阿里云块存储团队软件工程实践

“我背上有个背篓,里面装了很多血泪换来的经验教训,我看着你们在台下嗷嗷待哺想要这个背篓里的东西,但事实上我给不了你们”,实践出真知。
-
编码习惯(开发、测试、Review,Bad/Good Case) -
研发流程(源码控制、每日构建、缺陷管理)
-
实践方法(效率工具、新人踩雷、学习推荐)
一、编码习惯
Ugly is easy to identify because the messes always have something in common, but not beauty. -- C++ 之父 Bjarne Stroustrup
代码质量与其整洁度成正比。 -- 《代码整洁之道》作者 Robert C. Martin
1.1 开发

要点1 :语义简单明确
bool throttle_is_quota_valid(int64_t value){// 复杂的判断条件// 请你在三秒内说出 value 如何取值是合法的?if (value < 0 && value != THROTL_UNSET && value != THROTL_NO_LIMIT){return false;}return true;}bool throttle_is_quota_valid(int64_t value){// 这是修改后的代码,value 取值合法有三种情况,一目了然return value >= 0 || value == THROTL_UNSET || value == THROTL_NO_LIMIT;}
要点2 :简洁 ≠ 代码短
void RecycleBin::Load(BindCallbackR1<Status>* done){......FOREACH(iter, fileStats){RecycleFile item;Status status = ParseDeletedFileName(iter->path, &item.timestamp);if (!status.IsOk() { ...... }item.fileName = iter->path;item.size = iter->size;item.physicalSize = iter->refCount > 1 ? 0 : iter->physicalSize;......// 这是修改前的代码// earliestTimestamp[item.medium] =// item.timestamp != 0 && item.timestamp < earliestTimestamp[item.medium] ?// item.timestamp : earliestTimestamp[item.medium];// }// 这是修改后的代码if (item.timestamp != 0 &&item.timestamp < earliestTimestamp[item.medium]){earliestTimestamp[item.medium] = item.timestamp;}}......}
Status Foo(){Status status = Check1();if (!status.IsOk()){return status;}else{status = Check2();if (!status.IsOk()){return status;}else{status = Check3();if (!status.IsOk()){return status;}else{DoSomeRealWork();return OK;// 四层潜套 if}}}}
Status Foo(){Status status = Check1();if (!status.IsOk()){return status;}status = Check2();if (!status.IsOk()){return status;}status = Check3();if (!status.IsOk()){return status;}DoSomeRealWork();return OK;}
void Foo(RpcController* ctrl,const FooRequest* request,FooResponse* response,Closure* done){Status status = Check1(request);if (!status.IsOk()){response->set_errorcode(status.Code());// 第一处done->Run();return;}status = Check2(request);if (!status.IsOk()){response->set_errorcode(status.Code());// 第二处done->Run();return;}DoSomeRealWork(...);// 第三处done->Run();}
void Foo(RpcController* ctrl,const FooRequest* request,FooResponse* response,Closure* _done){// 仅一处,不遗漏erpc::ScopedCallback done(_done);Status status = Check1(request);if (!status.IsOk()){response->set_errorcode(status.Code());return;}status = Check2(request);if (!status.IsOk()){response->set_errorcode(status.Code());return;}DoSomeRealWork(...);}
void CompactTask::checkFileUtilizationRewrite(){// 此处采取朴素的排序算法,并未采取更高效的 TopK 算法std::sort(sealedFilesUsage.begin(), sealedFilesUsage.end(), GarbageCollectionCompare);int64_t sealedFileMaxSize = INT64_FLAG(lsm_CompactionSealedMaxSize);int32_t sealedFileMaxNum = INT32_FLAG(lsm_CompactionSealedMaxFileNum);int64_t targetFileSize = 0;int32_t sourceFileCnt = 0;// 前者简单清淅,并在几十个 File 中选择前几个文件的场景并不算太慢FOREACH(itr, sealedFilesUsage){LogicalFileId fileId = itr->fileId;const FileUsage* usage = baseMap->GetFileUsage(fileId);const File* file = fileSet->GetFile(fileId);targetFileSize += usage->blocks * mBlockSize;sourceFileCnt++;if (targetFileSize > sealedFileMaxSize || sourceFileCnt > sealedFileMaxNum){break;}mRewriteSealedFiles[fileId] = true;}......}
void UserRequestControl::WaitForPendingIOs(){erpc::ExponentialBackoff delayTimeBackOff;delayTimeBackOff.Reset(INT64_FLAG(lsm_UnloadWaitingBackoffBaseUs),INT64_FLAG(lsm_UnloadWaitingBackoffLimitUs),INT64_FLAG(lsm_UnloadWaitingBackoffScaleFactor));// 轮循等待在途的请求返回// 请思考如何用条件变量实现精确的同步while (!mWriteQueue.empty()|| !mReadQueue.empty()){uint64_t delayTime = delayTimeBackOff.Next();PGLOG_INFO(sLogger,(__FUNCTION__, "Waiting for inflight requests during segment unload")("Segment", mSegment->GetName())("Write Requests", mWriteQueue.size())("ReadRequests", mReadQueue.size())("DelayTimeInUs", delayTime));easy_coroutine_usleep(delayTime); // 退避等待}}
pthread_mutex_t mutex;pthread_cond_t nonEmptyCondition;std::list<Task*> queue;void ConsumerLoop(){pthread_mutex_lock(&mutex);while (true){while (queue.empty()){struct timespec ts;ts.tv_sec = 1;ts.tv_nsec = 0;// 使用timewaitpthread_cond_timedwait(&nonEmptyCondition, &mutex, timespec);}Task* firstTask = queue.front();queue.pop_front();consume(firstTask);}pthread_mutex_unlock(&mutex);}
// load.cppStatus LoadTask::Execute(){Status status;status = func();if (!status.IsOk()) { ... }// 串行执行下列步骤RUN_STEP(doPrepareDirs);...... // 十几步RUN_STEP(doTask);......}// files.cppStatus FileMap::SealFilesForLiveDevice(){Status status = OK;std::vector<SyncClosureR1<Status>*> sealDones;STLDeleteElementsGuard<std::vector<SyncClosureR1<Status>*> >donesDeleter(&sealDones);// 并行 seal 每个文件FOREACH(iter, mActiveFiles){File* file = iter->second;sealDones.push_back(new SyncClosureR1<Status>());Closure* work = stone::NewClosure(this,&FileMap::doSealFileForLiveDevice,file,static_cast<BindCallbackR1<Status>*>(sealDones.back()));InvokeCoroutineInCurrentThread(work);}// 收集结果FOREACH(done, sealDones){(*done)->Wait();if (!(*done)->GetResult0().IsOk()){status = (*done)->GetResult0();}}return status;}
1)关键的数据结构,如 数据分片 结构 ;
// stream.hclass Stream{public:Stream();~Stream();void Read(ReadArgs* args);......private:// 增加 magic 字段// 通常使用 uint32 或 uint64uint64_t mObjectMagic;......};// stream.cpp// 定义 magic 常量// 常量值选择 hexdump 时能识别的字符串,以便在 gdb 查看 coredump 时快速识别// 此处使用 “STREAM” 的 ASCII 串static uint64_t STREAM_OBJECT_MAGIC = 0x4e4d474553564544LL;Stream::Stream(): mObjectMagic(STREAM_OBJECT_MAGIC) // 在构造函数中赋值{......}Stream::~Stream(){// 在析构函数中检查并破坏 magic 字段,预防 double-free 错误easy_assert(mObjectMagic == STREAM_OBJECT_MAGIC);mObjectMagic = FREED_OBJECT_MAGIC;......}void DeviceSegment::Read(ReadArgs* args){// 在重要的函数中检查 magic 字段,预防 use-after-free 错误easy_assert(mObjectMagic == DEVICE_SEGMENT_OBJECT_MAGIC);......}
class StreamWriter{public:......private:struct StreamGroup{WriteAttemptList failureQueue;WriteAttemptList inflightQueue;WriteAttemptList pendingQueue;uint64_t commitSeq;uint64_t lastSeq;};uint32_t mStreamGroupCount;StreamGroup mStreamGroups[STREAM_GROUP_COUNT];......};void StreamWriter::sanityCheck(){for (uint32_t i = 0; i < mStreamGroupCount; i++){// Check that sequence in "failureQueue", "inflightQueue" and "pendingQueue" are ordered.const StreamGroup* group = &mStreamGroups[i];uint64_t prevSeq = group->commitSeq;const WriteAttemptList* queues[] = {&group->failureQueue,&group->inflightQueue,&group->pendingQueue};for (size_t k = 0; k < easy_count_of(queues); k++){FOREACH(iter, *queues[k]){const WriteRequest* write = iter->write;PANGU_ASSERT(prevSeq <= write->seq); // SanityCheckprevSeq = write->seq + write->lbaRange.rangeSize;}}ASSERT(prevSeq == group->lastSeq); // SanityCheck}......}
Status LoadTask::doTailScanFiles(){......for (id = FIRST_REAL_FILE_ID; id < mFileSet->GetTotalFileCount(); id++){File* file = mDiskFileSet->GetFile(id);if (file->GetLogicalLength() < logicalLengthInIndex){const char* msg = “BUG!! Found a data on disk with shorter length ”“than in map. This is probably caused by length reduction of ”“that file.”; // 记录详细的日志,包括文件名、期望长度、实际长度等PGLOG_FATAL(sLogger, (__FUNCTION__, msg)(“Stream”, mStream->GetName())(“File”, file->GetFileName())(“FileId”, file->GetFileId())(“FileLengthOnDisk”, file->GetFileLength())(“FileLengthInIndex”, physicalLengthInIndex)(“LogicalLengthOnDisk”, file->GetLogicalLength())(“LogicalLengthInIndex”, logicalLengthInIndex)(“MissingSize”, physicalLengthInIndex - file->GetFileLength()));SERVICE_ADD_COUNTER(“LSM:CriticalIssueCount”, 1); // 触发电话告警return LSM_FILE_CORRUPTED;}}}
linux/include/linux/jiffies.h/*•* Have the 32 bit jiffies value wrap 5 minutes after boot* so jiffies wrap bugs show up earlier.*//** These inlines deal with timer wrapping correctlyYou are•* strongly encouraged to use them* 1. Because people otherwise forget* 2. Because if the timer wrap changes in future you won't have to* alter your driver code.** time_after(a,b) returns true if the time a is after time b.*/(typecheck(unsigned long, a) && \typecheck(unsigned long, b) && \((long)((b) - (a)) < 0))
// easy/src/io/easy_timer.h// ----------------------------------------------------------------------------------// following interface, use easy_timer_sched from th(io thread or worker thread),// ** DON NOT support async call **//int easy_timer_start_on_th(easy_baseth_t *th, easy_timer_t *timer);int easy_timer_stop_on_th(easy_baseth_t *th, easy_timer_t *timer);
1.2 测试

TEST_F(..., SharedDisk_StopOneBs)(...){BenchMarkStart(mOption);// for循环反复注入mCluster->StopServer(0);mCluster->StartServer(0);// 修复前无第12行无代码,无下限检查,全部失败时Case PASS// 共享盘开盘后线程死锁必IO Hang,有测试无断言遗漏Bug导致P1故障EXPECT_GT(mIoBench->GetLastPrintIops(), 0);EXPECT_GT(mIoBench->GetMaxLatency(), 0);// 断言检查,边界上限EXPECT_GT(20 * 1000000, mIoBench->GetMaxLatency());// Do something below}Status PRConfig::Register )(...){assertIoThread();// 修复前缺少=,导致Sever Crashif (unlikely(mRegistrants.size() >= MAX_REGISTRANT_NUM)){LOG_ERROR(...);return SC_RESERVATION_CONFLICT;}// Do something below}
void WalStreamWriterPool::tryCreateWalWriter(){AssertCoroutine();ASSERT_DEBUG(mIsCreating);Status status = OK;while (...){WalStreamWriter *writer = mWalManager->CreateWalWriter();status = writer->Open();// 修复前无第14行代码部分,未处理Commit,失败导致丢掉WAL文件,进而丢数据if (status.IsOk()){status = mWalManager->Commit();}// Do something below}void RPCController::StartCancel(){if (_session) {if (_pendingRpc != NULL) {// 修复前无第29行代码,线程Hang进而IOHang// 未测试覆盖call StartCancel before handshake_session->need_cancel = true;} else {easy_session_cancel(_session);}} else {easy_error_log(...);}}
Status CompressOffsetTable::Seal(){// Do something beforestatus = mTableFile->Seal();if (!status.IsOk()){PGLOG_ERROR(...);return status;}mIsSealed = true;// 修复前无第14行代码,文件写入已完成,清空缓存,释放内存mEasyPool.reset();// Do something below}
void ActiveManager::SubmitIO({// 【版本兼容性】 SDK 和 Server线程不对齐,旧版本SDK不支持切线程if (UNLIKELY(GetCurrentThread() != serverThread))PGLOG_WARNING(... "Server thread mismatch");response->ErrorCode = SERVER_BUSY;done->Run();}void ChunkListAccessor::SetChunkInfoAndLocations(){uint8_t flags = mFileNodePtr->fileFlags;bool isLogFile = IsFlatLogFile(flags);ASSERT(//【协议兼容性】Master 和 SDK异常场景定长误判(isLogFile && vecChunkInfoNode[0].version <= masterChunkInfo.version) ||!isLogFile);// Do something below}// 【API兼容性】 Server 和 Master的错误码不一致,数据分片反复加载/卸载// Master侧,device_load.cpp// if(status.Code() == LSM_SEGMENT_EXIST_OTHER_VERSION))// Server侧,device_load.cpp// return LSM_NOT_OWN_SEGMENT;
-
测试不聚焦,无脑复制粘贴,等价类测试爆炸 -
异步等待,基于时间假设,sleep 并发,未能在预期的窗口期交互 -
有顺序依赖的测试,共享某个状态 -
资源溢出,数据库链接满、内存 OOM 析构随机 core -
析构未严格保序或者未构造 -
多线程共享资源的错误用法导致概率 crash -
有未处理完的任务就退出
TEST_F(FastPathSmokeTestFixture, Resize){// ... Do somethingResizeVolume(uri, DEVICE_SIZE * 2);Status status = OK;do {// 状态依赖,未检查resize 是否成功,导致错误的认为是越界io处理status = Write(handle, wbuf.get(), 0, 4096);if (status.Code() == OK){break;}easy_coroutine_usleep(100*1000);} while(1);// ... Do something}// volume_iov_split_test.cppTEST(VolumeIovSplitTest, Iovsplit_Random){// ... Do somethingsize_t totalLength = 0;// 修改前无+1,0是非法随机值,造成Case低概率失败totalLength = rand() % (10*1024*1024) + 1// ... Do something}
二、本地工具
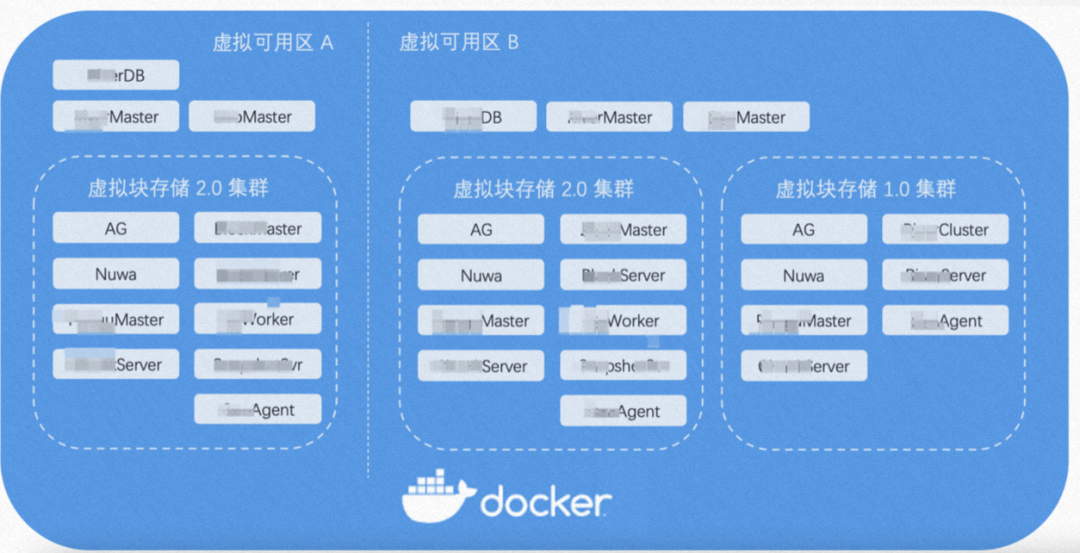
2.1 Docker单机集群
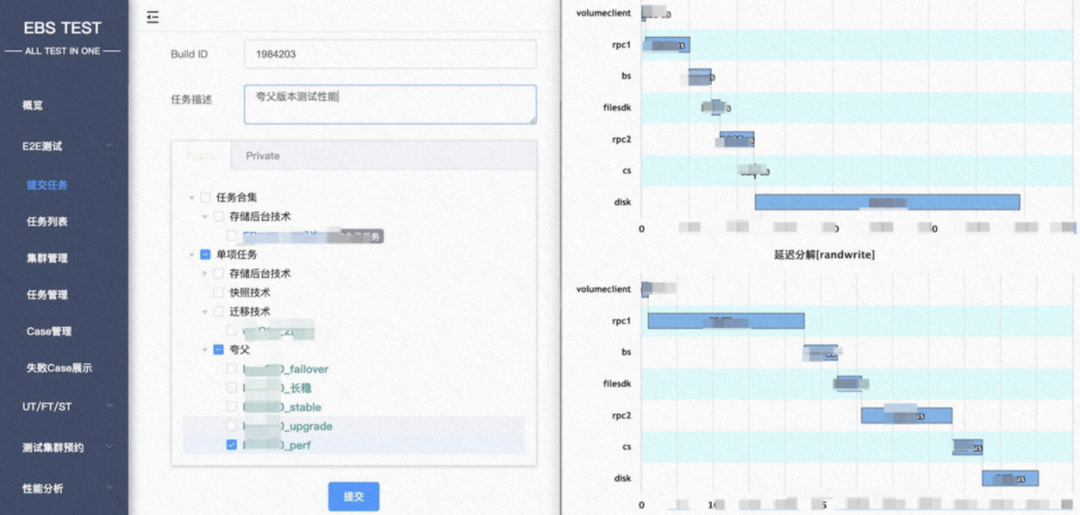
2.2 本地出包自助E2E
三、单元测试
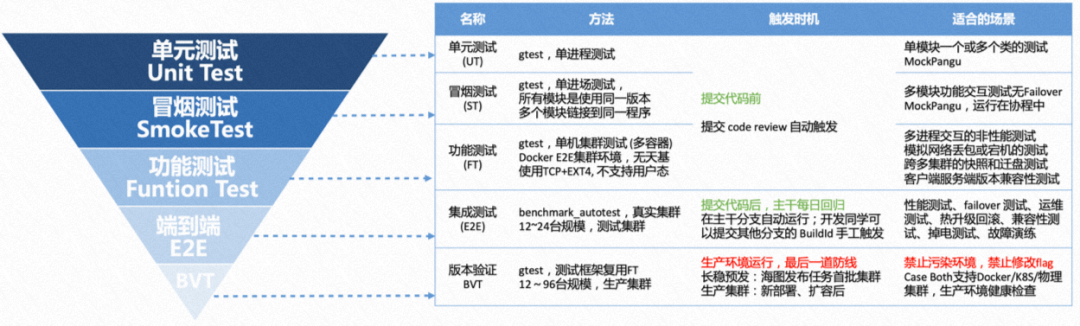
3.1 编写测试样例
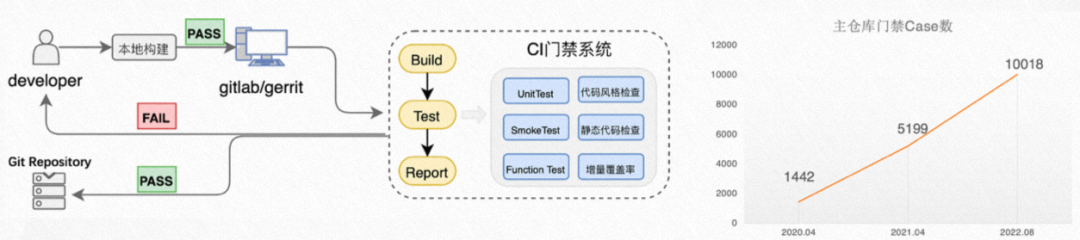
3.2 代码门禁说明
四、Code Review
-
提高团队代码标准,所有人共享同一套标准,阻止破窗效应 -
推动团队合作 reviewer 和 submitter 可能有不同的视角,主观的观点经常发生碰撞,促进相互学习 -
激励提交者,因为知道代码需要别人 review,所以提交者会倾向提升自己的代码质量。大部分程序员会因为同事对其代码显示出的专业性而感到自豪。 -
分享知识 submitter 可能使用了一种新技术或者算法,使 reviewer 受益。reviewer 也可能掌握某些知识,帮助改进这次提交。
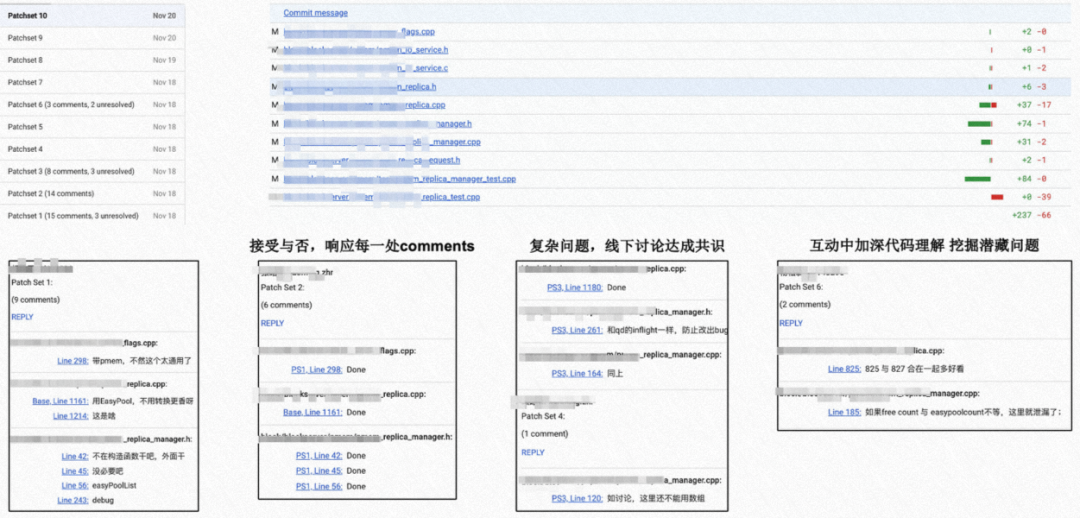
4.1 For Submitter
-
端正心态,reviewer 是帮你发现问题的人,而不是阻塞你提交的人 -
认真对待 description,降低Reviewer的理解成本 -
一次提交只解决一个问题,降低review的复杂度 -
如果需要做重大修改,写找 reviewer 对齐大致的修改范围,再开始写代码,避免越行越远

4.1 For Reviewer
-
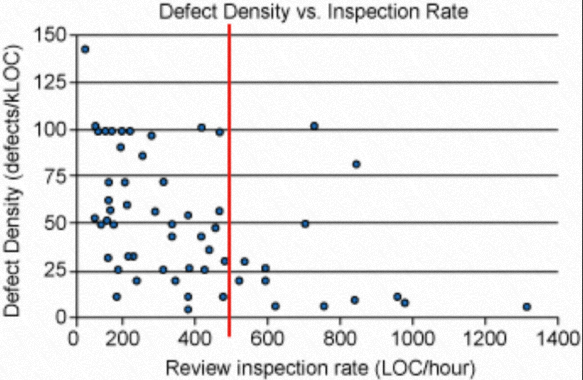
reviewer 应该尽量合理的安排自己的时间,不让自己成为 blocker,推荐每天在开始自己的工作前先 review 别人提交的代码。 -
给建议,更要给原因,帮助提交者进步 -
如果看到写得好的代码,不要吝啬赞赏的语句,提交者真的会很受鼓舞 -
对于看不明白的地方一定要提出问题,而不是轻易放过 -
不要花过多力气去理解难以理解的代码,如果一眼看不明白,第二眼还看不明白,说明这块代码需要改,很大可能过一段时间提交者也会看不明白 -
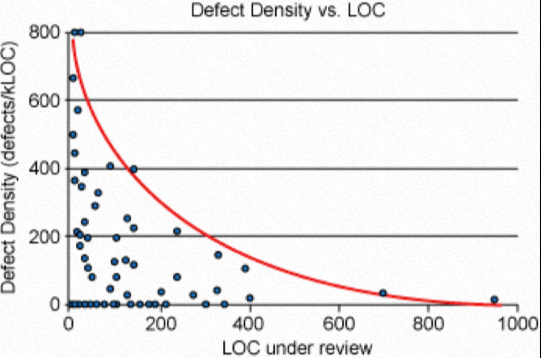
如果 patch 太大,应建议提交者分拆 -
慎重审查 .h 以及协议的修改 -
没有测试覆盖的代码没必要去看
五、分支管理
5.1 主干开发
列宁:帝国主义是资本主义的最高阶段
南门:主干开发(trunk based development)是持续集成(continuous integration)的最高阶段
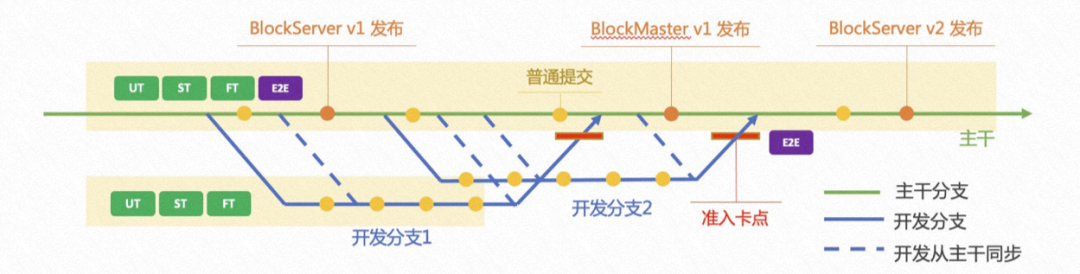
5.2 主干/分支发布
六、测试 & 环境
6.1 测试脚手架

6.2 环境标准化
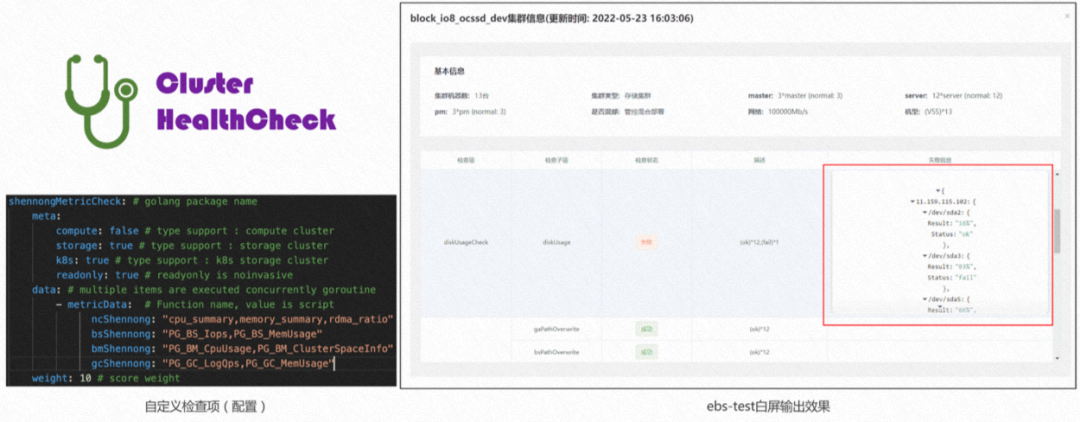
七、缺陷管理
7.1 git-poison投毒

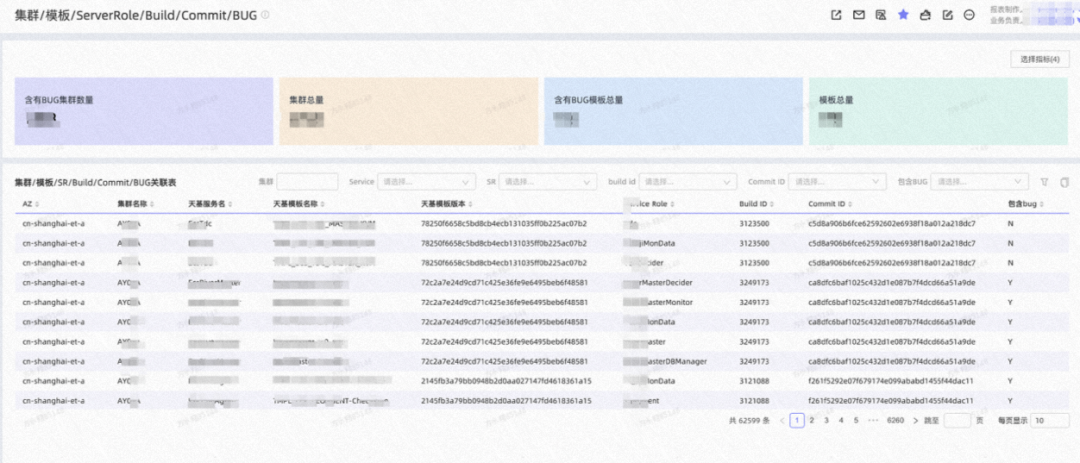
7.2 poison发布阻塞
八、持续交付
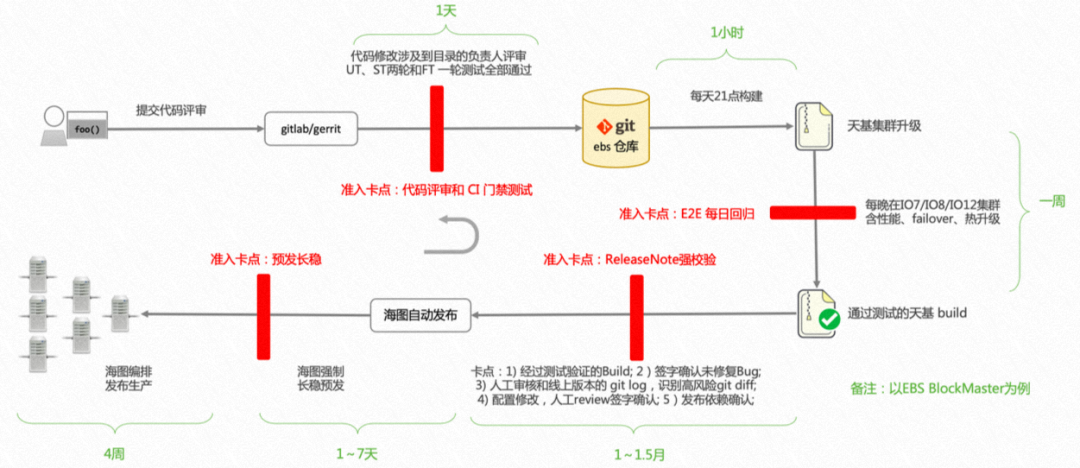
8.1 从开发到上线
8.2 分模块发布
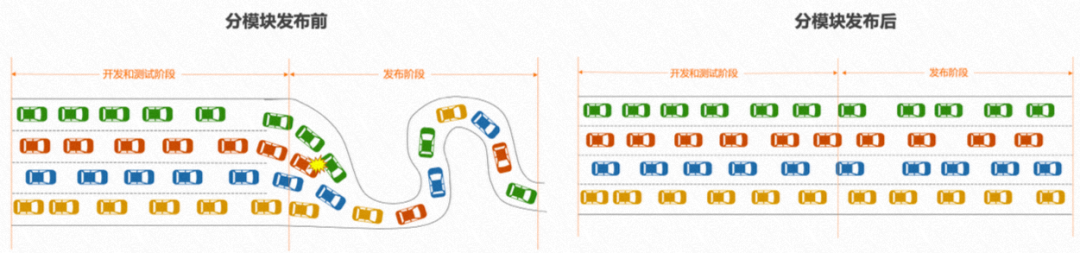

九、文化实践
9.1 效率工具和方法
-
开发机:窗口操作使用Screen、tmux 保持链接不中断、 SSH远端包括iTerm2、Bash、Zsh、Fish、 编辑器包括VSCode、Vim 、调查问题Debug使用gdb、pdb、内存泄漏: tcmalloc 、代码扫描静态cppcheck和动态代码扫描asan; -
Li nux:Cpu/Mem资源查看使用tsar --mem/cpu/io/net -n 1 -i 1、top等、网络使用lsof、netstat、 磁盘使用iostat、block_dump、inotifywait、df/du、内核日志包括/var/log/messages、sudo dmesg、性能工具strace、perf,IO压测FIO; 文档类:语雀的在线UML图/流程图/里程碑方便多人共同编辑等、Teambition的项目管理甘特图、 Aone的需求管理和缺陷管理、 离线工具诸如Xmind思维导图/draw.io 流程图/OneNote。
-
SMART原则,我的第一任主管飞山推荐,适用场景:OKR、KPI、绩效自评
-
S:Specific,具体的 -
M:Measurable,可以衡量的 -
A:Attainable,可以达到的 -
R:Relevant,具有一定的相关性 T:Time-bound,有明确的截止期限
-
论文学习方法,推荐先阅读大数据经典系列(例如Google 新/老三驾马车),对于存储领域同学,推荐Fast论文
-
Motivation: 解决了一个什么样的问题?为什么要做这个问题? Trade-off: 优势和劣势是什么?带来了哪些挑战?
-
适用场景: 没有任何技术是普适的,业务场景,技术场景 系统实现: 组成部分和关键实现,核心思想和核心组件,灵魂在哪里?
-
底层原理: 其底层的关键基础技术,基于这个基础还有哪些工作? Related Works: 这个问题上还有什么其他的工作?相关系统对比?不同的实现、不同的侧重、不同的思路?
-
TDD,Test-diven Development 测试驱动开发,团队石超推荐,“自从看了TDD这本书,我就爱上了写UT”,当时听完这句话驱动了我的好奇心,TDD到底一个什么神奇的方法?后来发现在《软件测试》《Google :Building Secure & Reliable Systems》《重构》 《重构与模式》《敏捷软件开发》《程序员的职业素养》……国外泰斗级程序员大叔的书里,全部都推荐了TDD。TDD不是万能药,主要思维模式是,先想清楚系统的行为表现,再下手编码,测试想清楚了,开发的API/系统表现就清晰了,API/函数/方法语义就明确了。
9.2 个人成长和踩坑
-
抽象和分而治之
-
抽象,明确模块之间的依赖关系,确定API接口 -
分而治之,对子系统设计进行合理的注释,帮助代码阅读者对软件结构有更直观的了解 代码提交尽量做到原子,即不可分割的特性、修复或者优化,测试代码同生产代码同一个patch提交
-
DRY(Don’t Repeat Yourself)
-
寻找重复的逻辑和代码,对重复内容进行抽象和封装 -
寻找流程的重复,使用脚本或者工具自动化,通过自动化提高交付质量和效率,降低交付成本 -
沉淀踩坑经验到自动化工具和平台中,独乐乐不如众乐乐,避免不同人踩相同的坑,降低无效时间开销
-
快速迭代
-
Done is better than prefect,不要过度设计 -
尽快让代码运行和快速验证,不断迭代来完善 -
为了能够快速验证,本地测试成本低,缩短反馈弧 实现一个可以运行起来的脚手架,再持续添加内容
-
忌“太心急”,慢即是快
-
需求澄清:类似TCP三次握手,用自己理解的方式再给对方讲一遍,确认双方理解一致,对焦,避免重复返工 -
自我提问:为什么做这件事?业务价值是什么?关键技术是什么?已有的系统和它对比有什么不同?兄弟团队是否做过类似的工作?是否有经验可供参考?业务/技术的适用场景是什么?预计耗时和进度风险? 新人往往脚踏实地,忘记了仰望星空,只顾着埋头苦干,不思考背后的业务价值,这一锄头,那一铁锹,遍地都是坑,就是不开花,费时费力,成就感低。
-
忌低效沟通,用数据说话
-
精确地描述问题,上下文和范围,提供有效信息 -
文档是提高沟通效率的最佳方式之一,Google有文档文化,推荐阅读 《Design Docs at Google》 [5] -
Bad Case:「测试CX6网卡时,IOPS大幅下降」 Good Case:「在100g网络标卡CX6验证性能时,8 jobs 32 depth iosize 4K场景下,极限IOPS从120万下降至110万,与FIC卡相比性能存在8%差异」
-
忌“蠢问题”,学会提问
-
鼓励新人多提问,但提问的问题一定要有质量 -
关于如何提出一个好问题推荐阅读 《提问的智慧》 [6] -
Bad Case:「我在编译耗时很长,我怀疑是资源不够,这种情况怎么办?」 -
Good Case:「我的开发机编译耗时2小时,不符合预期,OS是centOS 7U、128GB内存、64Core,编译并发度是20核,未限制内存,编译过程使用Top查看确实20核并发,Cpu和Mem没有达到瓶颈,iostat看磁盘使用率每秒60%」
十、延伸阅读
-
《编写可读代码的艺术》 ,推荐理由:漂亮的代码长什么样、命名变量避免歧义、写出言简意赅的注释、抽取小函数让测试用例更易读等; -
《Software Engineer at Google》 ,推荐理由:介绍Google 软件工程文化、流程、工具, github 有中文电子版 -
《人月神话》 ,推荐理由:被誉为软件工程圣经,与《人件》共同被称为双子星,两者是软件行业的神书,而其他书只能被称为经典,自1986年出版至今,每年销售量上万本,值得每隔1~2年反复阅读,初看不知剧中意,再看已是剧中人 -
《数据密集型应用系统设计》 ,推荐理由:软件开发者的必读书籍,衔接理论与实践,包括数据密集型应用系统所需的若干基本原则、深入探索分布式系统内部机制和运用这些技术、解析一致性/扩展性/容错和复杂度之间的权衡利弊、介绍分布式系统研究的最新进展(数据库)、揭示主流在线服务的基本架构等。
日拱一卒,功不唐捐,共勉。
参考链接:
[1] 接近不可接受的负载边界
https://www.usenix.org/conference/srecon18americas/presentation/schwartz
[2] Software Engineering at Google
https://qiangmzsx.github.io/Software-Engineering-at-Google/#/zh-cn/Chapter-12_Unit_Testing/Chapter-12_Unit_Testing
[3] 测试左移在大型分布式系统中的工程实践
https://mp.weixin.qq.com/s/DSsscC_5ldOTCTbW6u-ubw
[4] Best Practices for Code Review
https://smartbear.com/learn/code-review/best-practices-for-peer-code-review/
[5] Design Docs at Google
https://www.industrialempathy.com/posts/design-docs-at-google/
[6] 提问的智慧
https://github.com/ryanhanwu/How-To-Ask-Questions-The-Smart-Way/blob/main/README-zh_CN.md
《阿里云存储白皮书》
随着阿里云的崛起,集团内部的各种技术开始以阿里云作为唯一出口,阿里云成为阿里巴巴经济体的技术底座,阿里云的“盘古”存储也成为阿里巴巴经济体的存储底盘。用“稳定安全高性能,普惠智能新存储”来形容这本白皮书的内涵最为恰当不过了。“不畏浮云遮望眼,自缘身在最高层。”基于盘古的阿里云存储必将继续引领全球产业进入未来的“新存储”大时代。
点击阅读原文查看详情。

