AAAI 2018 | 中科大提出新型连续手语识别框架LS-HAN,帮助「听」懂听障人士
选自arXiv
作者:Jie Huang、 Wengang Zhou、Qilin Zhang、Houqiang Li、Weiping Li
机器之心编译
参与:路雪、李亚洲
中科大一篇关于手语识别的论文被 AAAI 2018 接收。该论文提出一种新型连续手语识别框架 LS-HAN,无需时间分割。LS-HAN 由三部分构成:用于视频特征表示生成的双流卷积神经网络、用于缩小语义差距的潜在空间和基于识别的潜在空间分层注意力网络。实验结果表明该框架有效。
手语识别(SLR)面临的一个重要挑战是设计能够捕捉人体动作、姿势和面部表情的视觉描述符(descriptor)。主要有两类:手动制作的特征(Sun et al. 2013; Koller, Forster, and Ney 2015)和基于卷积神经网络的特征(Tang et al. 2015; Huang et al. 2015; Pu, Zhou, and Li 2016)。受 CNN 近期成功的启发,该论文作者设计了一种双流 3D-CNN 用于视频特征提取。
时域分割是连续手语识别的另一个难题。连续 SLR 的常见方案是将句子分解成孤立的单词识别问题,这需要进行时域分割。时域分割并不简单,因为存在多种过渡动作,很难检测。而且时域分割作为预处理步骤,如果分割不准确就会导致后续步骤中出现错误。此外,标注每个孤立的片段非常耗时。
受利用长短期记忆(LSTM)网络进行视频描述生成的启发,研究者使用分层注意力网络(HAN,LSTM 的扩展)绕过时域分割,考虑结构信息和注意力机制。该方案需要向 HAN 馈送整个视频,然后逐词输出完成的句子。但是,HAN 可以根据输入视频和前一个单词来优化生成下一个单词的概率,但忽略了视频和句子之间的关系(Pan et al. 2015)。因此,它会遇到是否稳健的问题。为了解决这个问题,研究者整合了潜在空间(LS,Latent Space)模型,以明确地利用视频和文本句子之间的关系。
这篇论文的主要贡献如下:
提出新型双流 3D-CNN,用于视频特征表示生成;
提出适合连续 SLR 的新型 LS-HAN 框架,无需进行时域分割;
LS-HAN 框架对相关性和识别损失进行联合优化;
编译最大的开源中国手语(CSL)数据集(截至 2017 年 9 月)用于连续 SLR,数据集具备句子级别的标注。
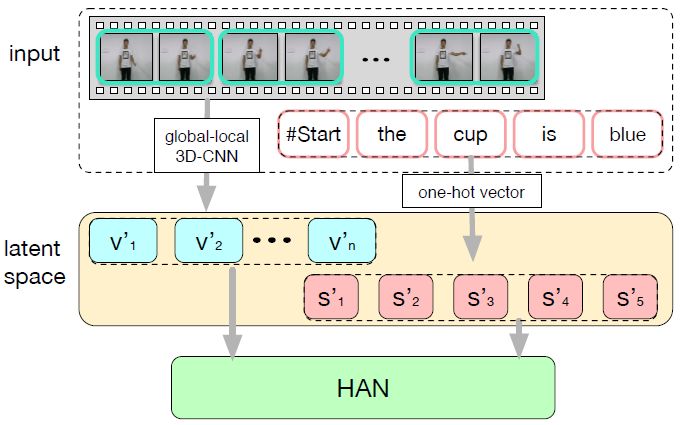
图 2:LS-HAN 框架。输入是视频和配套的标注句子。视频用全局-局部特征来表示,每个单词用 one-hot 向量进行编码。它们被映射到同一个潜在空间,以对视频-句子相关性进行建模。研究者基于映射结果,利用 HAN 进行自动句子生成。
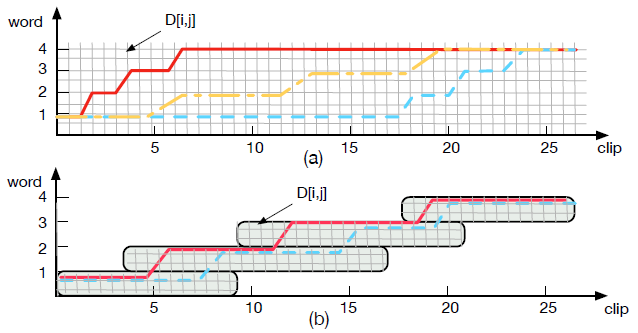
图 3:动态时间规整(DTW)生成的相关规整路径。X 轴表示帧索引,Y 轴表示词序索引。网格表示矩阵元素 D[i, j]。(a)表示原始 DTW 的三种可能的对齐路径。(b)表示 Window-DTW 的对齐路径。
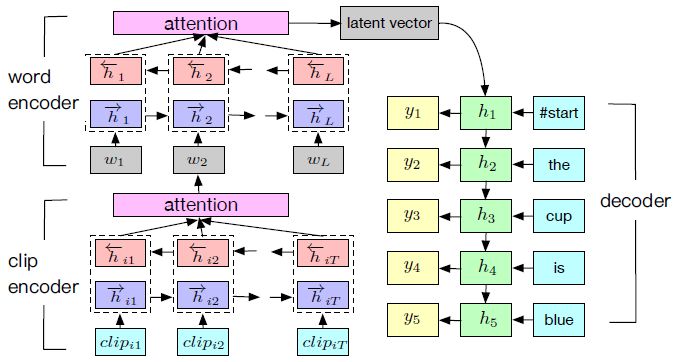
图 4:HAN 通过注意力层对视频进行分层编码,并对输入序列加权。它将隐藏向量表示逐词解码,组合成句子。
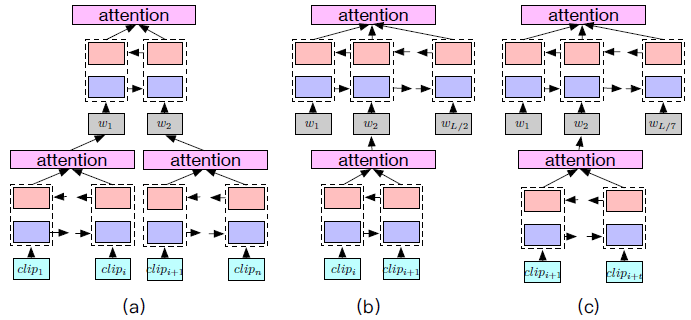
图 5:测试阶段中的对齐重建。(a)将视频所有的片段分割成两个子序列,并编码成 HAN;(b)将每两个相邻的片段分割成一个子序列;(c)将所有片段平均分割成 7 个子序列(7 是训练集的平均句子长度)。
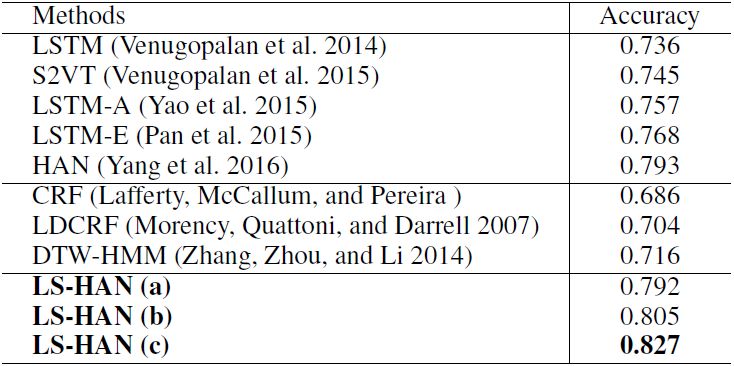
表 2:连续 SLR 结果。粗体字方法是本论文所提出方法的原始和修改版本。
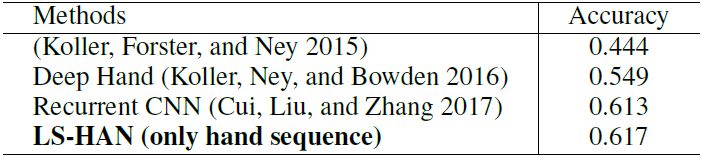
表 3:在 RWTH-PHOENIX-Weather 上的连续 SLR。
论文:Video-based Sign Language Recognition without Temporal Segmentation

论文链接:https://arxiv.org/abs/1801.10111
摘要:世界上数百万听障人士通常使用手语进行交流,因此手语自动翻译很有意义,也很重要。目前,手语识别(SLR)存在两个子问题:逐词识别的孤立手语识别,翻译整个句子的连续手语识别。现有的连续手语识别方法利用孤立 SLR 作为构造块,还有额外的预处理层(时域分割)、后处理层(句子合成)。不过,时域分割并不简单,且必然会向后续步骤传播误差。更糟糕的是,孤立 SLR 方法通常需要对句子中的每个单词分别进行标注,严重限制了可获取训练数据的量。为了解决这些难题,我们提出了一种新型连续手语识别框架,带有潜在空间的分层注意力网络(Hierarchical Attention Network with Latent Space,LS-HAN),无需对时间分割进行预处理。LS-HAN 由三部分构成:用于视频特征表示生成的双流卷积神经网络、用于缩小语义差距的潜在空间(Latent Space,LS)和基于识别的潜在空间分层注意力网络(HAN)。我们在两个大型数据集上进行了实验,实验结果表明我们提出的框架是有效的。




