再一次生产 CPU 高负载排查实践
(给ImportNew加星标,提高Java技能)
作者:crossoverJie
segmentfault.com/a/1190000019507028
前言
前几日早上打开邮箱收到一封监控报警邮件:某某 ip 服务器 CPU 负载较高,请研发尽快排查解决,发送时间正好是凌晨。
其实早在去年我也处理过类似的问题,并记录下来:《一次生产 CPU 100% 排查优化实践》
不过本次问题产生的原因却和上次不太一样,大家可以接着往下看。
问题分析
收到邮件后我马上登陆那台服务器,看了下案发现场还在(负载依然很高)。
于是我便利用这类问题的排查套路定位一遍。
首先利用 top -c 将系统资源使用情况实时显示出来 (-c 参数可以完整显示命令)。
接着输入大写 P 将应用按照 CPU 使用率排序,第一个就是使用率最高的程序。
果不其然就是我们的一个 Java 应用。
这个应用简单来说就是定时跑一些报表使的,每天凌晨会触发任务调度,正常情况下几个小时就会运行完毕。
常规操作第二步自然是得知道这个应用中最耗 CPU 的线程到底再干嘛。
利用 top -Hp pid 然后输入 P 依然可以按照 CPU 使用率将线程排序。
这时我们只需要记住线程的 ID 将其转换为 16 进制存储起来,通过 jstack pid >pid.log 生成日志文件,利用刚才保存的 16 进制进程 ID 去这个线程快照中搜索即可知道消耗 CPU 的线程在干啥了。
如果你嫌麻烦,我也强烈推荐阿里开源的问题定位神器 arthas 来定位问题。
比如上述操作便可精简为一个命令 thread -n 3 即可将最忙碌的三个线程快照打印出来,非常高效。
更多关于 arthas 使用教程请参考官方文档。
由于之前忘记截图了,这里我直接得出结论吧:
最忙绿的线程是一个 GC 线程,也就意味着它在忙着做垃圾回收。
GC 查看
排查到这里,有经验的老司机一定会想到:多半是应用内存使用有问题导致的。
于是我通过 jstat -gcutil pid 200 50 将内存使用、gc 回收状况打印出来(每隔 200ms 打印 50次)。
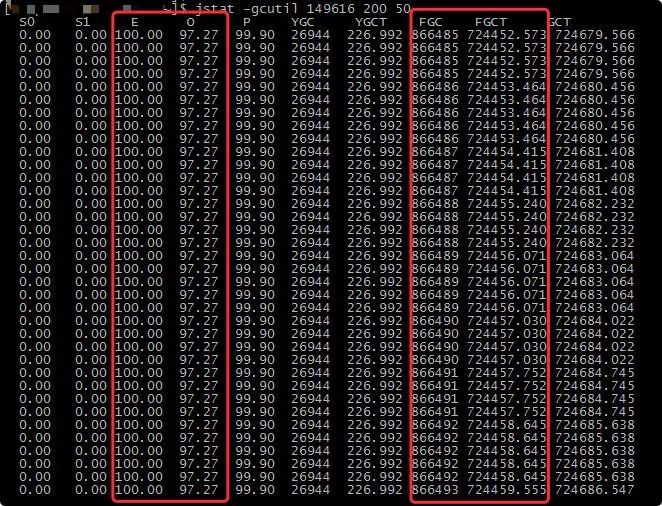
从图中可以得到以下几个信息:
Eden 区和 old 区都快占满了,可见内存回收是有问题的。
fgc 回收频次很高,10s 之内发生了 8 次回收((866493-866485)/ (200 *5))。
持续的时间较长,fgc 已经发生了 8W 多次。
内存分析
既然是初步定位是内存问题,所以还是得拿一份内存快照分析才能最终定位到问题。
通过命令 jmap -dump:live,format=b,file=dump.hprof pid 可以导出一份快照文件。
这时就得借助 MAT 这类的分析工具出马了。
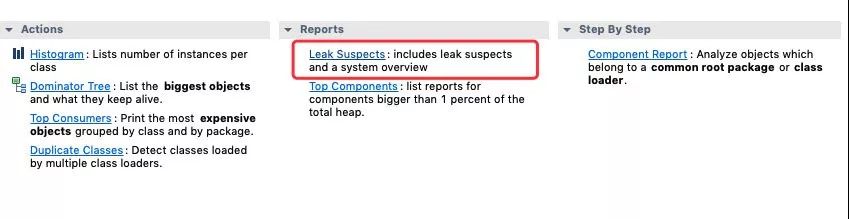
问题定位

通过这张图其实很明显可以看出,在内存中存在一个非常大的字符串,而这个字符串正好是被这个定时任务的线程引用着。

大概算了一下这个字符串所占的内存为 258m 左右,就一个字符串来说已经是非常大的对象了。
那这个字符串是咋产生的呢?
其实看上图中的引用关系及字符串的内容不难看出这是一个 insert 的 SQL 语句。
这时不得不赞叹 MAT 这个工具,他还能帮你预测出这个内存快照可能出现问题地方同时给出线程快照。
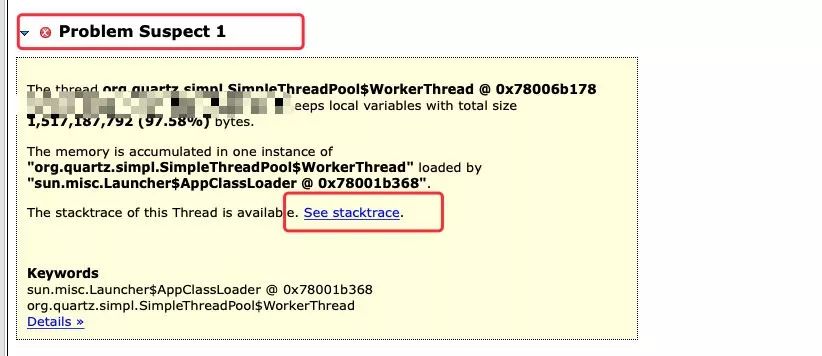
最终通过这个线程快照找到了具体的业务代码:
他调用一个写入数据库的方法,而这个方法会拼接一个 insert 语句,其中的 values 是循环拼接生成,大概如下:
<insert id="insert" parameterType="java.util.List">
insert into xx (files)
values
<foreach collection="list" item="item" separator=",">
xxx
</foreach>
</insert>所以一旦这个 list 非常大时,这个拼接的 SQL 语句也会很长。
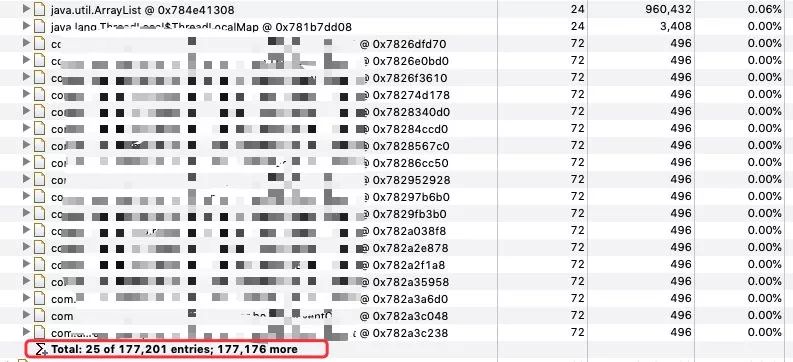
通过刚才的内存分析其实可以看出这个 List 也是非常大的,也就导致了最终的这个 insert 语句占用的内存巨大。
优化策略
既然找到问题原因那就好解决了,有两个方向:
控制源头 List 的大小,这个 List 也是从某张表中获取的数据,可以分页获取;这样后续的 insert 语句就会减小。
控制批量写入数据的大小,其实本质还是要把这个拼接的 SQL 长度降下来。
整个的写入效率需要重新评估。
总结
本次问题从分析到解决花的时间并不长,也还比较典型,其中的过程再总结一下:
首先定位消耗 CPU 进程。
再定位消耗 CPU 的具体线程。
内存问题 dump 出快照进行分析。
得出结论,调整代码,测试结果。
最后愿大家都别接到生产告警。
推荐阅读
(点击标题可跳转阅读)
看完本文有收获?请转发分享给更多人
关注「ImportNew」,提升Java技能

好文章,我在看❤️





