阿里妈妈点击率预估中的长期兴趣建模

作者:卞维杰 皮琪 任侃 周国睿 朱小强
整理:林志宏
来源:DataFunTalk
出品:DataFun
注:欢迎转载,转载请留言。
导读:CTR 预估作为广告和推荐领域的基础技术,在用户行为较丰富的场景,一般通过建模用户历史行为序列来挖掘用户兴趣。历史行为的时间跨度越长,用户兴趣偏好更稳定,因此当我们希望刻画用户长期兴趣时,需要引入更多的行为数据,这给在线服务引擎和算法模型提出了一定挑战。我们通过算法、工程 Co-Design 的视角设计了一套增量计算服务框架,解决了长期兴趣建模带来的存储和在线服务压力,并在此基础上提出了两种 Memory Network,分别从时间和多峰兴趣两个角度去建模用户长期兴趣,从而提升了模型预估准度,带来定向广告业务收益的上升。
本文将从以下三部分介绍阿里妈妈关于点击率预估中的长期兴趣建模的工作实践。
相关背景
主要工作
实践总结
——相关背景——
❶ 业务背景
阿里妈妈定向技术团队主要负责手淘客户端大部分的定向广告,广告的业务形态包括:焦点图广告、单品广告卡片以及诸如视频的内容化广告等,手淘场景主要有:首焦、猜你喜欢以及例如物流详情等购后链路。广告推送模式与推荐相似,就是进行用户的个性化点击率预估,然后结合广告主出价,进行 ECPM 排序,取 top k 进行展示,k 值根据广告位的数量而定。
❷ 技术现状
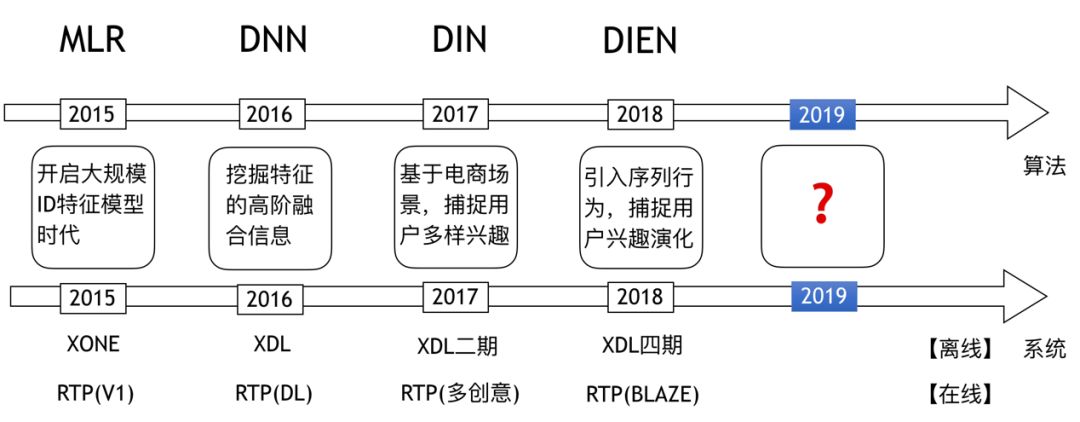
阿里妈妈定向技术团队技术迭代的路线如图2所示。在2015年的时候从 LR 升级到了分片线性模型 MLR,开启了大规模 ID 特征模型时代;2016年引入 DNN 模型,利用深度学习挖掘特征的高阶融合信息;2017年提出了 DIN 模型,通过引入序列信息,基于电商场景,捕捉用户的多峰兴趣;2018年创造出了 DIEN 模型,通过 GRU 时序结构,引入序列行为,捕捉用户兴趣的演化。每一次技术创新的背后都是在挖掘数据的价值。与此同时,每次技术创新的背后都有系统服务升级的支持,训练引擎从 XONE 升级到 XDL 一期、二期、四期,在线服务引擎也从 RTP 的1.0版本逐步升级到高性能 RTP 的 BLAZE 版本。可以总结出整体的技术发展思路是:数据价值的挖掘推动算法模型的创新,而算法模型的创新又推动了系统服务的升级。按照这样的思路,2019年进行的技术迭代就是用户长期兴趣的挖掘。
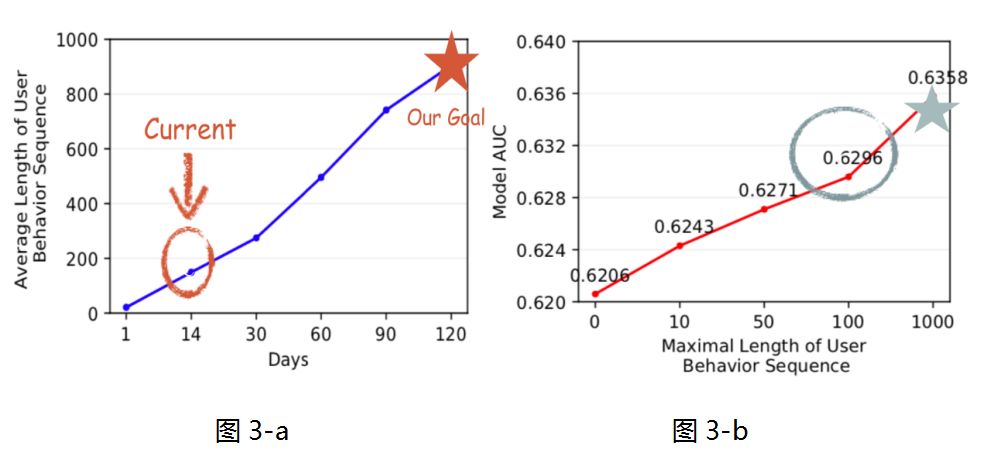
在谈长期兴趣挖掘的价值之前,得先看看目前团队建模能力的现状,首先 DIN 模型与 DIEN 模型都通过用户的历史行为挖掘用户兴趣,其中 DIN 模型对用户的原始行为序列进行 attention 操作,获取用户相关的兴趣,进行用户的点击率预估,而 DIEN 模型是通过 GRU 对用户原始行为序列进行时序的建模,但是由于一定的系统瓶颈,可以处理的最大历史行为长度为100。从图 3-a 可以看出历史行为长度100仅对应用户14天的行为,当用户行为窗口增加到120天时,用户历史行为长度爆炸到了1000。为了看出长期历史行为的价值,我们做了简单的实验来评估不同长度用户行为引入 CTR 预估模型后的离线表现,我们采用 DNN 模型,把行为序列特征 ( 包括用户点击的 item 以及 item 的属性特征等 ) 进行简单的 embedding sum 之后输入模型,如图 3-b 所示,利用1000长度用户行为信息相比100长度,能够带来 0.6% GAUC 的提升。这里采用的 GAUC 是以用户粒度为 group 计算的 AUC,然后根据用户的 frequency 进行 weight sum。其中0.6%离线提升对在线业务有重大意义,由此可见长期历史行为具有显著的利用价值。
❸ 系统瓶颈
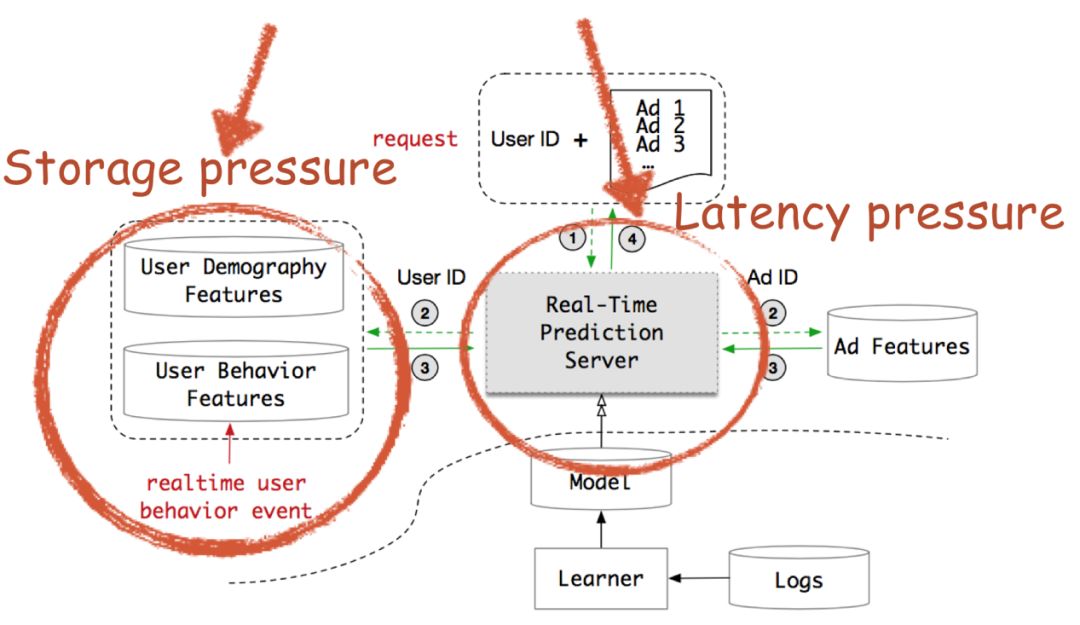
图4展示的是在线 RTP 引擎,当一个 request 过来的时候,会打分大概400个广告,我们根据 Ad ID 去 Ad Feature 这个索引库里面提取广告特征,根据 User ID 去提取 User 的 Demography 特征以及行为序列特征,然后送入模型进行打分,排序后将广告返回给用户。点击率预估与大部分工业应用一样需要一个实时的响应。在阿里这个电商平台里,点击率预估系统不仅面临高并发的请求,还需要在一个极短的时间内进行响应。我们的 DIN 和 DIEN 模型由于原始序列和 Target 均有显式交互,因而无法解耦计算,当行为序列长度为100时,DIN 和 DIEN 现有的复杂度逼近计算极限,由于计算资源的约束,在现有的模型下想把行为序列往1000扩展是不可能的。另外一方面,用户的行为特征是存储在线上服务引擎,阿里有亿级的用户,如果每个用户存储的行为序列特征由100扩展到1000,将带来极大的存储消耗和模型服务 IO 问题。因此我们面临着延迟约束和存储限制的系统瓶颈。
为了解决以上的系统瓶颈,必须从一个 high level 的角度进行思考,我们通过 Co-Design 算法&系统的突破,得出以下三个突破点:
计算解耦;
存储压缩;
增量复用。
——主要工作——
❶ 整体设计
围绕着计算解耦、存储压缩、增量复用这三点我们进行了如下的整体设计。首先,在模型的选择方面,我们选择了 Memory Network 来进行我们基础模型的构建,Memory Network 有以下的几点好处:
1. 自组织的用户兴趣聚合,因为它可以通过 content-based address 的方式将相似的宝贝映射到一个相同的 Memory 中;
2. 有限的 Memory Slot 换取无限的行为历史,只需少数几个 Memory Slot 就可表达上千个行为的信息;
3. 实时动态 Memory 向量更新,避免重复 Memory 计算。
围绕这个模型能力,我们进行以下的系统设计:
1. 异步计算模块,实现兴趣向量独立更新;
2. 兴趣向量的存储,不仅服务在线计算,而且辅助兴趣向量增量更新。
我们将整体的设计细节总结成如下两篇学术论文:
1. SIGIR 2019:Lifelong Sequential Modeling with Personalized Memorization for User Response Prediction;
2. KDD 2019 :Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction
❷ 系统改进
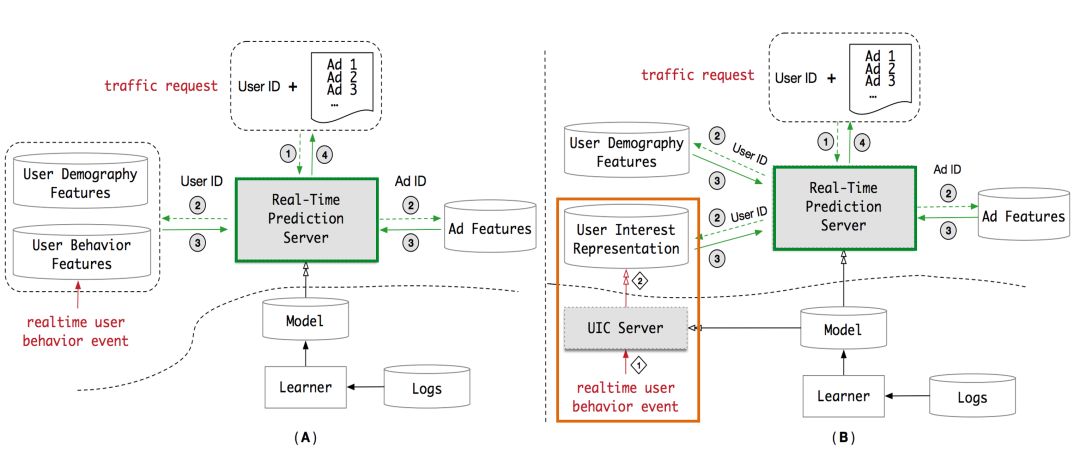
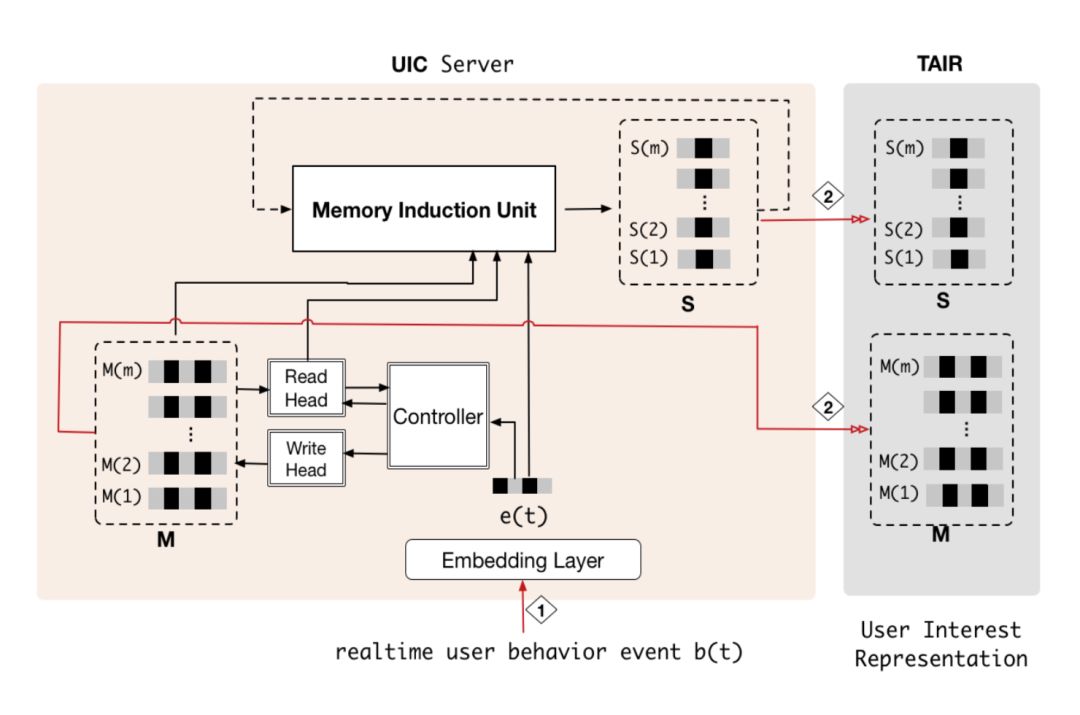
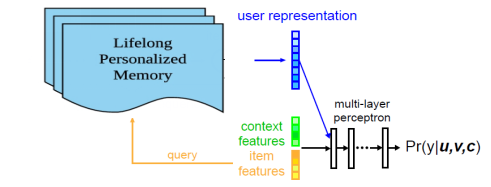
在原有的 RTP 系统 ( 左图 ) 的基础上我们引入了 UIC 模块 ( 右图 ),即用户兴趣中心,它能实现我们想要的三个能力:异步计算、兴趣向量的存储以及增量更新计算。在原有 RTP 系统流程的基础上,新系统把取用户行为特征改成取用户兴趣向量,直接对兴趣向量进行 attention 操作,辅助点击率预估,同时当有实时行为进来的时候,UIC 会直接增量更新用户兴趣向量。
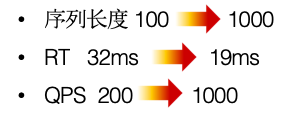
对比新老系统,同时采用 DNN+ 行为特征 embedding sum 的结构,性能的提升如图6所示。
❸ 算法创新
在介绍算法创新之前,首先介绍记忆网络。记忆网络主要有 facebook 的 Memory Network ( 和 attention 模型类似 ) 以及 Google 的 Neural Turing Machines:NTM ( 它引入的是 external memory,显式对行为序列进行存储,帮助建模长期依赖 ) 两种。NTM 相比 LSTM 和 GRU 更适合建模长期序列,后两者随着序列的增长存在梯度弥散等问题。记忆网络的优势包括:适合建模长期依赖;Memory 向量的存储避免直接存储长期行为序列,缓解存储压力;Memory 的读操作相比 GRU+Attention 减小了计算压力。
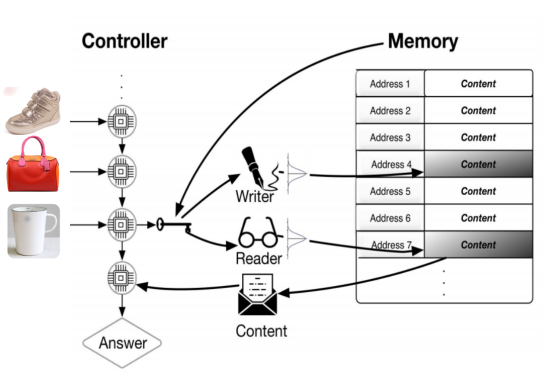
NTM 版本的 Memory Network 存在一个 Controller 模块,控制着 Memory 的读写。下图为一个电商场景下的 NTM 示意图,假设一个用户浏览了鞋、包和杯子,Controller 会在发生行为时产生一个写头来实时更新 Memory,当物品相似的时候会写到一个相同的 Memory slot ( content-based addres 机制 ),当一个请求过来的时候会产生一个读头来获取兴趣向量,辅助线上 ctr 预估。
在 Memory Network 的基础上,我们进行了算法创新设计,发表了两篇论文。分别从不同的视角去构建用户兴趣向量。其中 MIMN ( Multi-channel user Interest Memory Network ) 是从多峰兴趣角度进行记忆模块构建,因为在电商环境用户的兴趣广泛。而 HPMN ( Hierarchical Periodic Memory Network ) 则从时间维度进行记忆模块构建,因为不同的商品存在不同的时间属性。
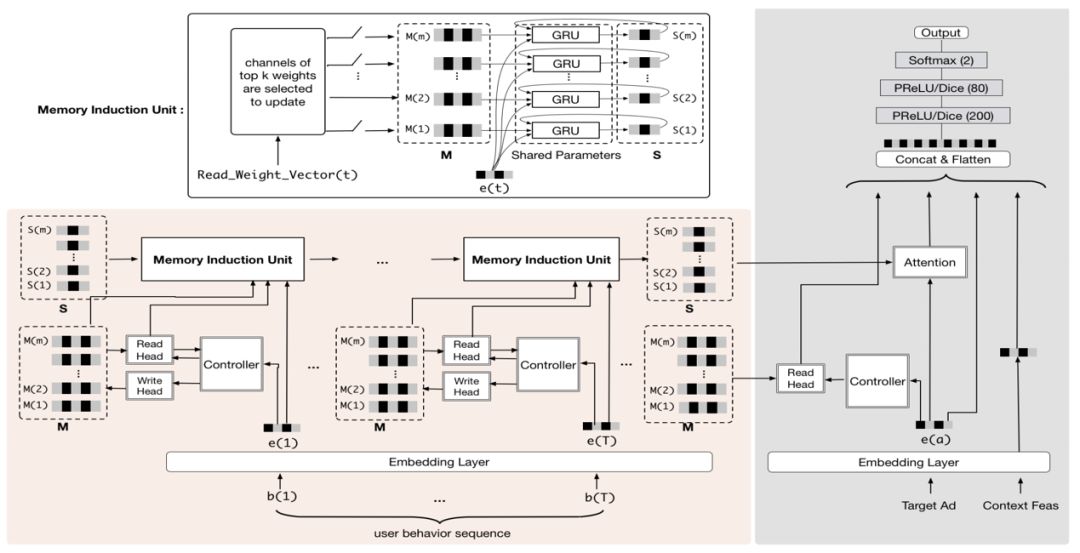
首先介绍一下 MIMN 的设计,它借鉴 NTM 的思路,采用 memory-based model 建模,在 GRU 时序模型的基础上引入 external memory 向量,显式存储行为信息。我们提出了两个创新点:利用 Memory utilization regularization 进行信息记录最大化以及使用 Memory induction unit 进行兴趣演化和高阶兴趣提取的建模。模型概览图如图8所示,我们在整个应用中引入了时序模块,它的基础是 NTM 加 Memory induction unit,在训练的时候会通过 target 对时序模块产生兴趣向量,与其他的静态特征一同输入 DNN 网络进行点击率预估模型训练,当训练完成之后,会进行分开部署,右边灰色部分会部署到线上实时 RTP 服务引擎,左边粉红色部分会部署到 UIC server 里面。
关于 NTM 模型细节方面,它包括几个关键部分:Controller,读写头 ( 一般集成在 Controller 里 ) 以及 Memory。
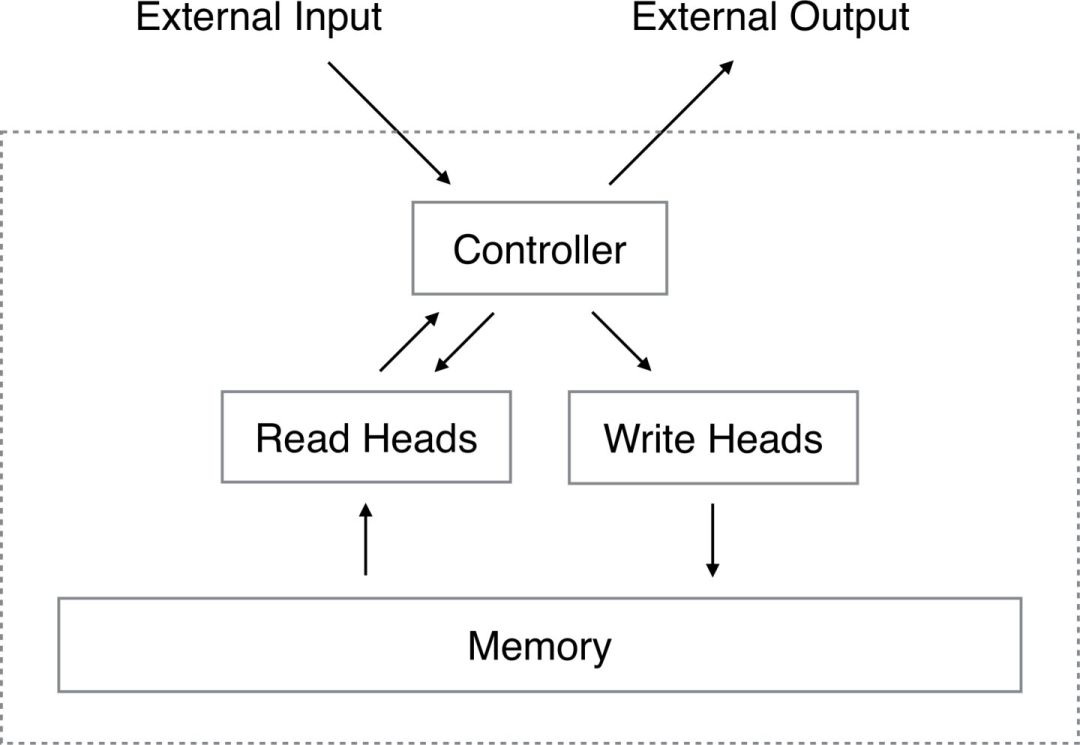
当一个新的输入进来的时候 Controller 会产生一个 Key Vector,它可以与 Memory 进行交互得到读权重向量,交互过程与注意机制相似,但是有一点与注意力机制不同,即 attention 是在做点积操作,而 NTM 中是在计算余弦相似度,它是为了避免 memory 之间 scale 具有差距,产生马太效应。例如一个 memory 的 scale 很大,在点积操作下产生的 score 也很大,以致于它长期具有一个很大的 weight。当我们得到每个 memory 的 read weight 之后,我们对每个 memory 进行 weighted sum 可以得到响应向量。详细计算公式如下。
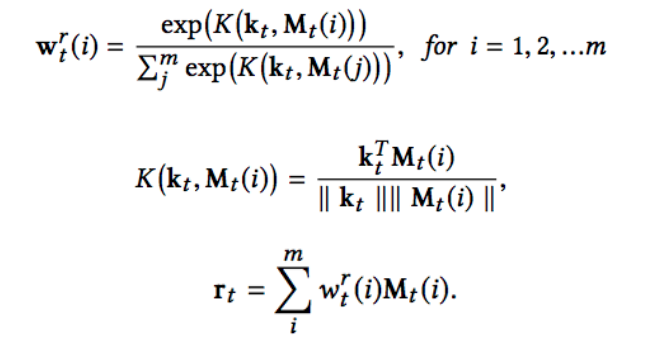
Memory 更新方面,write weight 计算等价于 read weight,不同的地方在于 Controller 会产生 erase 向量和 add 向量,这两个向量会分别与 write weight 相乘得到 erase 矩阵和 add 矩阵,Memory 更新公式如下,减去想擦除的信息加上想增加的信息就得到新的 Memory。
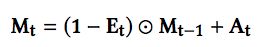
其中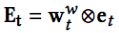
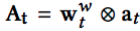
为了有效提高 memory 利用率,在 NTM 的基础上,我们加入了 Memory Utilization regularization 的考虑,希望约束不同 memory slot 中的写入方差。NTM 使用基于内容的寻址方式,会导致部分的 slot 写入利用率很低 ( 定义为:累计的写入权重 ),如图10所示,绿色的柱条是亚马逊数据集使用原始的 NTM 得到的各 slot 的利用率,可以看出最后两个 slot 利用率都很低,线上使用36个 slot 的时候部分 slot 利用率很低的现象更为严重。
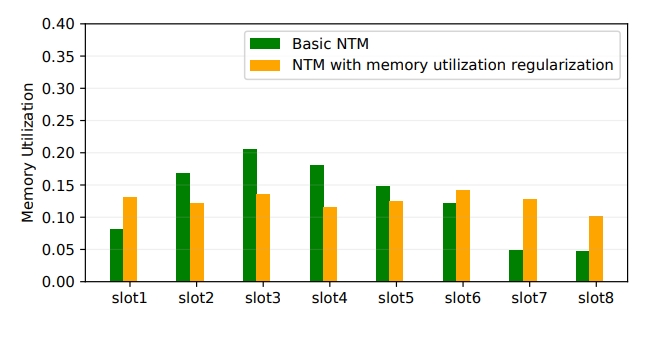
图10中橙色的柱条为经过 Memory Utilization regularization 之后得到的 memory slot。
为了平衡各 slot 的使用率,我们对 write weight 进行了 re-weight 的操作,即累积之前的 write weight 得到 gt 向量,经过转换后得到转移概率矩阵 Pt 再乘以 write weight 向量得到改写后的写入权重。改写权重的计算方式如下:
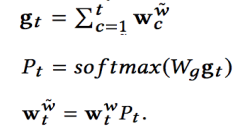
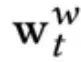
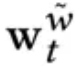
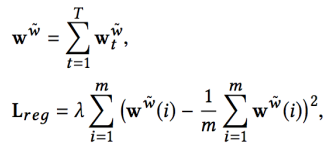
M 表示 slot 的数量,Lreg 能够减少不同 memory slot 利用率的方差。
NTM 算法 memory 通常用来存储原始数据信息,遗失了对于更高阶的信息的捕捉。为了能更好捕捉用户兴趣,MIMN 设计了 Memory Induction Unit ( MIU ) 来捕捉用户兴趣演化。
DIEN 模型做兴趣演化的时候有这样一个考量,在电商场景下用户的行为序列可能是跳跃的,比如用户在这个时间段全部看电子产品,另一个时间段全部看衣服,其间并没有时序关联关系,DIEN 的设计思路是通过对 Target 进行显示的 Attention 操作,把 attention weight 比较高的部分挑选出来,相当于挑选出比较相似的序列宝贝,然后经过 GRU 网络进行演化。
在我们的 MIMN 中,已经把 target attention 解耦开了,可以发现 NTM 的余弦相似计算也是一种相似关联操作,变相把相似的宝贝聚集在一个相同的 memory slot 里面。因而我们可以将相同 memory 里面的 items 分配到相同的 channel 里面进行演化。
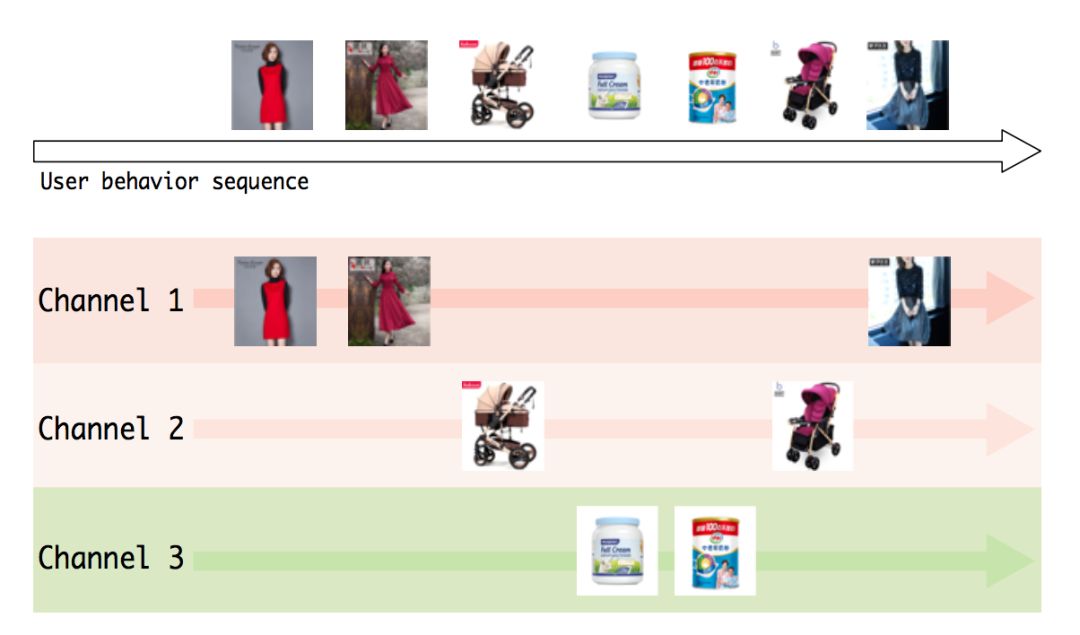
如上图所示,衣服都分配到了 channel 1,而母婴产品分配到了 channel 2 与 channel 3,在此基础上我们又把 channel 所对应的 memory 信息送入 GRU 模,如下图和公式所示,进行兴趣演化和高阶兴趣的挖掘。
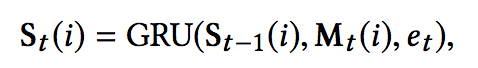
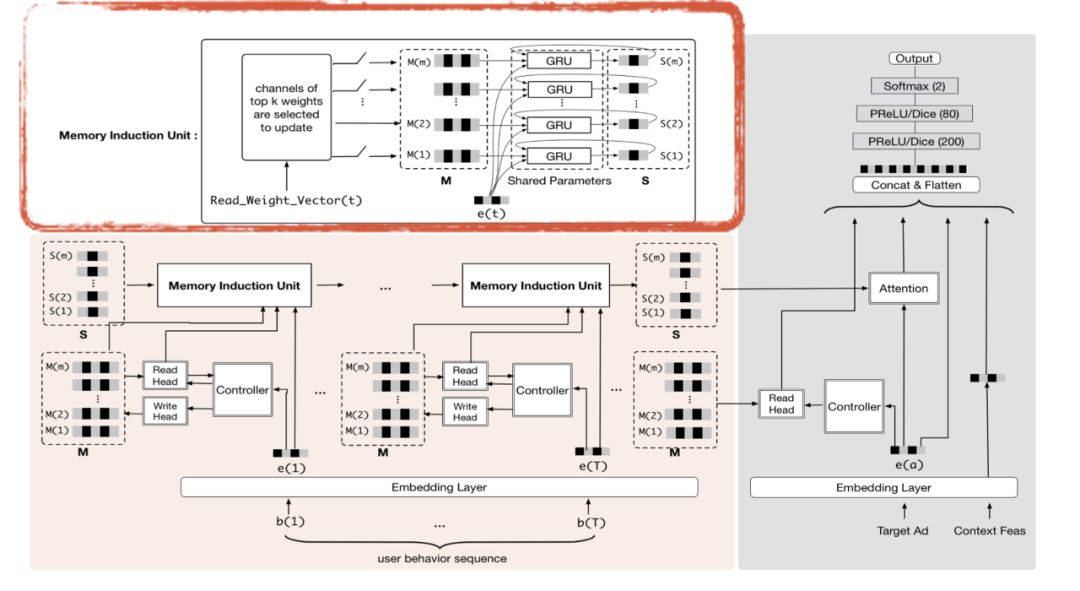
MIMN 的在线实现如图13所示,时序模块存放在 UIC 系统中,当有个新的用户行为时,会通过 Controller 实时更新用户的 memory 向量,并通过 memory induction unit 来更新 channel 演化向量,然后将这两组向量存放在 TAIR 以供线上实时请求系统应用。
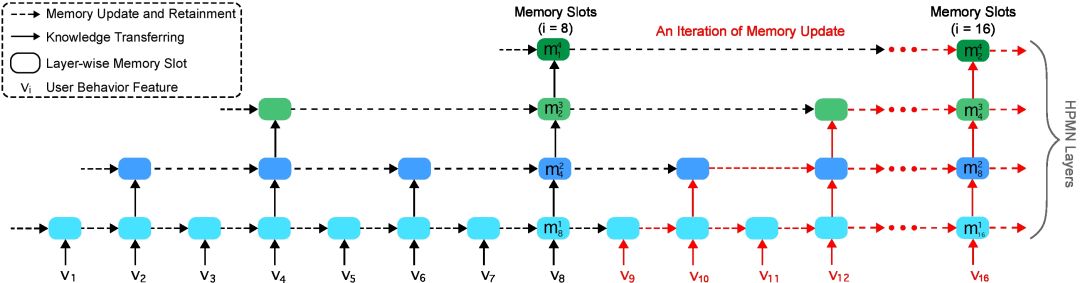
接下来简单介绍一下 HPMN。HPMN 是从时间维度进行 memory 构建。它的设计理念认为用户存在长、中、短各变化趋势的兴趣。它的设计思路借鉴层级 RNN,采用周期向上归纳的设计,分层刻画不同时间跨度的兴趣偏好,与此同时,为了防止不同层之间具有相似的表达,它也加入协方差约束 ( 兴趣多样化约束 )。结构如图14所示,比较的简单明了,采用幂次固定周期进行归纳总结的方式。
Memory 的更新公式如下:
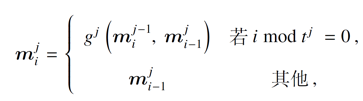
它的兴趣向量读取为:当一个 request 来的时候,有一个目标商品的特征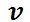
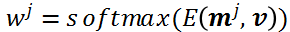
最后得到用户在第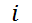
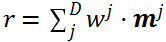
它采用了多样性正则策略,约束不同的记忆槽存储用户的不同时间跨度的兴趣,如以下公式所示:
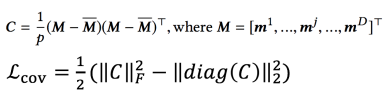
——实践总结——
❶ 效果对比
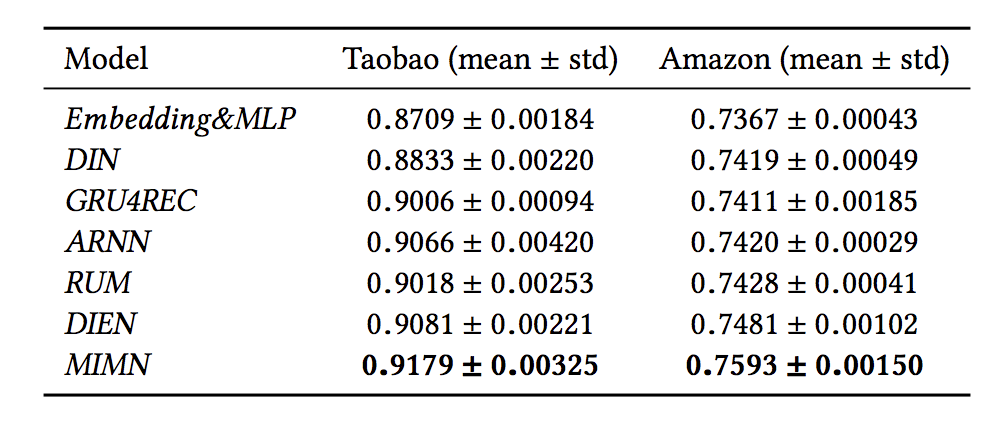
我们采用了亚马逊以及淘宝的公开数据集来进行实验,对比的模型有:Embedding & MLP、DIN、GRU4REC、ARNN、RUN、DIEN,从表1可以看到在这两个数据集上的效果 MIMN 模型都优于对照的模型。
关于线上效果,如下表所示,在 GAUC 的评价指标下,我们的模型相较于 DIEN 能提高1个百分点的效果。表2中倒数第二行是在参数不同步的情况下的模型效果,可以看出 UIC server 和 RTP server 模型参数存在1天的差异时模型效果未下降;最后一行是当训练数据中有大促数据时 ( 由于大促用户行为丰富,同样长度的行为序列涵盖的时间跨度较短 ),模型效果略有下降,大概下降了两个千分点。

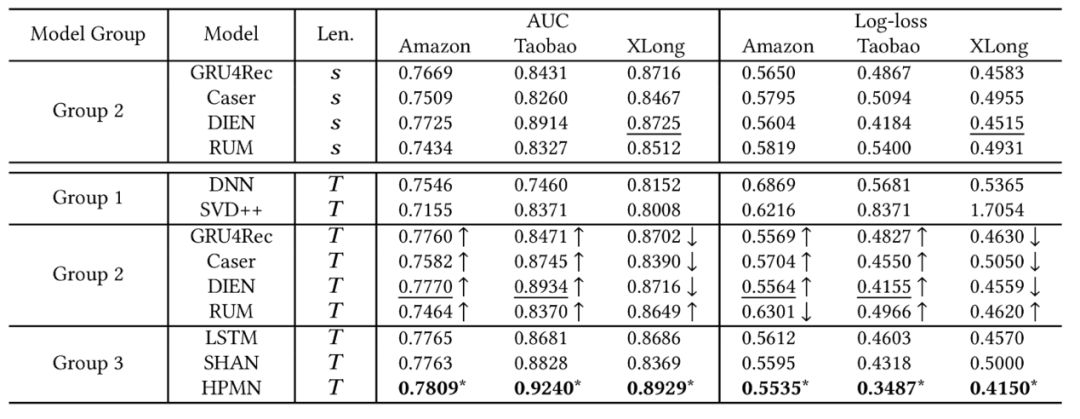
HPMN 模型的效果如表3所示,实验做了两个对比,上面的 s 指的是一个短序列,下面的 T 指的是长期行为序列,s 只做了 group 2 的实验对比,说明当我们把行为序列扩长,会带来明显的增益,另外 HPMN 在长期行为序列下对比其他模型也是有明显的效果提升。
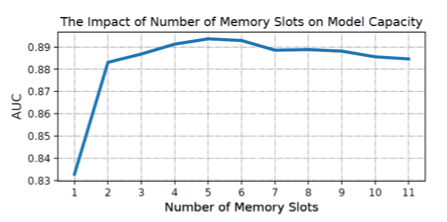
另外还可以对容量进行分析。MIMN 中 memory 的数量可以任意定义,但是它的效果并不是随着 memory 的增长线性增长的。在淘宝数据集和亚马逊数据集上,最优的 memory slot 数量分别是8个和4个,因为我们能处理的行为序列长度和最优的 slot 个数是存在关联关系的,当行为序列较短的时候,例如亚马逊数据集,往上扩 slot,并不能带来效果提升。

HPMN 也会存在这样的边际效益,而且在逐渐扩展 slot 的过程中可能还会导致效果的下跌。
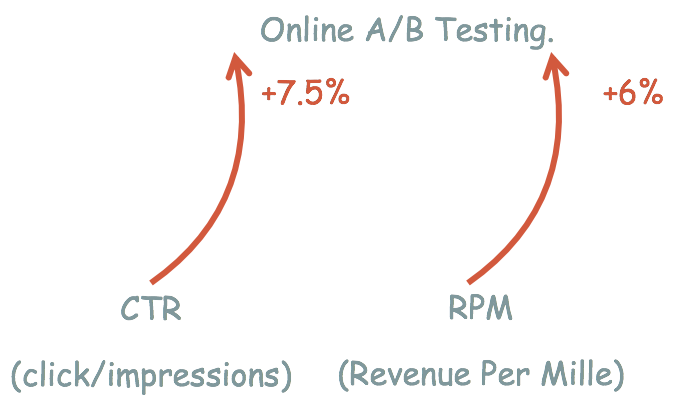
线上收益方面,在猜你喜欢的场景带来了7.5%的 CTR 提升,而 RPM 有6%的提升。
除此之外,我们模型上线的过程遇到了很多困难并将其总结成经验。
关于整个实践细节 UIC server 和 RTPserver 模型参数同步问题
MIMN 算法是由两部分组成,一部分是用户兴趣提取,一部分是 CTR 预估,在线计算会涉及到 UIC 和 RTP 两组服务。因此会存在模型参数同步的问题,在表三中我们做了相关实验,证明 UIC 和 RTP server 模型参数相差一天,对于模型离线效果无影响。我们系统是采用增量训练的方式,每小时就会更新模型参数,会大幅降低参数不一致风险。
大促数据影响
电商场景经常存在大促,比如最出名的双十一促销。在这样的情况下,数据的分布和用户行为与平时存在很大的差异,而且大促当天丰富的用户行为会影响对用户长期兴趣的刻画。我们对比了引入促销时期用户行为刻画用户兴趣,离线效果有0.2%的下降。对此我们对大促的行为通过降采样的方式进行一定的丢弃。
初始化策略
尽管 UIC 可以增量计算用户行为,但是累计用户长时间行为会耗时严重。于是我们设置了一个初始化机制。将模型学习到的用户120天行为的兴趣表达导出,放入 TAIR 作为初始化。
回滚机制
为了防止线上出现故障,例如行为数据被污染,带来的在线效果问题。我们设置了断点保存机制,定时将的用户兴趣状态导出到离线存储。出现故障后,加载最近的离线存储。
❷ 总结思考
我们团队围绕长期用户行为的兴趣挖掘,分别从多峰兴趣和时间跨度进行了模型设计,并且根据该模型设计进行了系统结构的新颖创新,从而充分利用了长期用户行为的数据价值。长期兴趣挖掘有助于更好地刻画用户,值得深入研究下去,未来我们也将进一步从算法和系统推进研究,从而更灵活的捕捉用户行为模式。与此同时我们认为未来的模型发展离不开系统的适配,一个好的系统能更好的释放模型能力,因而 Co-Design 的系统模型设计思维可以更好地打开发展空间。


卞维杰
——END——
文章推荐:
阿里妈妈:定向广告新一代点击率预估主模型——深度兴趣演化网络

DataFunTalk:
专注大数据、人工智能技术应用的分享与交流。

一个「在看」,一段时光!👇



