寒冬缩招 | 如何拿下年薪40万,这几大点分享给你


临近年底,互联网正在经历寒冬,不少公司出现了裁员新闻,也有很多人纷纷转型、跳槽。今天,小编和大家分享一篇从传统IT转行AI的面经,一位从事多年C语言开发转CV算法拿到年薪40万,希望对大家转行或跳槽的同学有所帮助~
以下面经内容全部来自吴同学~
本人背景:985本,专业软件工程,到目前为止工作6年,做过C语言开发,python开发等工作;机器学习方面在2017年年底开始接触,自己主要学习了七月在线的深度学习集训营和计算机视觉第二期、吴恩达的深度学习课程、李飞飞的cs231n、udacity的机器学习纳米学位等课程,2018年开始在自己原有单位实用深度学习方法做网络流量方面的一些分析工作,主要基于类似TextCNN和img2txt的一些方法。
因为对CV比较感兴趣,想要转往该方向,今年10月中旬后开始更新简历找CV方向的工作。这此跳槽中感觉颇为艰辛——很多CV相关工作都要求硕士学历,年底又碰上互联网寒冬缩招裁员的,我这样之前做了多年开发,并没有CV直接相关工作经验的,猎头来推的都是开发工作,招聘网站上投简历也基本没什么回应,我自己也因为时间少以及公司方面有所筛选,因此CV方面的算法工作实际去onsite参加面试的机会都很少。虽然可能感觉并不是比较成功的一次求职经历,很多地方都没做到本来可以达到的更好的状态,依然和大家分享一下,也可以作为经验和教训。话说因为原单位的项目没能完结掉,现在拖了两个月才刚入职,最近听闻各种互联网寒冬裁员的报道,真是让人非常担忧,也希望分析能够攒点人品,保我别在试用期里被裁员吧~
下面的面经只记录了CV算法相关的一些问题,数据结构算法的考题之类没特意留意记录下来,HR面也都不涉及。就数据结构算法这方面我自己也就是准备面试期间看看剑指offer和leetcode的简单题的水平,现在已经不怎么刷题了,年轻的童鞋们还请自己加油...此外面试题目下都是我个人当时的回答,存在各种问题,仅供参考,欢迎大家斧正指点。
某上市互金企业 计算机视觉算法工程师
先是介绍了一下自己的项目,由此引申到了下面的问题:
(1)inception系列的结构特点、resnet的结构特点
我画了一下相关的结构,inception主要提到了每个block里多个不同的filter size的分支最后合并起来,这是让网络能够自主地学到用哪种filter size更好而非人工去设置,还提到了v2和v3在结构上的变化如用两个3*3代替5*5,用1*3和3*1代替3*3等,这些都降低了参数量,增加了非线性;resnet主要提到了short cut,因为这个的原有所以能够解决梯度消失的问题,因为有short cut把经过几层卷积前的结果直接和卷积后的结果相加,即使最差情况经过卷积后结果的权重都是0了,加上卷积前的结果也还是和卷积前一致的。
(2)面试官表示上述的描述,都是在结构上能够看出来的,有没有什么个人更深层次的理解
没能想到还有什么深层次的理解...
(3)有没有一些自己针对一些场景设计的结构、loss函数等
提到了自己项目中设计的一些卷积网络的结构,一些竞赛里涉及实用多任务学习的方式来获得更好的效果(比如同时做分类和detection的任务);自己没有设计过什么特殊的loss函数。
(4)有没有除了翻转拉伸加噪点等等之外的,自己针对场景设计的独特的数据增强方式?
提到了u-net里那种加网格然后加以扭曲的方式(根据grid做elastic transform),不过这也不算是独创的...还提到了在kaggle走神司机检测竞赛里看到的,把图片切割维左右两半再和别的切出来的拼起来的方式(原理是根据模型对原图生成的热力图分析,模型实际关注的就是图片中司机头部和手部两个位置,分别在图片左右两半)。另外最近我还学到了针对CV的一种新数据增强方式(海康威视在2016年imagenet的场景分类任务中提出的),在这里做个补充:在场景分类(比较高层的语义图像分类项目)中如果随机在原图中扣取一定的图片来作为数据扩增,很可能并不有效(比如海滩的场景中扣出来树和天空的图片,但是树和天空完全可能出现在各种其他场景中,这样的数据增强可能反而会造成混乱,反而降低效果),新方法是用原本数据训练出来的模型对训练图片生成热力图,然后抠出来相应较强部分的图片作为数据增强——这是一种监督式的数据增强方法。
(5)怎么做人脸年龄的检测?
对这个问题我完全没有思考过,后面都是自己当时随便说说的,实际上至今也没想到很好的方法——先尝试对每个年龄分类,比如100个类。或者尝试能否把比如100个年龄分成几个稍微少一点的类,比如每10个年龄一分组来进行粗略的分类,随后再对每个年龄分组的里面训练细分类的模型...又思考能否使用细粒度的方式,使得不同年龄训练得比较分开然后通过检索的方式...
(6)怎么做有没有PS痕迹的检测,具体来说比如一个证件照和人脸的合影,如何确认人脸部分不是P上去的?
首先想到的是能否获得足够多的PS图片来做分类,简单得来分类是否有PS;随后又想到先detect出来身份证上的人脸部分,和照片里真人脸的部分比对,是否能发现非常大程度上一致,可能是把身份证上的头P到了真人头部分...(和上个问题一样,应该是拍拍贷业务常常涉及到的对接待人上传的照片审核的业务场景,对这块都没啥思考)。
(7)如果用添加PS处理的图片来做数据增强,万一把美颜摄像的也认为是有PS的怎么办?
我相信PS的模式回合美颜的存在一些区别,能否也收集到美颜摄像的图片,多加一个单独的美颜的类别识别?
(8)遇到一个新的问题,会是如何着手去做?
先去网上检索有没有相关领域比较权威的做法,比如paper啦,开源实现啦,相似的竞赛啦等等,有的话进行参考,然后根据自己的问题进行相应的修改尝试,能否取得好的效果。找不到的话,会看看有没有一些相似的,或者其他接近领域的想法,能否能够借鉴的,随后引申到自己项目借鉴的TextCNN和img2txt上去了。
某工业AI创业公司 计算机视觉算法工程师
(这场面试时候比较认真都录音了,所以题目都记得很清楚...其他面试时候好像都懒了没搞...)
同样在介绍了自己的项目后,问到了下面这些的问题:
(1)LSTM和RNN的区别:
LSTM比RNN多了很多控制的门,通过这些门它能够学到哪些记忆需要被保留,哪些要遗忘;所以它能够一定程度防止梯度消失,记住比较长的之前的内容。(之前还准备记了LSTM各种门的结构,不过也没细说)。
(2)LSTM相对于RNN的优点:
普通RNN因为梯度消失的关系记不住很远的内容。
(3)为什么要做卷积,为什么卷积在图片处理上效果非常好?
卷积像是一个滤波器,对于图片每个位置都去获取一个它所关注的模式,具有平移不变性,对每个位置都去获取其所关注的部分。
(4)为什么不直接在图像上做全连接而是用卷积?
全连接的参数非常多,容易过拟合,还会把位置信息给去除掉。
(5)还有最重要的还有的是什么?主要问题还有参数太多的问题
卷积还有具有稀疏性,参数共享的特点。
(6)说一些经典的CNN的网络如alexnet,resnet和inception等
(基本上说的和上面讲的差不多那些东西,不展开了,大家自己查相关资料)
(7)global pooling和全连接比的好处在哪儿?
全连接的参数量很多,在整个网络中占有的参数比例太大,可能会容易导致过拟合。
(8)global pooling还有什么好处?
global pooling还可以使得模型不必像全连接那样必须固定输入图片的尺寸了(想不到其他的了,不知道这个是不是也算是好处)。
(9)1*1卷积有啥作用?
能够升维降维,能够对不同channel信息进行混合。
(10)谈谈dropout?
现在用的不多,主要是全连接的时候会接dropout。
(11)只有全连接时候用dropout是吗?
额,我是这样的,感觉面试官不太认同...(后来查阅了相关的资料,还是觉得在卷积层加dropout效果并不好,主要是因为图像每个像素位置和周围可能在常常可能比较相关有不少冗余的部分,经过CNN和池化以后很可能就对某些个点dropout不敏感了;现在有些新的dropout方法,如15年的spatialdropout方法,随机选择某些channel来drop;又如18年的dropblock方法,在卷积后的结果上选择一块块连起来的部分drop)。
(12)dropout主要作用是什么?
是防止过拟合。
(13)为什么能防止过拟合?
dropout在每个batch的训练中会随机失活一些连接,假设在没有失活的情况下某个连接权重很大,这种情况就容易过拟合,当把这个连接失活以后,就要依赖别的连接去重新训练能够适应的情况;从另外一个角度来说,这也有一种集成学习的效果,因为每次随机失活一部分训练,都像是训练了不同的网络。
(14)介绍一下BN:
在batch中,在一个层的输出结果后多做了一个标准化的操作,也就是减去均值除以标准差的操作,相当于就是把分布拉到了0均值单位正太分布的地方,这样的分布就使得数据往激活函数的线性部分更加靠拢,缓解了梯度消失的情况,可以加速训练收敛;但是这样也就改变了学习到特征,为了防止这个问题也为了防止模型的非线性变弱,BN还有两个独立的拉伸w和偏移b的可训练参数,用来重新对数据继续拉伸和偏移,让数据再被拉到0均值单位正太分布后再重新往非线性上恢复,这样也就使得网络的非线性能力得恢复,同时也使得每层数据分布与之前层的结果解耦,在线性防止梯度消失和非线性上取得均衡。
(15)平时会用到BN吗?
A: 因为比较多的情况是用迁移学习,改动模型不多的时候不会用;在自己的项目设计网络时候会有用到。
(16)说到迁移学习,你是怎么做迁移学习的呢?就是预训练的网络,最后几层再那个?
对,就是先把最后一层分类去掉改成需要分类的几个输出;然后逐渐往上开锁定的层。
(17)怎么监控模型的好坏,有啥评价指标?
在训练的时候先看loss,有没有在正确地下降;等到能够overfit,loss下降收敛以后再去看其他的评价指标,比如准确率,f1 score等;我自己项目中主要也就看看准确率。
(18)如果有个非常不平衡的数据集,可能正样本占1%,负样本 占99%,这个时候用什么评价指标?
会看是不是一个类似异常检测的问题,那一个占比很小的类是否很重要
(19)不一定
我表示没有要留意是不是很小的那个类别的话那就用f1 score吧...
(20)ROC和AUC记得怎么画吗?
这俩我当时不怎么记得了;就记得PR曲线...(提起了这俩,就这个就知道上面讲错了吧,不平衡的数据可以看AUC的,对这种情况不敏感...)
(21) 其他一些机器学习如线性回归,逻辑回归,树等方法有所了解吗?讲一下xgboost?
没用过不大了解...(这个没用到过一直没看,果然大家都喜欢问...)
(22)说一下二分类的log loss函数:
就写了一下公式...
(23)发现一个网络训练地过拟合了的话,能想到的要做的步骤会是什么?
训练到过拟合以后,先加一些限制过拟合的比如dropout,l2正则化等;如果还是比较厉害,我会考虑是否模型过于复杂了,可能会选择换轻量级的模型,或者把模型调整简单比如把层数,channel数消减;然后就是做数据增强,如果有可能的话最好能收集更多的数据。
(24)做过NLP的东西吗?对有什么了解过的算法?
做数据迁移可能会用别人训练好的word-embeding;训练embeding可以用skip gram...NLP方面也了解地不多。
平安金融壹帐通 算法落地工程师
一样地先介绍了自己的项目,然后问了下面这些:
(1)卷积怎么算的
这个很基础,不详述了...我就是回答时候稍微提到了点depth-wise之类特殊点的卷积。
(2)RNN是什么样的,LSTM是什么样的,什么用;LSTM的起始cell state是多少?
基础的概述也就不展开了;关于LSTM的其实cell state当时没有答上来,平时我好像都是用的框架默认的,没试过可以调这个...后来差了点相关资料(https://r2rt.com/non-zero-init ... .html),有兴趣大家自己看,篇幅有限也不展开了。
(3)除了CNN,RNN,还用过其他什么深度学习的模型的吗?比如GAN是什么,讲一下。
关于GAN的描述也直接网上查就可以了;当时自己也说得不太好,学了以后没用过也没好好关注过...另外其他的还可以提提deep and wide模型之类的。
(4)就我做过的一个根据triplet loss和多任务学习实现的车辆细粒度型号分类项目,问了具体的实现。
triplet loss是做人脸识别,各种reid的细粒度分类的常用loss,(另外一种是孪生网络),通过triplet loss来学习anchor、positive和negative三个样本之间差异,让anchor和positive(同一类的两个训练数据)的距离比anchro和engative(和anchor不同类的训练数据,应通过hard-mining精良选择和anchor相似的数据)的距离远。具体定义可以直接查询网上定义。
(5)tensorflow的模型怎么存的,怎么上线的?
因为好久没有生成pb文件了,我都忘了pb文件的后缀了,直接就和面试官说我是直接存的(其实我指的就是生成pb,不是训练时候的save...);上线这方面我还没啥经验,我之前的项目实际上都还没有实际上线的,都还没很好落地呢...
(6)因为提到了可以用知识蒸馏的方式来压缩模型,让我介绍知识蒸馏怎么做的;为什么蒸馏出来的小模型有用?
参考 https://zhuanlan.zhihu.com/p/39945855
(7)怎么设计的网络,filter尺寸,个数等等?
这个部分我建议参考“解析卷积神经网络——深度学习实践手册”这本小书里“网络超参”设定里提到的一些内容。还提到了根据数据大小规模会相应修改模型复杂程度,比如数据少而且过拟合严重,我可能会尝试把原有模型的channel先都减半之类的操作。另外还可以参考最小的各种研究结果的实现,参考res-block, se-block, inception-block等经典结构作为一些组件插入自己的设计中。
(8)tensorflow训练中如何优化训练速度
tensorflow有profile工具可以观察具体各个部分的耗时,可以针对性地修改模型进行调整。还有比如可以把input-pipeline放到cpu上做prefetch,然后同时gpu上在进行训练,两者互相之间是一定并行的关系;在pipeline上加cache会很显著地提高数据阐述效率,提高GPU利用率。
该面经首发于七月在线官网社区(https://ask.julyedu.com)
打开如下链接可在线直接与大佬交流喔~

https://ask.julyedu.com/question/86871?from=timeline


今日学习推荐
【机器学习集训营第七期】
火热报名中
前一百二十人特惠价:14399元
2019年1月14日开课
三个月挑战年薪四十万,甚至拿更高薪~
2018年底之前报名加送售价2699元的18VIP
[包2018全年在线课程和全年GPU]
两人及两人以上组团还能各减500元
有意的亲们抓紧时间喽
咨询/报名/组团可添加微信客服
julyedukefu_02
☟

长按识别二维码


2018.12.24-2019.1.7
经典好课 免费畅学
长按识别下方二维码,关注公众号:七月在线
回复数字:77 立即开始畅学之旅

长按识别二维码
有机会获得机械键盘,硬盘,蓝牙耳机等炒鸡福利



仅部分奖品展示,更多详情见双旦会场
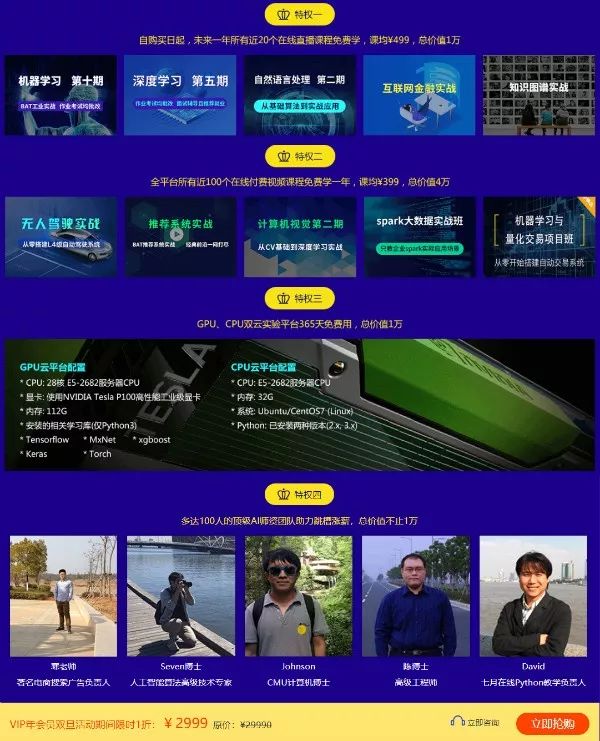
VIP年会员震撼升级 1折开抢
四大特权 畅学整年
100本纸质西瓜书免费包邮送
加送《数据挖掘》课程
长按识别下方二维码 后台回复:1224
进群领取

长按识别二维码
更多精品课程、一元秒杀、特惠等炒鸡福利
尽在年终回馈会场
长按识别下方海报二维码进入
☟

往期推荐
GitHub标星10k,从零开始的深度学习实用教程 | PyTorch官方推荐
AI今年最大进展就是毫无进展?2019年AutoML、GAN将扛大旗
点
点击阅读原文,进入主会场




