手把手教你用Python构建你的第一个多标签图像分类模型(附案例)
翻译:吴金笛 校对:郑滋
本文约4600字,建议阅读12分钟。
本文明确了多标签图像分类的概念,并讲解了如何构建多标签图像分类模型。
介绍
你正在处理图像数据吗?我们可以使用计算机视觉算法来做很多事情:
对象检测
图像分割
图像翻译
对象跟踪(实时),还有更多……
这让我思考——如果一个图像中有多个对象类别,我们该怎么办?制作一个图像分类模型是一个很好的开始,但我想扩展我的视野以承担一个更具挑战性的任务—构建一个多标签图像分类模型!
制作一个图像分类模型
https://www.analyticsvidhya.com/blog/2019/01/build-image-classification-model-10-minutes/?utm_source=blog&utm_medium=multi-label-image-classification
我不想使用简单玩具数据集来构建我的模型—这太普通了。然后,它打动了我—包含各种各样的人的电影/电视剧海报。我可以仅通过看海报就能来构建我自己的多标签图像分类模型来预测不同的流派吗?

答案很简单——是的!在本文中,我解释了多标签图像分类背后的思想。我们将使用电影海报构建我们自己的模型。你将会对我们的模型产生的令人印象深刻的结果感到惊讶。如果你是《复仇者联盟》或《权力的游戏》的粉丝,那么在实现部分会有一个很棒的惊喜(无剧透的)给你。
激动吗?很好,我们开始吧!
目录
1. 什么是多标签图像分类?
2. 多标签图像分类与多类图像分类有何不同?
3. 了解多标签图像分类模型体系结构;
4. 构建多标签图像分类模型的步骤;
5. 案例研究:用Python解决多标签图像分类问题;
6.接下来的步骤和你的实验;
7.尾记。
1. 什么是多标签图像分类?
让我们通过一个直观的例子来理解多标签图像分类的概念。 看看下面的图片:

图1中的对象是一辆汽车。这是显而易见的。然而,在图2中没有汽车,只有一组建筑物。你能看出我们要怎么做吗?我们将图像分为两类,即,有车还是没车。
当我们只有两类图像可以分类时,这就称为二值图像分类问题。
让我们再看一个图片:

在这个图片中,你识别出了多少个物体?有太多了——房子、带喷泉的池塘、树木、岩石等等。所以,当我们可以将一个图像分类为多个类(如上图所示)时,就称为多标签图像分类问题。
现在,这里有一个问题——我们大多数人对多标签和多类图像分类感到困惑。当我第一次遇到这些术语时,我也被迷惑了。现在我对这两个主题有了更好的理解,让我来为你们澄清一下区别。
2. 多标签图像分类与多类图像分类有何不同?
假设给我们一些动物的图片,让我们把它们分成相应的类别。为了便于理解,我们假设一个给定的图像可以分为4类(猫、狗、兔子和鹦鹉)。现在,可能有两种情况:
每个图像只包含一个对象(上述4个类别中的任何一个),因此,它只能被归入4个类别中的一个。
图像可能包含多个对象(来自上述4个类别),因此该图像将属于多个类别。
让我们通过例子来了解每种情况,从第一个场景开始:

这里,我们的每个图像都只包含一个对象。敏锐的你会注意到在这个集合中有4种不同类型的对象(动物)。
这里的每张图片只能被分类为猫、狗、鹦鹉或兔子。没有任何一个图像属于多个类别的情况。
当图像可分类的类别超过两种时
一个图像不属于一个以上的类别
如果满足上述两个条件,则称为多类图像分类问题。
现在,让我们思考第二种情况 —— 看看下面的图像:

第一张图片(左上角)包含一只狗和一只猫
第二幅图(右上角)包括一只狗、一只猫和一只鹦鹉
第三幅图(左下角)包含一只兔子和一只鹦鹉,以及
最后一张图片(右下角)包含一只狗和一只鹦鹉
这些都是给定的图像的标签。这里的每个图像都属于一个以上的类,因此它是一个多标签图像分类问题。
这两种情况应该有助于你理解多类和多标签图像分类之间的区别。如果你需要进一步的说明,请在本文下面的评论部分与我联系。
在进入下一节之前,我建议你通读这篇文章——在10分钟内构建你的第一个图像分类模型!它将帮助你了解如何解决一个多类图像分类问题。
在10分钟内构建你的第一个图像分类模型:
https://www.analyticsvidhya.com/blog/2019/01/build-image-classification-model-10-minutes/?utm_source=blog&utm_medium=multi-label-image-classification
3. 构建多标签图像分类模型的步骤
现在我们已经对多标签图像分类有了一个直观的认识,让我们深入讨论解决这个问题应该遵循的步骤。
第一步是以结构化格式获取数据。这既适用于图像二分类,也适用于多类图像分类。
你应该有一个文件夹,其中包含您想要训练模型的所有图像。现在,为了训练这个模型,我们还需要图像的真实标签。因此,你还应该有一个.csv文件,其中包含所有训练图像的名称及其对应的真实标签。
我们将在本文后面学习如何创建这个.csv文件。现在,只要记住数据应该是一种特定的格式。数据准备好后,我们可以将进一步的步骤划分如下:
加载和预处理数据
首先,加载所有图像,然后根据项目的需求对它们进行预处理。为了检查我们的模型将如何对不可见的数据(测试数据)执行,我们创建了一个验证集。我们在训练集上训练我们的模型并使用验证集对其进行验证(标准的机器学习方法)。
定义模型的结构
下一步是定义模型的结构。这包括决定隐藏层的数量、每层神经元的数量、激活函数等等。
训练模型
是时候在训练集上训练我们的模型了!我们输入训练图像及其对应的真标签对模型进行训练。我们还在这里传入验证图像,以帮助我们验证模型在不可见数据上的性能。
作出预测
最后,我们使用训练过的模型对新图像进行预测。
4. 了解多标签图像分类模型结构
现在,多标签图像分类任务的预处理步骤将类似于多类问题的预处理步骤。关键的区别在于我们定义模型结构的步骤。
对于多类图像分类模型,我们在输出层使用softmax激活函数。对于每个图像,我们想要最大化单个类的概率。当一个类的概率增大时,另一个类的概率就减小。所以,我们可以说每个类的概率都依赖于其他类。
但是在多标签图像分类的情况下,单个图像可以有多个标签。我们希望概率彼此独立。使用softmax激活函数并不合适。相反,我们可以使用sigmoid激活函数。这将独立地预测每个类的概率。它将在内部创建n个模型(这里的n是总类数),每个类一个模型,并预测每个类的概率。
利用sigmoid激活函数将多标签问题转化为n-二分类问题。因此对于每幅图像,我们将得到概率来确定图像是否属于第一类,以此类推。由于我们已经将其转换为一个n-二分类问题,我们将使用binary_cross-sentropy损失。我们的目标是尽量减少这种损失,以提高模型的性能。
这是我们在定义用于解决多标签图像分类问题的模型结构时必须做的主要更改。训练部分将类似于一个多类问题。我们将传入训练图像及其对应的真实标签,以及验证集来验证模型的性能。
最后,我们将获取一张新的图像,并使用训练过的模型来预测该图像的标签。还跟得上吗?
5. 案例研究:用Python解决多标签图像分类问题
祝贺你来到这一步!你的奖励——用Python解决一个可怕的多标签图像分类问题。是时候启动你最喜欢的Python IDE了!
让我们明确问题陈述。我们的目标是通过电影的海报图像来预测电影的类型。你能猜到为什么这是一个多标签图像分类问题吗?在你往下看之前想一下。
一部电影可以属于多种类型,对吧?它不仅仅属于一个类别,如动作片或喜剧片。电影可以是两种或多种类型的结合。因此,它是多标签图像分类。
我们将使用的数据集包含多个多类型电影的海报图像。我对数据集做了一些更改,并将其转换为结构化格式,即一个包含图像的文件夹和一个存储真正标签的.csv文件。你可以从这里下载结构化数据集。下面是一些来自我们数据集的海报:
这里
https://drive.google.com/file/d/1dNa_lBUh4CNoBnKdf9ddoruWJgABY1br/view

如果你愿意,可以在这里下载原始数据集和基准真值。
这里
https://www.cs.ccu.edu.tw/~wtchu/projects/MoviePoster/index.html
让我们开始编程!
首先,导入所有需要的Python库:
1. import keras
2. from keras.models import Sequential
3. from keras.layers import Dense, Dropout, Flatten
4. from keras.layers import Conv2D, MaxPooling2D
5. from keras.utils import to_categorical
6. from keras.preprocessing import image
7. import numpy as np
8. import pandas as pd
9. import matplotlib.pyplot as plt
10. from sklearn.model_selection import train_test_split
11. from tqdm import tqdm
12. %matplotlib inline
现在,读取.csv文件并查看前五行的内容:
1. train = pd.read_csv('multi_label_train.csv') # reading the csv file
2. train.head() # printing first five rows of the file
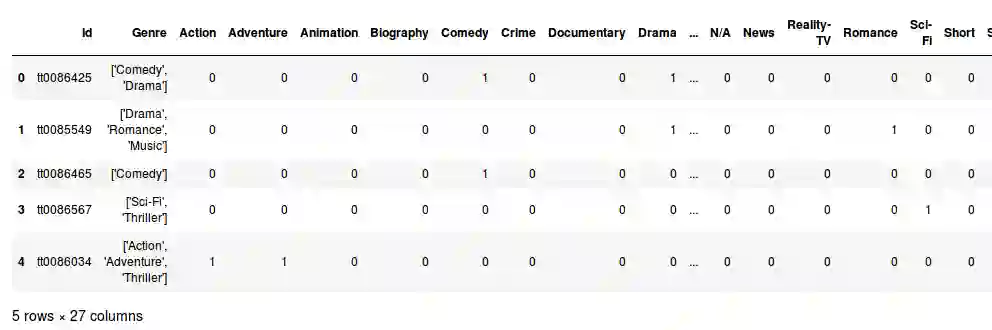
这个文件中有27列。 让我们输出这些列的名字看看:
1. train.columns

Genre列包含每个图像的列表,其中明确了每个图像对应的电影的类型。因此,从.csv文件的头部开始,第一个图像的类型是喜剧和戏剧。
剩下的25列是独热码列。因此,如果一部电影属于动作类型,它的值将为1,否则为0。每个图像可以属于25种不同的类型。
我们将构建一个返回给定电影海报类型的模型。但在此之前,你还记得构建图像分类模型的第一步吗?
没错——就是正确的加载和预处理数据。所以,让我们看看所有的训练图片:
1. train_image = []
2. for i in tqdm(range(train.shape[0])):
3. img = image.load_img('Multi_Label_dataset/Images/'+train['Id'][i]+'.jpg',target_size=(400,400,3))
4. img = image.img_to_array(img)
5. img = img/255
6. train_image.append(img)
7. X = np.array(train_image)
快速浏览一下数组的形状:
1. X.shape

这里共有7254个海报图像,所有图像都已转换为(400,300,3)的形状。 让我们绘制并可视化其中一个图像:
1. plt.imshow(X[2])

这是电影《交易场所》的海报。让我们输出这部电影的类型:
1. train['Genre'][2]

这部电影仅有一个类型——喜剧。我们的模型所需的下一步是所有图像的真实标签。你能猜出这7254个图像真实标签的形状是什么吗?
让我们来看看。 我们知道总共有25种可能的类型。对于每个图像,我们将有25个目标,即电影是否属于该类型。 因此,所有这25个目标的值都为0或1。
我们将从训练文件中删除Id和Genre列,并将剩余的列转换为将成为我们图像目标的数组:
1. y = np.array(train.drop(['Id', 'Genre'],axis=1))
2. y.shape
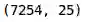
输出数组的形状是(7254,25),正如我们预想的那样。 现在,让我们创建一个验证集,它将帮助我们检查模型在不可见的数据上的性能。 我们将随机分离10%的图像作为我们的验证集:
1. X_train, X_test, y_train, y_test =
2. train_test_split(X, y, random_state=42, test_size=0.1)
下一步是定义模型结构。输出层将有25个神经元(等于类型的数量),我们将使用sigmoid作为激活函数。
我将使用某一结构(如下所示)来解决这个问题。 你也可以通过更改隐藏层数,激活函数和其他超参数来修改此架构。
1. model = Sequential()
2. model.add(Conv2D(filters=16, kernel_size=(5, 5), activation="relu", input_shape=(400,400,3)))
3. model.add(MaxPooling2D(pool_size=(2, 2)))
4. model.add(Dropout(0.25))
5. model.add(Conv2D(filters=32, kernel_size=(5, 5), activation='relu'))
6. model.add(MaxPooling2D(pool_size=(2, 2)))
7. model.add(Dropout(0.25))
8. model.add(Conv2D(filters=64, kernel_size=(5, 5), activation="relu"))
9. model.add(MaxPooling2D(pool_size=(2, 2)))
10. model.add(Dropout(0.25))
11. model.add(Conv2D(filters=64, kernel_size=(5, 5), activation='relu'))
12. model.add(MaxPooling2D(pool_size=(2, 2)))
13. model.add(Dropout(0.25))
14. model.add(Flatten())
15. model.add(Dense(128, activation='relu'))
16. model.add(Dropout(0.5))
17. model.add(Dense(64, activation='relu'))
18. model.add(Dropout(0.5))
19. model.add(Dense(25, activation='sigmoid'))
让我们显示我们的模型总结:
1. model.summary()
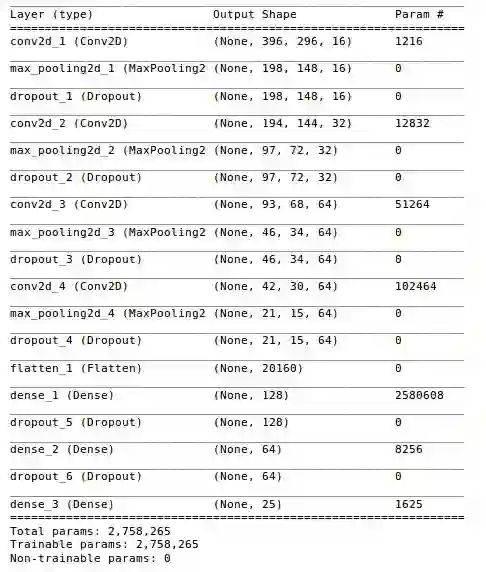
有相当多的参数要学习! 现在,编译模型。 我将使用binary_crossentropy作为损失函数,使用ADAM作为优化器(同样,你也可以使用其他优化器):
1. model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
最后,我们最有趣的部分——训练模型。我们将训练模型10个循环,并传入我们之前创建的验证数据,以验证模型的性能:
1. model.fit(X_train, y_train, epochs=10, validation_data=(X_test, y_test), batch_size=64)

我们可以看到训练损失已降至0.24,验证损失也降低了。 下一步是什么? 是时候做预测了!
所有《权力的游戏(GoT)》和《复仇者联盟(Avengers)》的粉丝——这是给你们的礼物。 让我获取GoT和Avengers的海报,并将它们提供给我们的模型。 在继续之前下载GOT和Avengers的海报。
GOT
https://drive.google.com/file/d/1cfIE-42H4_UM-JERoctseLUpKwmd40YE/view
Avengers
https://drive.google.com/file/d/1buNOcfo0Im2HmFH778dUwxven8Zzebtu/view
在进行预测之前,我们需要使用前面看到的相同步骤预处理这些图像。
1. img = image.load_img('GOT.jpg',target_size=(400,400,3))
2. img = image.img_to_array(img)
3. img = img/255
现在,我们将使用我们训练好的模型预测这些海报的类型。该模型将告诉我们每种类型的概率,我们将从中获得前3个预测结果。
1. classes = np.array(train.columns[2:])
2. proba = model.predict(img.reshape(1,400,400,3))
3. top_3 = np.argsort(proba[0])[:-4:-1]
4. for i in range(3):
5. print("{}".format(classes[top_3[i]])+" ({:.3})".format(proba[0][top_3[i]]))
6. plt.imshow(img)
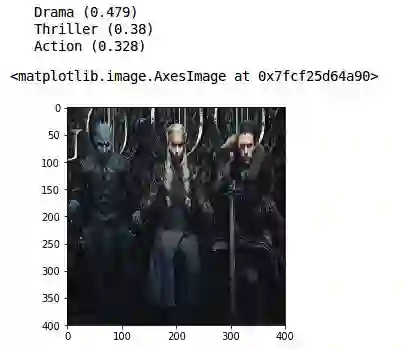
真棒!我们的模型为《权力的游戏》预测了戏剧,惊悚和动作类型。在我看来,这个分类很好。让我们在《复仇者联盟》海报上试试我们的模型。图像预处理:
1. img = image.load_img('avengers.jpeg',target_size=(400,400,3))
2. img = image.img_to_array(img)
3. img = img/255
然后做预测:
1. classes = np.array(train.columns[2:])
2. proba = model.predict(img.reshape(1,400,400,3))
3. top_3 = np.argsort(proba[0])[:-4:-1]
4. for i in range(3):
5. print("{}".format(classes[top_3[i]])+" ({:.3})".format(proba[0][top_3[i]]))
6. plt.imshow(img)

我们的模型给出的类型是戏剧、动作和惊悚。同样,这些都是非常准确的结果。这个模型能在好莱坞电影分类上表现的一样优秀吗?让我们来看看。我们将使用这张Golmal 3的海报。

你知道在这个阶段该做什么——加载和预处理的图像:
1. img = image.load_img('golmal.jpeg',target_size=(400,400,3))
2. img = image.img_to_array(img)
3. img = img/255
然后为这个海报预测电影类型:
1. classes = np.array(train.columns[2:])
2. proba = model.predict(img.reshape(1,400,400,3))
3. top_3 = np.argsort(proba[0])[:-4:-1]
4. for i in range(3):
5. print("{}".format(classes[top_3[i]])+" ({:.3})".format(proba[0][top_3[i]]))
6. plt.imshow(img)
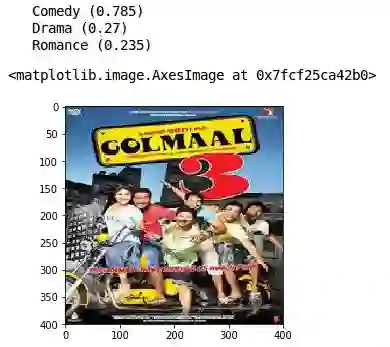
《Golmaal 3》是一部喜剧,我们的模型预测它为最受欢迎的类型。其他预测类型是剧情片和浪漫片——相对准确的评估。我们可以看到该模型能够仅通过海报预测电影类型。
6. 接下来的步骤和你自己的实验
这就是如何解决多标签图像分类问题。尽管我们只有大约7000张图片来训练模型,但我们的模型表现得非常好。
你可以尝试收集更多的训练海报。我的建议是使所有的流派类别有相对平等的分布的数据集。为什么?
如果某一类型在大多数训练图像中重复出现,那么我们的模型可能会与该类型过度匹配。对于每一张新图片,该模型都可能预测出相同的类型。为了克服这个问题,你应该尝试均衡的流派类别分布。
这些是你可以尝试改进模型性能的一些关键点。你还能想到别的吗?告诉我!
7. 尾记
除了流派类型预测外,多标签图像分类还有多种应用。例如,你可以使用此技术自动标记图像。假设你想预测图像中服装的类型和颜色。你可以建立一个多标签图像分类模型,这将帮助你预测同时两者!
希望本文能帮助你理解多标签图像分类的概念。如果你有任何反馈或建议,请在下面的评论部分与我们分享。实验快乐!
原文链接:
https://www.analyticsvidhya.com/blog/2019/04/build-first-multi-label-image-classification-model-python/
原文标题:
Build your First Multi-Label Image Classification Model in Python
译者简介:吴金笛,雪城大学计算机科学硕士一年级在读。迎难而上是我最舒服的状态,动心忍性,曾益我所不能。我的目标是做个早睡早起的Cool Girl。
转自:数据派THU 公众号;
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
END
合作请加QQ:365242293
数据分析(ID : ecshujufenxi )互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。





