LibRec 每周算法:FTRL原理与工程实践 (by Google)
1. 前言
由于传统的离线批量(batch)算法无法有效地处理超大规模的数据集和在线数据流,Online learning应运而生。因其不需要cache所有数据,可以以流式的方式处理任意数量的样本,使其成为工业界做在线CTR预估时的常用算法。
Online learning的实现方式大致可分为两种:在线凸优化(Online learning convex optimization)和在线贝叶斯(Online learning Bayesian)。本文介绍的FTRL(Follow The Regularized Leader)算法就是Online learning凸优化的一种,由Google于2013年提出并发表[1]。该算法在业界引起了巨大的反响,据说国内外各大互联网公司都第一时间应用到了实际产品中,并取得了不错的业务效果。
在一睹FTRL尊容之前,本文先简单介绍一下工业界常用的推荐系统框架,以便使各位读者能了解到FTRL究竟是在哪个模块发挥着它巨大的功效。
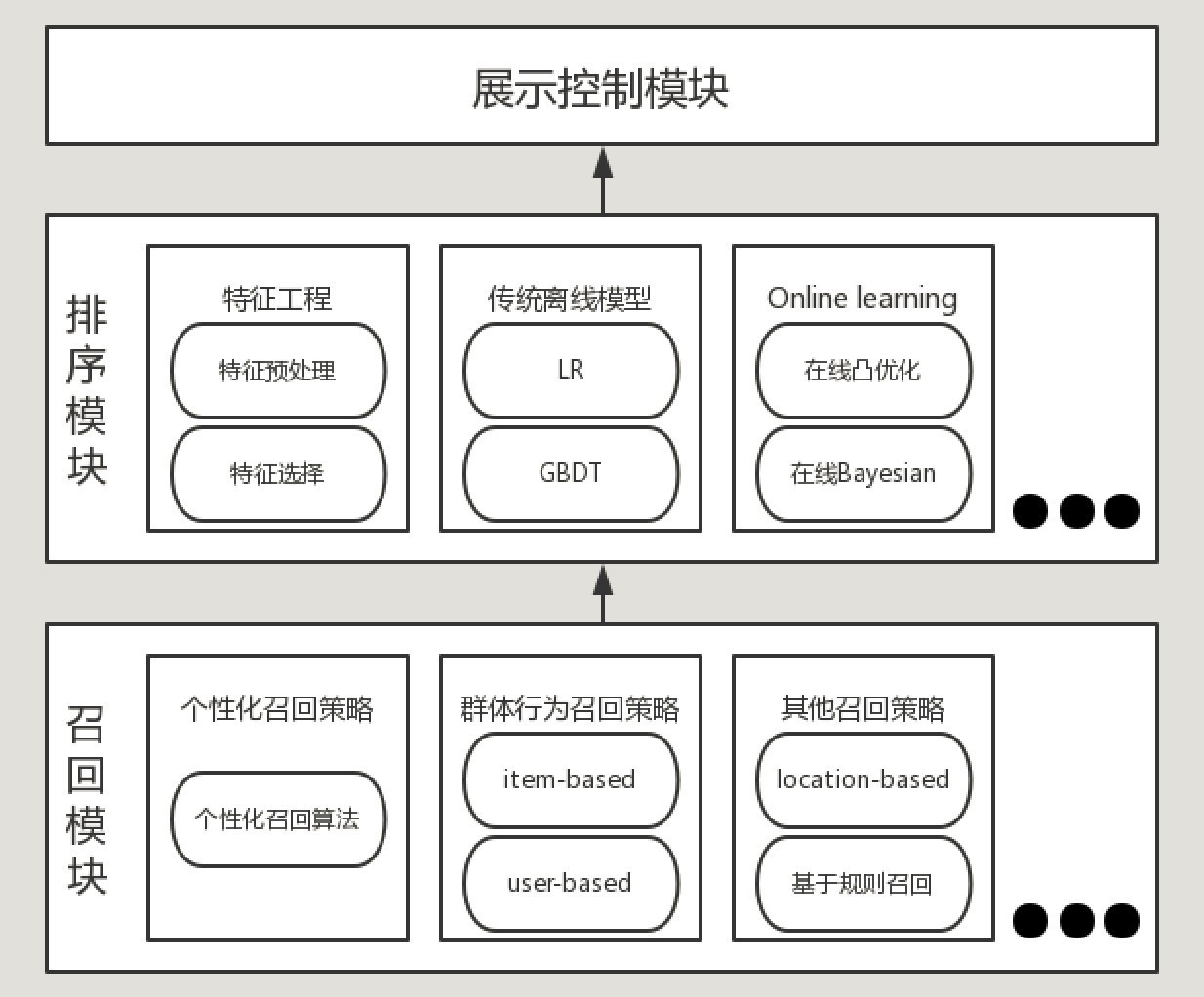
图1.1 推荐系统框架
如图1.1所示,FTRL算法主要应用在工业界推荐系统的排序模块,通过对召回的item集合打分,来实现对item的重排序,以供前端推荐展示调用。
2. FTRL原理介绍
FTRL算法的设计思想其实并不复杂,就是每次找到让之前所有目标函数(损失函数加正则项)之和最小的参数。该算法在处理诸如逻辑回归之类的带非光滑正则化项(如L1正则项)的凸优化问题上表现出色,在计算精度和特征的稀疏性上做到了很好的trade-off,而且在工程实现上做了大量优化,性能优异。
Online learning凸优化算法的设计理念主要有:
正则项:众所周知,目标函数添加L1正则项可增加模型解的稀疏性,添加L2正则项有利于防止模型过拟合。当然,也可以将两者结合使用,即混合正则,FTRL就是这样设计的。
稀疏性:模型解的稀疏性在机器学习中是很重要的,尤其是在工程应用领域。稀疏的模型解会大大减少预测时的内存和时间复杂度。常用的稀疏性方法包括:
L1 正则项,但其效果有限;
Truncated Gradient:通过一些策略,将符合条件的特征权重强置为0,如后文介绍的FOBOS就采用了类似这种方式;
黑箱测试法:除去部分特征,重新训练模型,以检测被消去的特征是否有效。
GD/SGD:GD求解的模型,虽然精度相对较高,但是受限于训练太费时、不易得到稀疏解,以及对不可微点迭代效果欠佳等缺点;SGD则存在模型解的精度低、收敛速度慢和很难得到稀疏解等缺点。虽然学术界提出了很多加快收敛或者提高模型精度的方法(如添加momentum项、添加nesterov项、Adagrad算法[2]、Adadelta算法[3]、GSA算法[4]等),但这些方法在提高模型解的稀疏性方面效果有限,而FTRL在这方面则更加有效。
2.1 FOBOS与RDA
接下来介绍FOBOS和RDA这两个算法,因为FTRL综合了这两个算法的优点,理解了这两个算法将有助于理解FTRL。
2.1.1 FOBOS
FOBOS算法是由Duchi与Singer在2009年提出的,该算法是对投影次梯度(projected subgradient)方法的一个改造,以有效地获得模型的稀疏解。该算法将迭代投影次梯度法拆成两步:
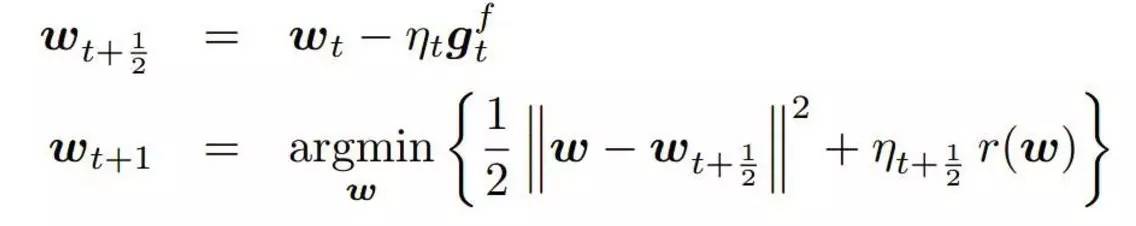
其中在第二步中,第一项使该步的迭代解不要离第一步的临时解太远,第二项为了限制模型复杂度添加的正则项。详细的公式推导过程可参考paper[5].
2.1.2 RDA
RDA算法于2010年由微软提出,该算法相对于FOBOS在精度与稀疏性之间做了平衡,在L1正则下,RDA相较FOBOS可以更有效地得到稀疏解。RDA的权值迭代公式如下:
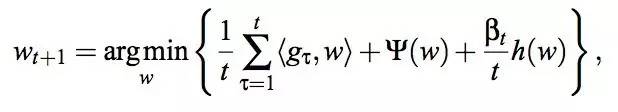
其详细的推导过程,可参见paper[6]。
2.2 FTRL原理
FTRL算法在2013年由Google的Brendan提出,全名为Per-coordinate Follow The Regularized Leader Proximal(全名揭示了算法的一些重要特征),paper中带工程实现的伪代码。
该算法的权值迭代公式和主要推导过程如下:

FTRL融合了RDA和FOBOS的特点,实验表明,在L1正则下,稀疏性与精度都好于RDA和FOBOS。具体实现对比如下:
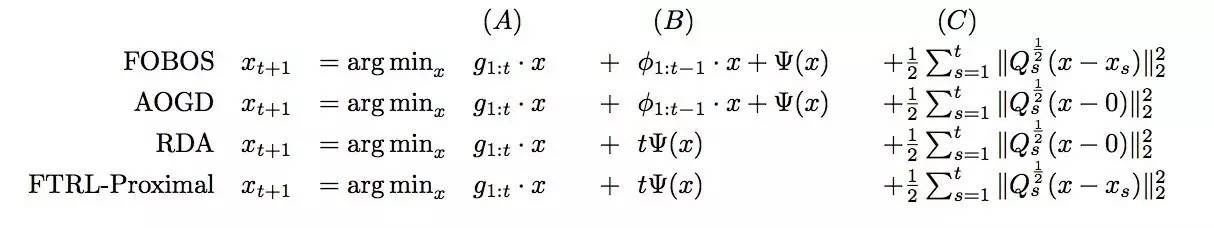
其中(A)代表累积梯度项,(B)代表正则化处理项,(C)代表累加和项(该项限制了新的迭代结果不要与之前的迭代结果偏离太远,也就是FTRL算法中proximal的含义)。
2.3 FTRL工程实现
FTRL的工程实现伪代码如下:

由算法伪代码可以看出,FTRL工程实现部分在理论推导公式的基础上做了一些变换和在工程实现上做了一些trick。其中最值得说明的一点为per-coordinate,即FTRL是对权重向量w的每一维分开训练更新的,每一维使用不同的学习速率,其中学习速率的计算公式为:
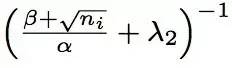
其中,beta和lamda2等输入参数是可以省略简化掉的,输入参数的具体设置方式可参考paper[1]中给的建议。
3. 工程实践的一些经验
下面介绍为FTRL-Proximal准备训练数据(特征工程)和训练模型时的一些trick。
(1) 特征工程
特征预处理:ID化、离散化、归一化等;
特征选择:方差、变异系数、相关系数、Information Gain、Information Gain-Ratio、IV值等;
特征交叉和组合特征:根据特征具有的业务属性特征交叉,利用FM算法、GBDT算法做高维组合特征等。
(2) Subsampling Training Data
正样本全采样,负样本使用一个比例r采样,并在模型训练的时候,对负样本的更新梯度乘以权重1/r;
负采样的方式:随机负采样、Negative sampling、邻近负采样、skip above负采样等。
(3) 在线丢弃训练数据中很少出现的特征(probabilistic feature inclusion)
Poisson Inclusion:对某一维度特征所来的训练样本,以p的概率接受并更新模型;
Bloom Filter Inclusion:用bloom filter从概率上做某一特征出现k次才更新。
猜你喜欢
参考文献
[1] Mcmahan H B, Holt G, Sculley D, et al. Ad click prediction: a view from the trenches[C], KDD 2013.
[2] Duchi, John, Elad Hazan, and Yoram Singer. "Adaptive subgradient methods for online learn- ing and stochastic optimization." JMLR 2011.
[3] Zeiler, Matthew D. "ADADELTA: an adaptive learning rate method." arXiv 2012.
[4] Zhang X, Yao F, Tian Y. Greedy Step Averaging: A parameter-free stochastic optimization method[J]. 2016.
[5] John Duchi Y S. Efficient learning using forward-backward splitting[J]. NIPS 2009.
[6] Xiao L. Dual Averaging Methods for Regularized Stochastic Learning and Online Optimization[M]. JMLR 2010.


