学界 | 百度提出问答模型GNR:检索速度提高25倍
选自Baidu Research
作者:Jonathan Raiman & John Miller
机器之心编译
参与:刘晓坤、李泽南、蒋思源
近日,百度人工智能实验室的 Jonathan Raiman 和 John Miller 提出了在问答类检索提取答案的新方法 Globally Normalized Reader(GNR),通过将问答类检索当成搜索问题,选取关键句子、标定起始词和终止词定位答案,在得到相同表现水平的同时降低了计算复杂度,并能有效应对过拟合。GNR 在斯坦福 SQAD 数据集的实验中得到了单个模型第二位的表现水平,比双向注意流快了 24.7 倍。
论文:Globally Normalized Reader

论文链接:http://aclweb.org/anthology/D17-1112
代码:https://github.com/baidu-research/GloballyNormalizedReader
我们提出了提取答案的问答类检索的新方法 Globally Normalized Reader(GNR),它和以前的方法有相同的表现水平,但是计算复杂度更低。很多流行的模型比如双向注意流(Bidirectional Attention Flow)使用计算费力的注意机制,而其它的比如 Match-LSTM 会对所有可能的答案评分。相反,GNR 把问答类检索当作一个搜索问题,应用了一个学习搜索的框架。我们在斯坦福问答类检索数据集(Stanford Question Answering Dataset,SQAD)的实验中得到了单个模型第二位的表现水平,比双向注意流(bi-attention-flow)快了 24.7 倍。
所有的顶尖神经问答类检索系统都面临过拟合的困难。为了帮助解决这些问题,我们还提出了第一个成功的针对神经问答类检索的数据增强技术 Type Swaps。利用 Type Swaps 进行数据增强后,可以降低我们模型的生成错误,并在 SQuAD 开发集的训练中得到了 1% 提升的 EM。
通过搜索进行问答类检索
为了回答「Nikola 在哪一年去世?」这样的问题,我们可以浏览维基百科,查看文章:
Nikola Tesla(塞尔维亚西里尔文:Никола Тесла;1856 年 7 月 10 日 – 1943 年 1 月 7 日)是美国塞尔维亚裔发明家、电机工程师、机械工程师、物理学家和未来学家,他最著名的贡献是现代交流电(AC)供应系统的设计。
问答系统(QA)和信息提取系统被证明在很多类应用中比如关于药物和基因的医疗信息收集,大规模健康影响研究,或者教育材料发展现状。基于问答提取模型的神经网络的最近进展表明,其在多个基准的 QA 任务(比如 SQuAD、MS MARCO 或 NewsQA)中的表现正快速接近人类水平。然而,目前的问答提取方法仍然有很多局限性:
计算资源被平均分配给了整个文档,而不顾答案的定位,不能忽略无关部分或者集中计算特定的部分,这限制了在长文中的应用;
过分依赖计算费力的双向注意机制,或者不得不按等级列出所有可能的答案;
虽然问答系统的数据增强方法已经提出,目前的方法仍然不能提供训练数据提升现有系统的表现水平。
我们的方法是将提取答案的问答类检索作为一个迭代搜索问题:选择答案的句子、起始词和终止词。在每一步通过选择简化搜索空间,从而将计算集中于相关性最大的部分:潜在搜索路径。
我们证明了全局标准化决策过程和通过束搜索进行反向传播,可以进行这种表示,提高学习效率。我们在斯坦福问答类检索数据集的实验中得到了单个模型第二位的表现水平(比双向注意流(bi-attention-flow)快了 24.7 倍),从而证实了我们的观点。
我们还介绍了一种数据增强方法,通过匹配知识库中的命名实体并按相同的类型替换新的命名实体,生成符合语义逻辑的例句。这个方法提升了我们研究中所有使用的模型的表现水平,对多种自然语言处理任务有独立的增益效果。
GNR 是怎么工作的?
举一个例子来说明我们的方法:「是谁第一个认识到分析机(Analytical Engine)有超出纯粹计算以外的应用的呢?」,我们阅读以下一段文字来回答这个问题:
Ada Lovelace 因她对 Charles Babbage 分析机的研究而为人所知。她第一个认识到分析机有超出纯粹计算以外的应用。于是,她经常被认为是认识到「计算机器」全部潜能的第一人,以及第一个计算机编程者。
文中不是每一部分都和问题相关,所以我们需要在早期先探测答案可能出现的地方。GNR 将这种直觉翻译为逐渐选取文档的各个子部分。下方展示了这个过程,其中垂直条形表示决策概率,并用盘桓的节点强调文档中正被考虑的部分。
提取答案的问答类检索问题是从给定的通道中提取死亡日期,「1943 年 1 月 7 日」。GNR 将问答类检索当做一个搜索问题。首先,寻找包含正确答案的句子。然后,寻找句子中答案的起始词。最后,寻找答案的终止词。这个过程在下方中展示。
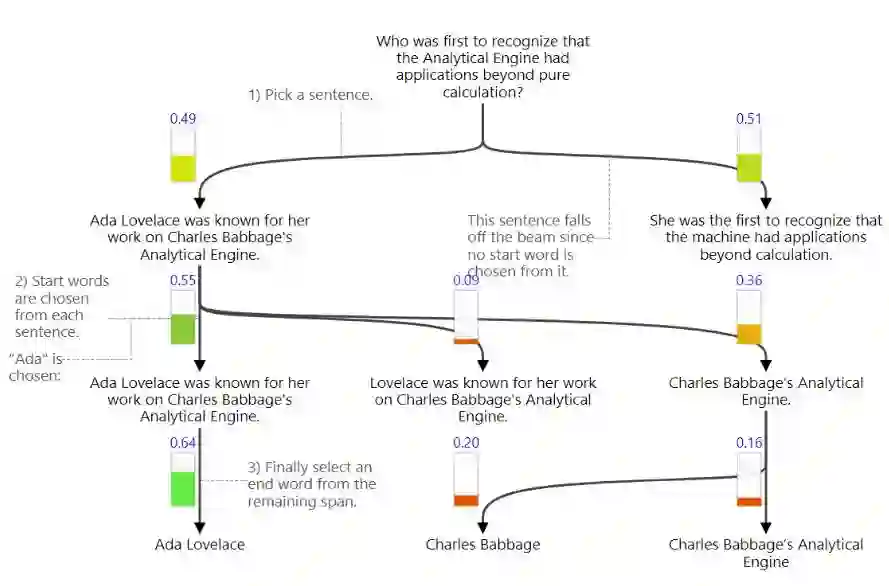
一旦 GNR 在文档中选择了一个句子,就可以对该句子做更深入的挖掘。在以下列出的图表中我们可以看到它是如何集中注意于所有句子中的一个,然后选择句子中的正确词子集:
有很多方法能将句子、起始词和终止词选择的概率分布参数化。GNR 其中一个关键部分就是用全局(和局域相反)标准化方法将分布参数化。
在全局标准化模型中,分布在全部的元数组上标准化,而局域标准化模型中,句子、起始词和终止词的每一个选择都被分别标准化然后用链式法则连乘起来。
全局标准化使模型更具表现力,使它更加容易从搜索错误中恢复。我们的研究展示了全局标准化使 EM 增长了 1%,并达到了顶尖的表现水平。
学习如何搜索
Ada Lovelace was known for her work on Charles Babbage's Analytical Engine. She was the first to recognize that the machine had applications beyond calculation. As a result, she is often regarded as the first to recognise the full potential of a "computing machine" and the first computer programmer.
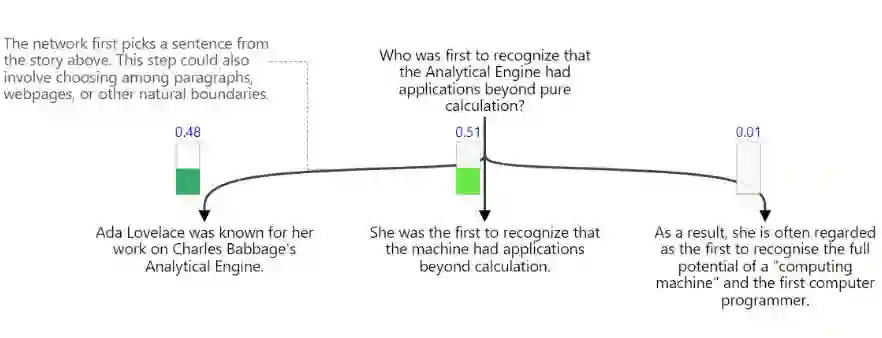
即使全局归一化模型具有良好的表征性能,但它却又提出了更大的计算挑战。特别地,评估任何特定元组(句子、起始词和终止词)需要对所有类似的元组进行求和以计算归一化常数,即在一组「# sentences * # starting words * # ending words」的和。
为了克服这一挑战,我们采用了束搜索。特别地,我们仅对最终束搜索候选项求和以逼近在所有元组上的求和结果。
在测试时,我们通过束搜索获取最高排序的候选元组。这就意味着该模型只需要对 O(束大小)候选回答的跨度进行评分,而不需要如同常用方法那样对所有可能的跨度进行评分。该过程减少了模型训练与评估之间的差异,并且是对现有方法提供 GNR 20 倍加速的关键。
学习如何搜索的成功点在哪?
现在已经有一些方法在多种 NLP 任务和条件计算上学习如何搜索。最近有展示表明了全局归一化网络和使用束搜索进行语音标注和基于转化的依存句法分析的有效性。而 Wiseman 等人在 2016 年就表示这些技术可以应用于序列到序列模型,包括机器翻译等潜力巨大的应用领域。这些工作关注于解析和序列预测任务,并且具有固定计算而不管搜索路径,但我们表示相同的技术也可以直接应用于问答系统并扩展到允许基于搜索路径的条件计算。
在一些研究中,学习如何搜索同样可以应用于带有条件计算的模块化神经网络。在他们的研究工作中,强化学习可以用于学习如何打开或关闭计算,但我们发现条件计算能很容易通过最大似然而学到这一点,然后再帮助早期的更新以引导训练过程。
下一步
我们相信广泛的结构化预测问题(代码生成、图片生成模型、音频或视频)最终都能够实现,即使目前因为原始搜索空间过大而限制了技术的发展,但如果利用条件计算并作为学习如何搜索的问题,那么结构化预测问题最终会得到解决。
我们如何生成 quasi-infinite 数据

几乎所有目前在 SQuAD 问答上使用神经网络的方法都受限于过拟合问题,必须进行大量规范化才能保证获得足够好的结果。在机器学习的其他领域,如图像和语音识别,研究人员通过数据扩充来提高泛化效果。然而目前还没有人提出在问答任务中使用数据扩充的方式。为了解决这个问题,百度研究人员提出了 Type Swaps,一种全新的策略,可以生成大量合成的 QA 范例。同时,研究人员验证了 Type Swaps 可以提升 GNR 的表现。
类型互换通过识别文档中的问题实现,随后通过 WikiData 来制成相近类型的新实体。由于 Wikidata 包含相当数量的实体,我们可以生成相当数量的新范例。
我们发现通过增加类型敏感的合成示例可以提高所有模型的表现,在研究中可以提高性能最好的 GNR 模型 2% 的 EM。由于这些改进并不与架构选择有关,理论上这种提升方法可以适用于不同类型的模型,应该也可以适用于其他包含命名实体,使用有限监督数据的自然语言任务中。
类型互换,我们的数据增加策略提供了一种在模型学习过程中整合问题与回答来减少表面变化敏感性的方法。目前的神经网络提取 QA 的方法忽略了此类信息。通过类型敏感合成示例,增强数据集可以通过覆盖不同的回答类型来提升系统表现。在研究中,我们发现增加使用的增强样本数量可以提升所有模型的表现。
除了增加一定数量,我们也观察到了性能的降级。这表明即使增加的数据非常接近于原始训练集,在训练时仍然会产生不匹配与重复。
例子
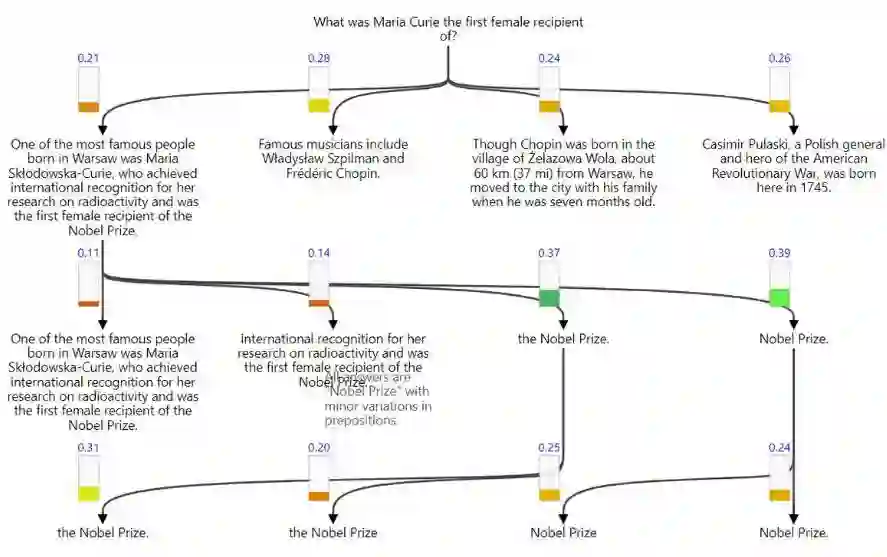
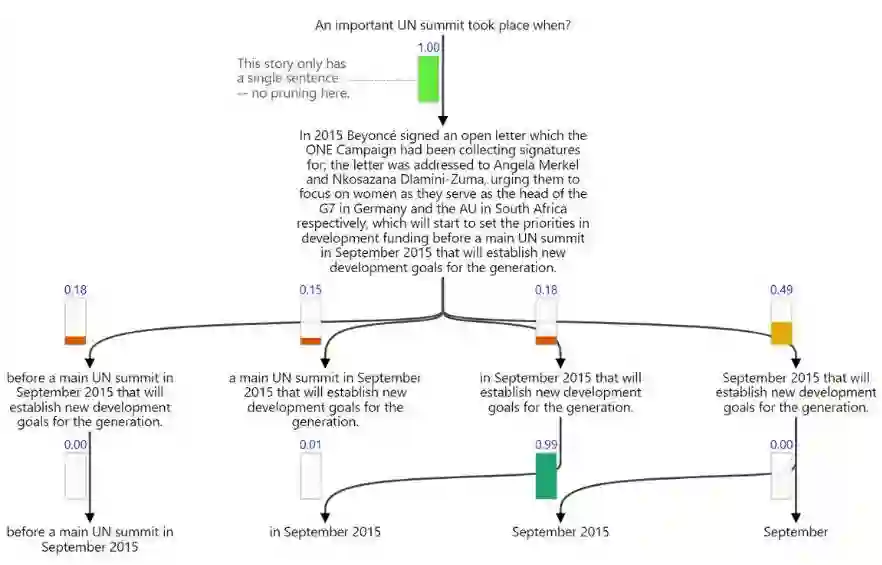
为了更好地介绍模型的性能,以下列出了一些参考问题,文档和搜索树:
One of the most famous people born in Warsaw was Maria Skłodowska-Curie, who achieved international recognition for her research on radioactivity and was the first female recipient of the Nobel Prize. Famous musicians include Władysław Szpilman and Frédéric Chopin. Though Chopin was born in the village of Żelazowa Wola, about 60 km (37 mi) from Warsaw, he moved to the city with his family when he was seven months old. Casimir Pulaski, a Polish general and hero of the American Revolutionary War, was born here in 1745.
In 2015 Beyoncé signed an open letter which the ONE Campaign had been collectingsignatures for; the letter was addressed to Angela Merkel and Nkosazana Dlamini-Zuma,urging them to focus on women as they serve as the head of the G7 in Germany and the AUin South Africa respectively, which will start to set the priorities in development fundingbefore a main UN summit in September 2015 that will establish new development goals forthe generation.
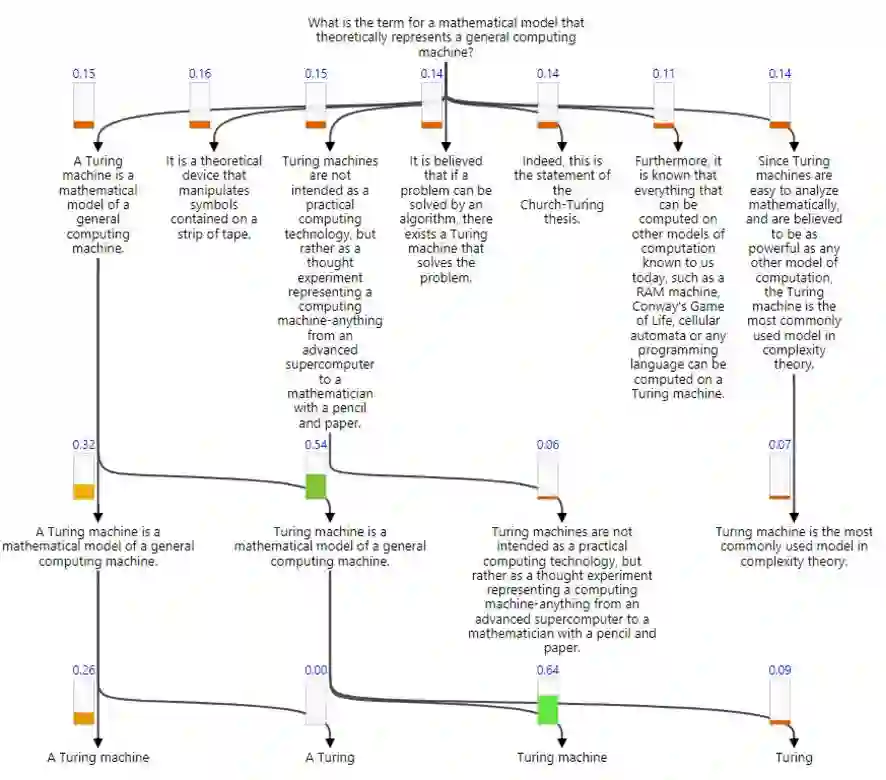
A Turing machine is a mathematical model of a general computing machine. It is a theoretical device that manipulates symbols contained on a strip of tape. Turing machines are not intended as a practical computing technology, but rather as a thought experiment representing a computing machine-anything from an advanced supercomputer to a mathematician with a pencil and paper. It is believed that if a problem can be solved by an algorithm, there exists a Turing machine that solves the problem. Indeed, this is the statement of the Church-Turing thesis. Furthermore, it is known that everything that can be computed on other models of computation known to us today, such as a RAM machine, Conway's Game of Life, cellular automata or any programming language can be computed on a Turing machine. Since Turing machines are easy to analyze mathematically, and are believed to be as powerful as any other model of computation, the Turing machine is the most commonly used model in complexity theory.
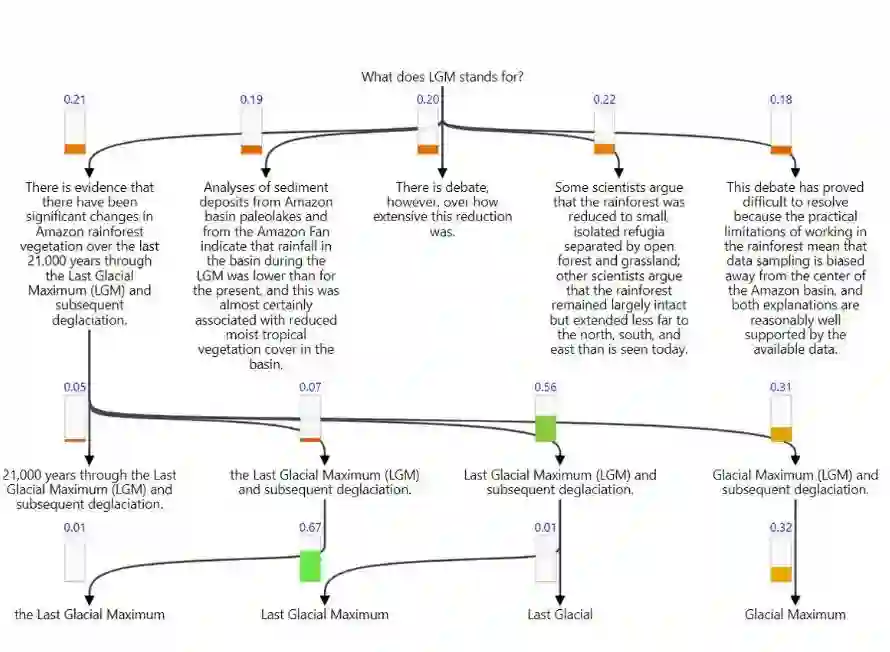
There is evidence that there have been significant changes in Amazon rainforest vegetation over the last 21,000 years through the Last Glacial Maximum (LGM) and subsequent deglaciation. Analyses of sediment deposits from Amazon basin paleolakes and from the Amazon Fan indicate that rainfall in the basin during the LGM was lower than for the present, and this was almost certainly associated with reduced moist tropical vegetation cover in the basin. There is debate, however, over how extensive this reduction was. Some scientists argue that the rainforest was reduced to small, isolated refugia separated by open forest and grassland; other scientists argue that the rainforest remained largely intact but extended less far to the north, south, and east than is seen today. This debate has proved difficult to resolve because the practical limitations of working in the rainforest mean that data sampling is biased away from the center of the Amazon basin, and both explanations are reasonably well supported by the available data.
原文地址:http://research.baidu.com/gnr/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




