基于深度学习的单目深度估计综述
文章:Monocular Depth Estimation Based On Deep Learning: An Overview
作者:Chaoqiang Zhao, Qiyu Sun, Chongzhen Zhang
翻译:particle
本文转载自:点云PCL
●论文摘要
深度信息对于自动驾驶系统的感知和估计自身位姿是十分重要的。传统的深度估计方法,如运动恢复结构和立体视觉匹配,都是建立在多视点的特征对应上的,并且预测的深度图是稀疏的。从单个图像中推断深度信息(单目深度估计)是一个不适定问题。近年来,随着深度神经网络的迅速发展,基于深度学习的单目深度估计得到了广泛的研究,并取得了良好的精度。比如利用深度神经网络对单个图像进行端到端的稠密深度图估计。为了提高深度估计的精度,之后提出了不同的网络结构、损失函数和训练策略。因此,本文综述了目前基于深度学习的单目深度估计方法。首先,我们总结了几种在基于深度学习的深度估计中广泛使用的数据集和评价指标。此外,根据不同的训练方式,我们回顾了现有的一些有代表性的训练方法:有监督的、无监督的和半监督的。最后,我们讨论了单目深度估计的挑战,并对未来的研究提出了一些设想。
● 相关工作与介绍
从图像中估计深度信息是计算机视觉的一项基本而重要的任务,可广泛应用于同步定位与建图(SLAM)、导航、目标检测和语义分割等领域。
基于几何的方法:基于几何约束的方法从一对图像中恢复三维结构是感知深度的常用方法,近四十年来得到了广泛的研究。运动恢复结构(SfM)是从一系列二维图像序列中估计三维结构的代表性方法,并成功地应用于三维重建和SLAM领域。稀疏特征的深度由SfM通过图像序列之间的特征对应和几何约束来计算,即深度估计的精度很大程度上依赖于精确的特征匹配和高质量的图像序列。但是,SfM还存在单目尺度模糊的问题。立体视觉匹配还可以通过从两个视点观察场景来恢复场景的三维结构。立体视觉匹配通过两个相机的形式模拟人眼的运动方式,通过代价函数计算出图像的视差图。由于预先标定了两个摄像机之间的变换,所以在立体视觉匹配期间,在深度估计中包括尺度信息的计算。

虽然上述基于几何的方法可以有效地计算稀疏点的深度值,但这些方法通常依赖于图像匹配或图像序列。由于缺乏有效的几何解,如何从单个图像中获取密集的深度图仍然是一个重大的挑战。
基于传感器的方法:利用深度传感器,如RGBD相机和LIDAR,可以直接获得相应图像的深度信息。RGB-D相机能够直接获得RGB图像的像素级密集深度图,但其测量范围有限,室外对光照敏感。虽然激光雷达在无人驾驶和工业中广泛应用于深度测量,但它只能生成稀疏的三维地图。此外,这些深度传感器(RGBD相机和LIDAR)的大尺寸和功耗影响了它们在小型机器人上的应用,比如无人机。由于单目相机成本低、体积小、应用范围广,从单个图像中估计稠密深度图越来越受到人们的关注,近年来基于端到端深度学习的方法得到了广泛的研究。
基于深度学习的方法:随着深度学习的快速发展,深度神经网络在图像处理方面表现出了突出的性能,如目标检测和语义分割等领域,最近的发展表明,基于深度学习,可以从单个图像中以端到端的方式恢复像素级深度图。各种神经网络已经证明了它们对解决单目深度估计的有效性,例如卷积神经网络(CNNs),递归神经网络(RNNs),变分自动编码器(VAEs)和生成对抗网络(GANs)。本综述的主要目的是提供对主流算法的直观理解,这些算法对单目深度估计做出了重大贡献,我们从学习方法的角度回顾了单目深度估计的一些相关工作。
● 深度估计中的数据集和评价指标
A 数据集
KITTI:KITTI数据集是计算机视觉中最大、最常用的子任务数据集,如光流、视觉里程计、深度估计、目标检测、语义分割和跟踪,它也是无监督和半监督单目深度估计中最常用的基准和主要训练数据集。
NYU Depth :NYU Depth数据集更关注室内环境,该数据集中有464个室内场景。与用激光雷达采集地面真实情况的KITTI数据集不同,NYU Depth数据集通过RGB-D摄像机获取场景的单目视频序列和地面的深度真值。它是有监督单目深度估计的常用基准和主要训练数据集。
Cityscapes:Cityscapes 数据集主要关注语义分割任务。在这个数据集中,有5000幅图像带有精细注释,20000幅图像具有粗略标注。
Make3D: Make3D数据集只包含单目的RGB和深度图像,没有立体图像,这与上述数据集不同。由于该数据集中没有单目序列或立体图像对,因此半监督和非监督学习方法都不将其作为训练集,而有监督方法通常采用它作为训练集。相反,它被广泛用作无监督算法的测试集,以评估网络在不同数据集上的泛化能力。
B 评价指标
为了评价和比较各种深度估计网络的性能,文章提出了一种常用的深度估计网络性能评价方法,该方法有五个评价指标:RMSE、RMSE-log、Abs-Rel、Sq-Rel、精度。这些指标的公式如下:
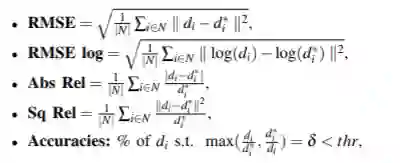
● 基于深度学习的单目深度估计
在本节中,我们将从使用地面真实性的角度来回顾单目深度估计方法:有监督方法、无监督方法和半监督方法。虽然无监督和半监督方法的训练过程依赖于单目视频或立体图像对,但训练后的深度网络在测试过程中从单个图像预测深度图。我们从训练数据、监督信号和贡献等方面对现有的方法进行了总结,并收集了在KITTI数据集上评价的无监督和半监督算法的定量结果。
A 有监督单目深度估计
监督方法的基本模型:监督方法的监督信号基于深度图的地面真值,因此单目深度估计可以看作是一个回归问题。从单个深度图像设计神经网络来预测深度。利用预测深度图和实际深度图之间的差异来监督网络的训练 L2损失
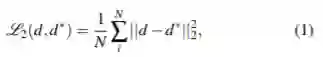
深度网络通过近似真值的方法来学习场景的深度。
基于不同结构和损失函数的方法:据我们所知,Eigen等人首先用CNNs解决单目深度估计问题。该体系结构由两个组成部分组成(全局粗尺度网络和局部精细尺度网络),在文献中用于从单个图像进行端到端的深度图预测。
基于条件随机场的方法:Li等人提出了一种基于多层的条件随机场(CRFs)的细化方法,该方法也被广泛应用于语义分割。在深度的估计中,考虑到深度的连续特征,可以广泛地使用CRF的深度信息,因此可以广泛地应用于深度的估计中。
基于对抗性学习的方法:由于提出的对抗性学习在数据生成方面的突出表现,近年来成为一个研究热点。各种算法、理论和应用已得到广泛发展。对抗式学习深度估计的框架如图所示。
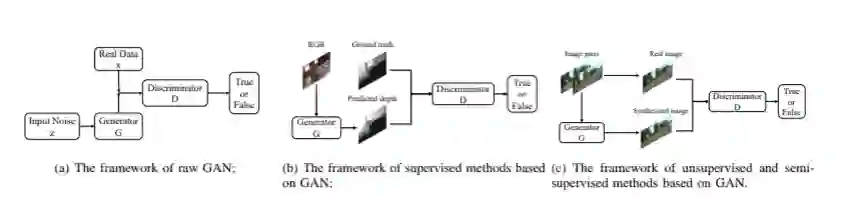
B 无监督单目深度估计
在无监督方法的训练过程中,将帧间的几何约束作为监督信号,而不是使用代价昂贵的背景真值。
无监督方法的基本模型:无监督方法由单眼图像序列训练,几何约束建立在相邻帧之间的投影上
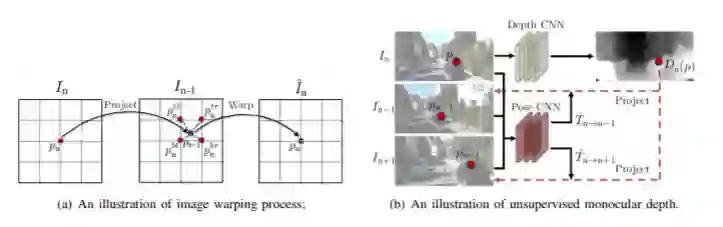
左边是无监督方法中视图重建的图像变换过程 右边是无监督单目深度估计方法的一般框架。
基于可解释性掩模的方法:基于投影函数的视图重建算法依赖于静态场景假设,即动态目标在相邻帧上的位置不满足投影函数,从而影响测光度误差和训练过程。
基于传统视觉里程计的方法:在文献[16]中,用传统的直接视觉里程计回归的位姿来辅助深度估计,而不是使用位姿网络估计的位姿。直接视觉里程计利用深度网络生成的深度图和一个三帧图像,通过最小化光度误差来估计帧间的姿态,然后将计算出的姿态发送回训练框架。因此,由于深度网络由更精确的姿态来监督,因此深度估计的精度显著提高。
基于多任务框架的方法:最近的方法在基本框架中引入了额外的多任务网络,如光流、物体运动和相机内参矩阵,作为一个附加的训练框架,加强了整个训练任务之间的关系
基于对抗学习的方法:将对抗学习框架引入到无监督的单目深度估计中。由于在无监督训练中没有真正的深度图。因此,将视图重建算法合成的图像和真实图像作为鉴别器的输入,而不是使用鉴别器来区分真实深度图和预测深度图。
C 半监督单目深度估计
由于在训练过程中不需要真值,因此无监督方法的性能与监督方法还有很大差距。此外,无监督方法也存在着尺度模糊、尺度不一致等问题。因此,为了提高估计精度,减少对真值的依赖,提出了半监督方法。此外,还可以从半监督信号中学习尺度信息。立体图像对的训练类似于单目视频,其主要区别在于两帧(左右图像或前向后图像)之间的变换是否已知。因此,一些研究将基于立体图像对的框架视为无监督方法,而另一些研究将其视为半监督方法。本文将其视为半监督方法,而左右图像之间的姿态是训练过程中的监督信号。
半监督方法的基本模型:训练在立体图像对上的半监督方法估计左右图像之间的视差图(逆深度图)。然后,使用由预测的逆深度计算的视差图Dis通过变换图从右图像合成左图像,如图所示。
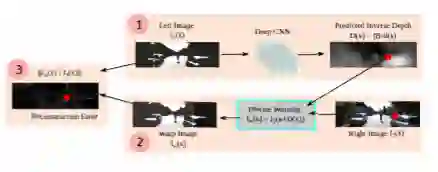
基于立体图像对的半监督单目深度估计的一般框架。深度网络取左图像预测其像素级逆深度图(或视差图),利用预测的逆深度图通过逆扭曲算法从右图像重建左图像。通过计算重构误差来监督训练过程。
基于立体匹配的方法:Luo等人提出了一种基于Deep3D的视景合成网络,用于从左图像估计右图像,这与上述工作不同。此外,还设计了立体匹配网络,对原始的左、右图像进行立体匹配,对视差图进行回归。
基于对抗式学习和知识提炼的方法:结合先进的网络框架,如对抗式学习和知识提炼,正变得越来越流行,并能显著提高其性能。
基于稀疏真值的方法:为了增强监督信号,将稀疏真值广泛地引入训练框架中。Kuznietsov等人。采用激光雷达采集的地面真实深度进行半监督学习。另外,左右深度图均由CNNs估计,基于LIDAR数据的监督信号(Gl,Gr)公式如下:
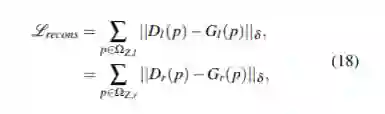
● 讨论
总的来说,我们认为单目深度估计的发展仍将集中在提高精度、可传输性和实时性上。
精度:以往的工作主要集中在通过采用新的损失函数或网络框架来提高深度估计的精度,如表一所示。LSTM、VAE、GANs等几种著名的网络框架在提高深度估计性能方面已显示出其有效性。因此,随着深层神经网络的发展,尝试新的网络框架,如三维卷积、图形卷积、注意机制[和知识蒸馏,可能会得到令人满意的结果。虽然无监督方法在训练过程中不依赖于地面真实情况,但其精度与目前最有效的半监督方法相差甚远,如表二所示。寻找一个更有效的几何约束来改进无监督方法可能是一个很好的方向。
可传输性:可传输性是指同一网络在不同摄像机、不同场景和不同数据集上的性能。深度网络的可传输性越来越受到人们的关注。目前大多数的方法都是在同一个数据集上训练和测试的,从而获得了令人满意的结果。然而,不同领域或不同摄像机采集的训练集和测试集往往会导致性能严重下降。将摄像机参数引入深度估计框架,在训练过程中利用域自适应技术,可以显著提高深度网络的可移植性,是近年来研究的热点。
实时性:虽然深度的网络表现出出色的性能,但它们需要更多的计算时间来完成估计任务,这对它们的应用是一个巨大的挑战。深度估计网络在嵌入式设备上实时运行的能力对其实际应用具有重要意义。因此,基于有监督、半监督和无监督学习的轻量级网络的发展将是一个很有前途的方向,而目前这方面的相关研究还不多。由于轻量级网络的参数个数较少,这就影响了网络的性能。因此,在保证实时性的前提下提高精度是一个值得研究的课题。此外,对于基于深度学习的单目深度估计方法的机理研究很少,比如深度网络学习了什么深度线索以及利用了什么深度线索。
●总结
本文旨在对基于深度学习的单目深度估计这一日益增长的研究领域的综述文献。因此,我们结合损失函数和网络框架的应用,从训练方式的角度对单目深度估计的相关工作进行了综述,包括有监督、无监督和半监督学习。最后,我们还讨论了当前研究的热点和挑战,并对未来的研究提出了一些有价值的想法和有希望的方向。
下载1:动手学深度学习
在CVer公众号后台回复:动手学深度学习,即可下载547页《动手学深度学习》电子书和源码。该书是面向中文读者的能运行、可讨论的深度学习教科书,它将文字、公式、图像、代码和运行结果结合在一起。本书将全面介绍深度学习从模型构造到模型训练,以及它们在计算机视觉和自然语言处理中的应用。

下载2:CVPR / ECCV 2020开源代码
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2300+人,旨在交流顶会(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI、中文核心等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!
