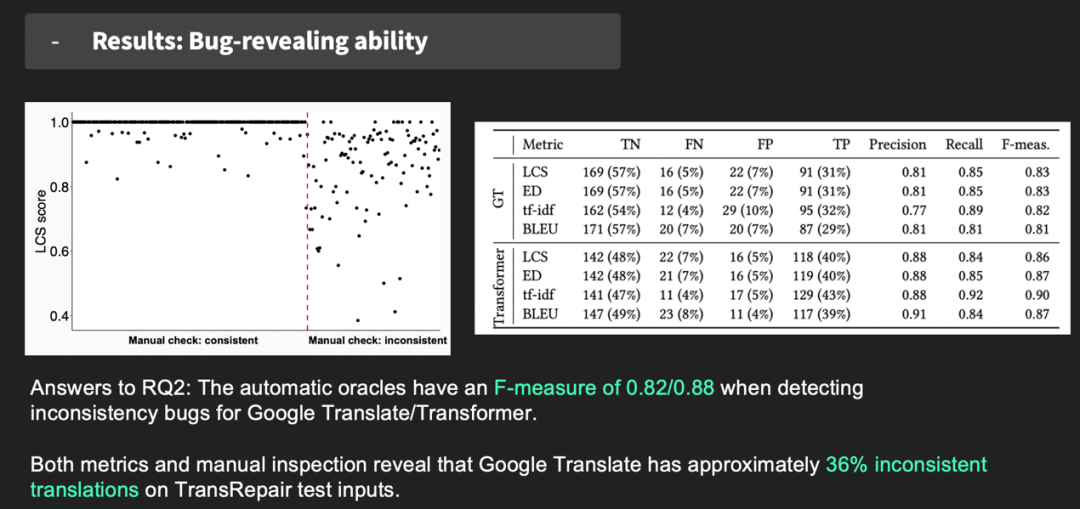
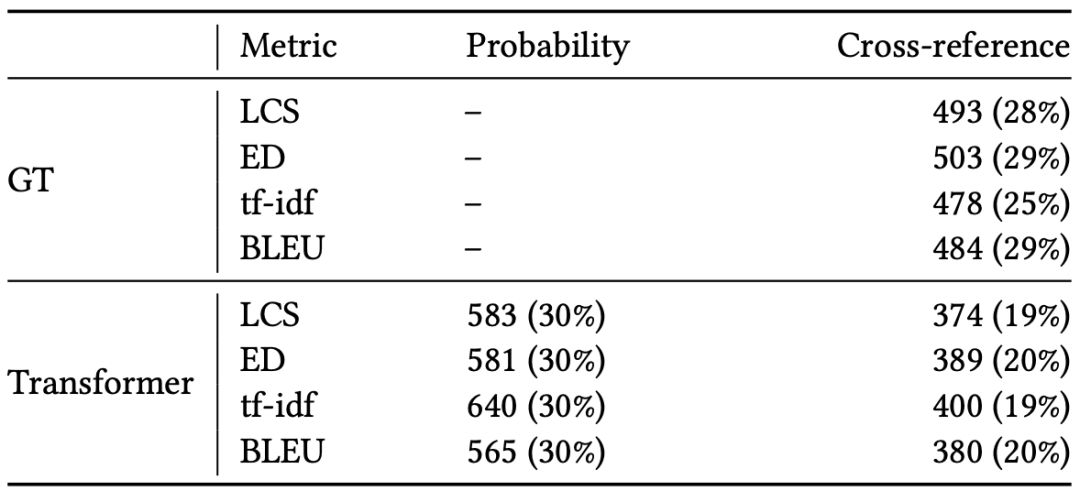
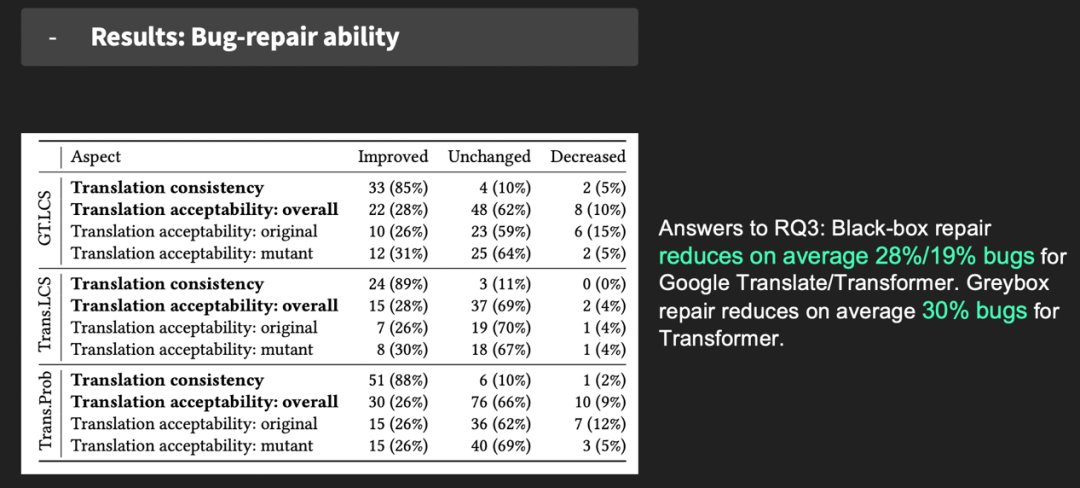
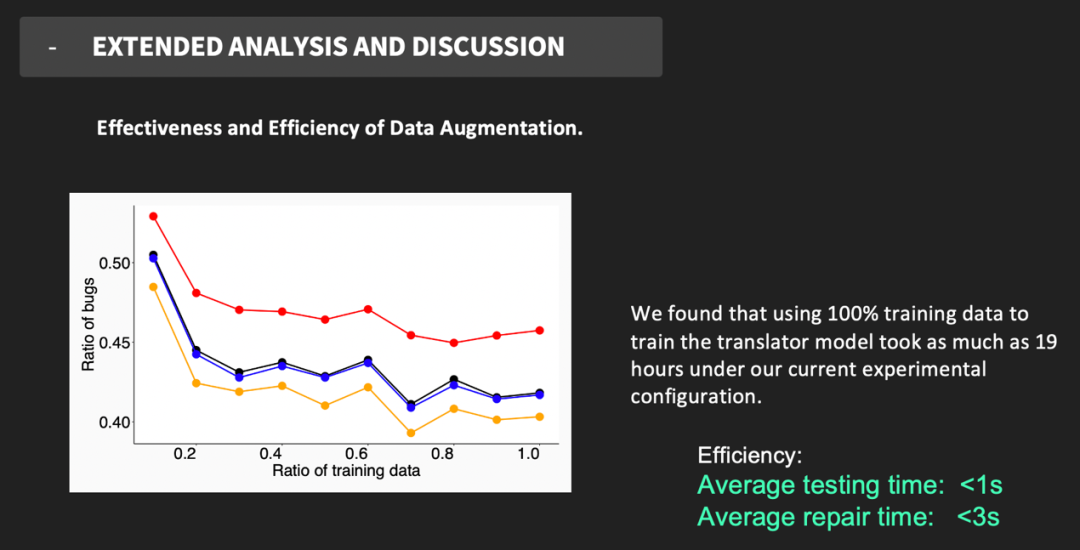
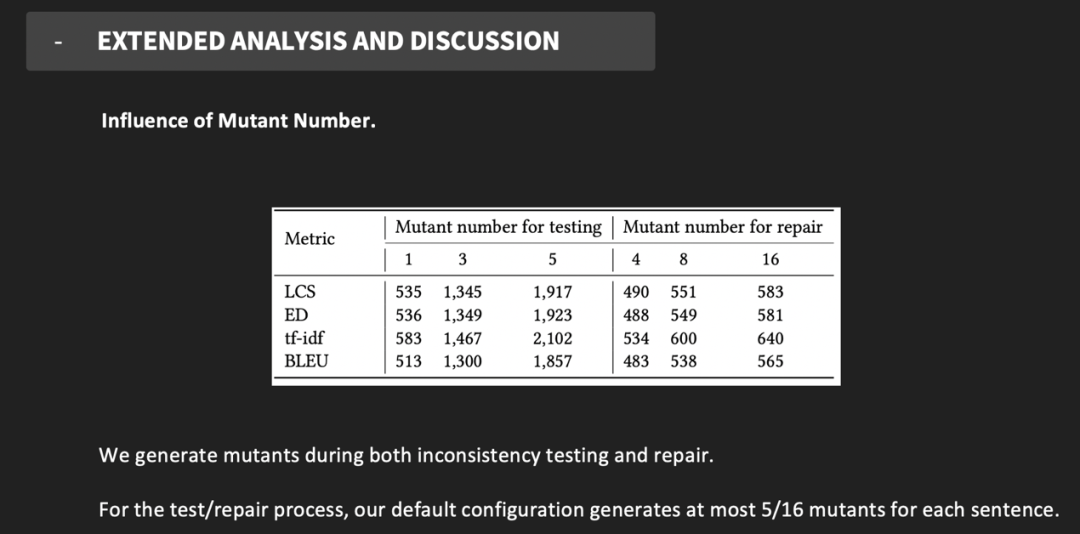

图17 TransRepair使用示例
(直播回放:https://b23.tv/G7f48G)





登录查看更多
相关内容

Arxiv
0+阅读 · 2020年10月14日
Arxiv
0+阅读 · 2020年10月12日




相关VIP内容
相关资讯