AI初识:给深度学习新手做项目的10个建议
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
项目开发之前应该做什么
在你真正开始撸代码之前,送大家一句话,“磨刀不误砍柴工”。
拿到一个任务的时候,先不要上来就开始训模型,而是做好三件事。
1、知道你要做的任务是一个什么任务。
以图像分类为例,猫狗分类是一个分类任务,随便找个什么模型都能完成。

鸟类分类也是一个分类任务,但是不简单,不是随随便便拿个模型就能搞定。

表情识别最终也是一个分类,但是这不仅仅是一个分类问题,而是检测+分类问题。

产品经理们只会告诉你要实现什么功能,而不会告诉你用什么方案,对于简单任务来说这可能不需要思考,但是复杂任务一定要先充分调研认识。
你说上面的这个例子很简单,一眼就明白,那么我再举出几个例子,你是否一下子就能明白背后的核心技术?



2、找到竞争对手,做好预期。
比如你要做一个表情识别API,要做一个美颜算法,一定要先看看你的竞争对手做的怎么样了,就算最后你做出来跟别人还差十万八千里,也不至于到最后一刻才发觉。这叫知人之明和自知之明,一定要先有。
在这个过程中,基本上就能确定要走的路,第一条路是追随模仿别人,第二条路是超越别人,这两者是不一样的。
前者,只要把已有成熟的资料收集到位,经验足够丰富,必定能成功,否则就是个人能力和资源问题。这样的一条路,相信老大们会给你布置一个明确的时间节点。
比如表情识别,很成熟,那你做出来也不能比别人差太多。
如果是第二条路,那么就意味着没有参考者,或者参考者做的也不行。那么最难的是什么,就是预期能做到什么水平。
可能技术已经成熟了,没人做,恭喜你,赶紧搞。
可能技术比较前沿,能做技术储备,但是还无法落地。
可能根本就还做不了。
3、想好你需要什么样的数据,从源头上降低任务的难度。
在公司干了四年活,大部分项目都需要自己准备数据,不会有现成的数据可以使用,而如何准备数据,这是需要经验的。
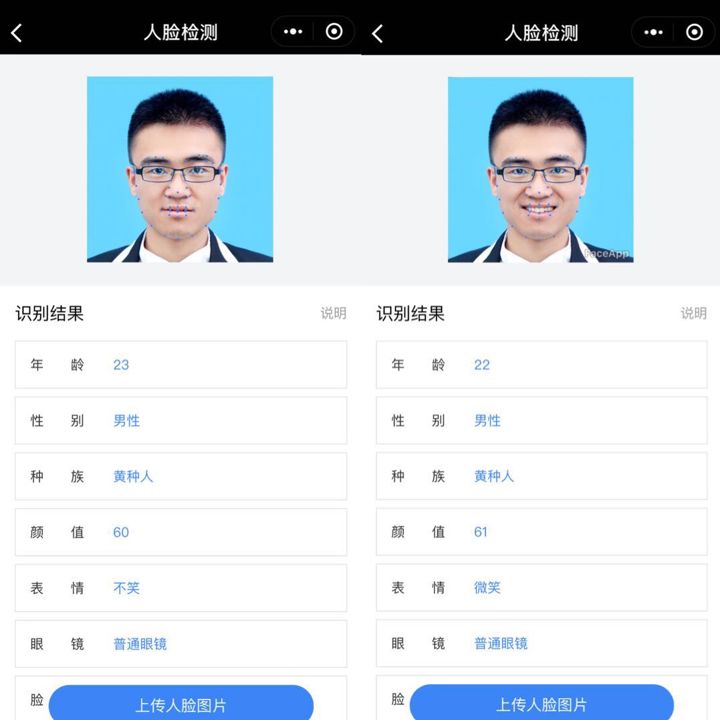
举个最简单的例子,假如我们需要开发一个分类算法来分析一张图片中的人是不是在笑,图像可能是这样。

你会爬取或者从数据集中拿到很多不同表情的数据然后就直接开干吗?显然那是错误的路子。
开始一个任务后我们首先就应该想怎么降低任务的难度,对于此任务,起作用的只有嘴唇这块区域,那么我们完全可以基于嘴唇区域来训练一个分类模型。
高精度成熟的人脸检测和关键点检测算法是很多的,所以你可能需要准备的训练数据是这样的。当然,如果你直接基于关键点的结果来做也是可以的,这就回到了第一个问题了。
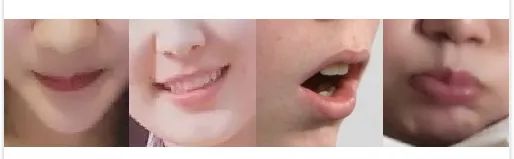
这样至少有两个好处,(1) 明显这个分类更加简单了。(2) 可以使用更小的输入图完成任务,计算代价也更低。
训练模型从哪里开始
很少有一个任务可以拿现有的模型使用,你通常是需要训练自己的模型的,那么在训练一个模型的时候,应该怎么样开始。
这里牵涉到3个问题,框架,基准模型和数据,其中任何一环都有可能有问题。
1、首先确定框架
没有一个深度学习任务不需要一个框架来训练,很多的时候你不得不在不同的框架之间进行切换。比如做分类分割或者检测,caffe都很好用。做风格化搞GAN,就得上tensorflow或者pytorch了,你一定要先选择一个工具,不然很可能会陷入找到了很多中github方案,这个试了遇到困难换下一个,下一个又遇到困难。
有自己最拿手的一个框架,选定项目就坚定地干,遇到了问题就去解决。
2、然后确定基准模型
最终工业级部署的时候,你往往需要一个效率更高的模型。但是除非你是老司机,否则不应该在还没有确定方案是否可行的时候就想自己的模型,而是应该从一个绝对可靠的模型开始,比如resnet18,比如mobilenet,正确地使用好它们,得到还不错的结果,将它的结果作为你自己算法要PK的对象。
3、最后准备好数据
在前面你想好自己需要的数据了,接下来就是去采集到这些数据。完成一个项目,就是不断迭代模型和数据的过程。
刚开始的时候,你不需要数据都到位,但是要考虑好以下因素。这里我们不管数据是自己采集的还是从公开数据集中获取的。
(1) 准备大小合适的数据量。以二分类任务为例,你不能拿500张图就开始干,没任何意义。你不能苛求一开始就有50000万数据,也不合理,万一搞失败了还浪费资源。笔者先后做过10余个分类任务,完成任务上线从3000到10万都用过,我的建议是,尽量先准备个3000数据再开干,不然就太没诚意了。
(2) 从简单数据开始。以人脸识别为例,各种公开数据集不要混着用,分布不一致难度也不相同,你应该先专注简单的属于同一个分布的,比如找10000个正脸或者姿态小的数据,方案验证通过之后再增加难度。
很多的时候,你还要考虑覆盖各种场景(光照,背景)等。以上的这些东西,书不会告诉你,培训也没法教你,需要的是自己的积累,厚积薄发。
培养对数据的敏感性,可以从咱们的数据相关的文章开始看。
正确训练模型的基本常识
1 注意网络的输入大小
你极有可能是从finetune其他的模型开始,以图像分类为例,公开的模型大多是以224*224为尺度,而你的任务未必也需要这样。
如果你想要区分不同种类的鸟,那么因为细节在鸟的局部身体部位,你的输入恐怕是要更大一些才能提取到好的特征,比如放大一倍,用448*448,这也是论文中常用的。
如果你只是要区分不同表情,用上了上面的嘴唇数据,那224*224纯属浪费,你可能只需要一个48*48的输入就足以很高准确率完成任务。
对于图像分割和目标检测,标准又不太一样。究竟使用多大的输入,这需要你依靠经验来确定,而且还和能给你多少资源,以及自己优化模型的能力相关。
2 注意特征输出大小
前面说了输入,这里再说输出,包括最后一层卷积的大小和通道数等。
首先看大小,对于一个分类任务来说,最后卷积层抽象为一个k*k的特征图,然后进行池化,全连接。如果这个特征图太大,知识根本就没有抽象出来,如果太小,表征能力又可能不够。
根据不同的难度,3*3,5*5,7*7我都用过,但是没有用过9*9以上的,试过分类性能会下降,计算量还增加。imagenet竞赛的那些网络基本上都是7*7,兼顾了性能。
这个输出大小,就由输入大小和网络的全局stride来决定,不断遇到很多同学没有注意这个问题,结果模型性能很差的,这是基本素质。
3 正确地使用数据
前面已经准备了一些好的数据,别再用的时候却搞错了,对于图像分类来说有以下几个准则。
(1) 随机打乱你的数据。
否则每个batch给的是同样类别的数据,不一定能保证模型学的正常。
(2) 在线做一些基本的数据预处理和增强。
图像缩放操作,你要想好是用有变形的缩放,即统一缩放到固定大小。还是等比例缩放,即把短边缩放到一定尺度。
裁剪操作,随机裁剪是最简单有效的数据增强方案,一开始就可以做起来,比如256*256随机裁剪224*224,不必要过于复杂。
镜像操作,也就是mirror参数,不是所有的任务都可以翻转的,根据自己任务使用。
减均值和归一化操作,其实这一步倒并非必要,因为网络自然可以学习到这一点。不过你做一下,通常不会有副作用。
更多的数据增强先不要急着做,因为那会增加网络优化的难度和时间。
这些操作都要在线做而不是离线准备好存入本地文件,这是很低效的。
4 正确地进行训练
接下来就开始训练,你可能会遇到各种与自己期望不相符的结果,其中一些很可能是你自己的错误造成的,因此有一些基本的训练参数需要注意。
(1) 用好学习率策略。
如果你没有经验,就不要一开始就使用SGD,虽然它可能取得更好的结果。直接用Adam,并且使用它的默认参数m1=0.9,m2=0.999,lr=0.001,学习率可以调整,其他两个参数基本不需要动。更多比较可以参考我们之前的文章。如果你的学习率搞的不好,很可能出现梯度爆炸或者不收敛。
(2) 正确使用正则项。
weight decay是一个非常敏感的参数,如果你不是很有经验,从一个很小或者为0的值开始。
训练的时候可以用dropout,测试的时候是不需要用的。
(3) 正确使用BN层。
Batch Normalization是一个好东西,加快训练速度降低过拟合,但是你要注意它在训练的时候和测试的时候是不一样的。
use_global_stats这个参数在训练时是false,测试时是true,如果你没用对,那么可能训练无法进行,或者测试结果不对。
-完-
*延伸阅读
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~






