多模态与认知相遇,探索更像孩子一样的学习方式 | CNCC专家谈
在即将于今年12月8-10日在贵阳举办的CNCC2022期间,122个涵盖计算+行业、人工智能、云计算、教育、安全等30个热门专业领域的技术论坛上,近700位专家将着力探讨计算技术与未来宏观发展趋势,其中不乏在各领域深具影响力的重磅学者专家并担纲论坛主席。
本专题力邀CNCC2022技术论坛主席亲自撰稿,分享独家观点,带你提前走进CNCC,领略其独特魅力。

本期特别嘉宾
文继荣 CCF常务理事,中国人民大学教授、信息学院院长&高瓴人工智能学院执行院长
宋睿华 中国人民大学高瓴人工智能学院长聘副教授
多模态与认知相遇,探索更像孩子一样的学习方式——文继荣、宋睿华
最近时常会被朋友圈里AI生成的作品惊艳到,比如,图1是用“从荒芜到生命”作为提示词,在midjourney.com上生成的多幅作品中的两幅。伴随着AI生成作品的破圈应用,以及关于多模态的综述、趋势和技术详解等前沿成果接连涌现,让人不禁感慨:藏不住了,多模态实火。

△图1. 用midjourney.com生成的两幅《从荒芜到生命》
那什么是多模态?
从早至上个世纪启发自读唇语的语音识别/情感识别,到应用于太空的多光谱/高光谱相机对地观测,再到手机人脸识别用到的红外和RGB相机,可以说多模态研究历史悠久、涵盖广泛。它的研究领域及应用和我们的生活息息相关。而我们就生活在这样一个多模态世界中。人脑在感知和理解世界时不仅仅局限于单一模态,通过引入多样化、更为全面的模态信息,我们期望获得更强的学习能力与更好的学习效果。一双眼睛提供了视觉信息,耳朵提供了声音信息,鼻子提供了嗅觉,舌头提供了味觉。当这几种感官聚焦在一起时,我们方才了解:“哦,面前这道菜‘色香味’俱全!”这种与生俱来的多感官认知能力让无数认知学家为之向往,也启发着人工智能领域的研究者设计并打造多模态信息处理的相关高效算法。
多模态为什么这么火?
认知科学领域上世纪90年代开始的具身革命,为多模态研究提供了认知基础。具身(Embodied,也译为“体验”)模拟假说认为思考以及使用语言的能力,并非只和头脑相关,而是我们的肉身与头脑合作的成果。这里的肉身就包括声音、视觉、味道、气味、触感和运动等模态。不断有巧妙设计的认知实验,以及利用精密的眼动仪器和fMRI的实验结果,提供证据支持这一假说。正如,本杰明·博根教授在他的著作《我们赖以生存的意义》中的举例(如图2),当看到“北极熊爱吃海豹肉,而且爱吃新鲜的”这个句子,一刹那,我们的脑袋里很可能会浮现出北极熊和海豹的样子;看到“它爱吃新鲜的”,我们可能会有一点要流口水的感觉;当我们看到文字描写北极熊是怎么捉海豹的,讲到了它“一跃而起,伸出爪子,露出獠牙”,则很可能有一种想张嘴伸出手的冲动。这些都与我们对文字所描述的景象进行了多模态的模拟相关。

△图2. 来自《我们赖以生存的意义》的例子
如果人工智能也可以对文字进行跨模态的模拟,比如检索或生成“北极熊几乎可以完美地将自己隐身于周遭的冰天雪地”对应的画面,尽管原文中没有提到过颜色相关的词,我们也可能从对应的画面中推理出北极熊是白色,而周遭的冰天雪地也是白色。这样一来,视觉模拟为人工智能补上了文字所省略的常识,它们也就有可能像我们一样理解这句话的含义。
多模态的大火也和Transformer为代表的通用骨干网络在文本、语音和视觉领域的诸多任务上取得广泛成功不无关系。统一的模型架构让多模态信息的融合变得简单而有效,训练起来也并不麻烦。当然,互联网上取之不尽的图片文本数据,以及近年来持续增长的短视频数据,都给基于自监督的多模态预训练模型提供了充足的数据。例如,在北京智源研究院的支持下,中国人民大学文继荣教授牵头的文澜项目,继去年发布6.5亿图文数据上训练得到的文澜2.0模型、展现出图片跨模态搜索歌词或者古诗的惊人能力之后,今年6月又发布了1千万视频文本数据上训练得到的文澜3.0模型,并基于此实现了多种有趣的多模态应用。例如,让机器狗对环境作出自然反应,以及让AI可以根据任意的视觉场景发起多模态对话(见视频)。
多模态都研究啥?
京东集团副总裁何晓冬曾将多模态的研究现状归纳为多模态表征学习、多模态信息融合和多模态智能应用【1】。多模态表征学习研究将多个模态数据所蕴含的语义信息投影到连续向量表征空间以进行信息融合和推理。随着OpenAI CLIP的成功,双塔模型逐渐取代单塔成为研究的主流,最新工作如BLIP则可以考虑多个任务联合学习多模态表征。多模态信息融合除了研究如何融合不同模态的信息,以完成复杂的多模态任务,也包括研究不同模态之间的元素的对应关系,比如视觉模态中的物体和姿态与语言模态中的实体和概念。字节跳动AI Lab李航团队深入研究跨模态特征关联方法,提出了多粒度视觉语言模型(X-VLM)、图片和文本统一生成模型(Davinci)等具有较强跨模态特征融合能力的模型。多模态智能应用就更加丰富多彩,包括视觉转文字、文字转视觉,视觉问答、多模态检索、视觉+语言导航、多模态人机对话与交互等。例如,由微软亚洲研究院、北京大学联合提出的可以同时覆盖语言、图像和视频的统一多模态模型女娲,可以为各种视觉合成任务生成新的图像和视频数据,或对其进行编辑。而对于文本生成视频任务,当输入不同的文字指引时,女娲模型亦可以在原视频的基础上生成不同内容的视频,从而与文字匹配,所生成的视频非常符合人类对客观世界的认知。

△输入一个潜水员潜水的视频,但用文字“潜水员游向水面”影响视频生成时,接下来人会上浮;当用“潜水员游向海底”影响时,则会生成潜水员向下的视频;当用“潜水员游向天空”这样的文字去影响时,潜水员不仅向上,背景还会变成蓝色的天空。
多模态和认知有哪些交叉研究?
随着多模态预训练大模型的发展,人们开始好奇大模型到底学习到了什么?2022年6月,Nature子刊发表了一篇中国人民大学高瓴人工智能学院卢志武教授、孙浩长聘副教授以及文继荣教授作为共同通讯作者的论文“Towards Artificial General Intelligence via a Multimodal Foundation Model”【2】。这一研究中,文澜BriVL模型从一张噪声图开始,进行图像编码之后与“时间”这一词进行文本编码后进行比较,差异通过反向传播对输入的噪声图进行修改,逐渐缩小图像与文本在编码上的距离,于是我们就能够看到大模型是如何理解时间这一概念的。如图3所示,里面隐约可以看到时针和钟表的轮廓。

△图3. 可视化文澜BriVL模型对“时间”和“科学”的理解
当人工智能科学家从人脑的机制中汲取灵感,训练双塔模型来对齐一个概念的文字和视觉时,脑科学家们也注意到这一进展。他们反过来,想利用这一技术把收集到的人脑活动信号可视化。中科院自动化所何晖光团队提出了一个基于多视图贝叶斯深度生成模型、可通过fMRI信号重建看到的图像(见图4)。更进一步,他们提出的学习框架,基于多视图对抗学习,将大脑活动模式的语义解码和图像重建任务统一,利用脑活动和视觉图像语义特征进行交互学习,弥补了不同模态之间的鸿沟。【3,4】
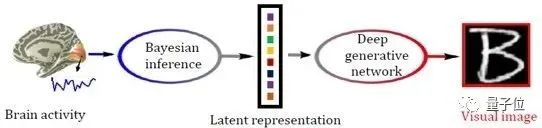
△图4. 通过贝叶斯推断重建感知到的视觉图像
在多模态机器人可能成为人类生活中重要伴侣的智能时代,心理学和认知科学家同时关心,如何让机器人理解并学习人类的行为,从而更好地融入人类社会。华东师范大学心理与认知科学学院蒯曙光教授团队,突破了长期以来仅在概念层面研究这一问题的困境,构建了基于虚拟情景的人类行为实验平台,通过定量化的实验和数学建模的方法,量化人类社会交互的行为,并将其算法化,应用到机器人的空间导航任务中,从而有效地提升了服务机器人的社会友好性。
多模态让人工智能更像人
最近,图灵奖得主Yann LeCun与合作者在Noema杂志上发表了一篇文章【5】,指出大型语言模型无法接近人类水平的智能,他们给出的原因是语言只支撑了人类全部知识的一小部分,且大部分人类知识和所有动物的知识都是非语言的。的确,正如具身模拟假说所描述的,人类用多模态的经历做模拟来理解语义。人类水平的智能不会只有语言的部分,多模态与语言模型的结合似乎是一种突破语言模型的合理选择,但以何种方式结合还有待研究。随着越来越有价值的多模态应用的出现,多模态与认知结合的威力或将在近几年凸显。
本年度CNCC大会拟组织“多模态学习与认知——AI可以像孩子一样学习吗?”技术论坛,从事多模态研究的人工智能领域与认知领域的一线科学家们将齐集一堂,给大家带来精彩的报告和观点碰撞、领域交叉的深度研讨,敬请关注。
论坛名称:多模态学习与认知——AI可以像孩子一样学习吗?
主席:文继荣 CCF常务理事,中国人民大学教授、信息学院院长&高瓴人工智能学院执行院长
共同主席:宋睿华 中国人民大学高瓴人工智能学院长聘副教授
顺序 |
主题 |
主讲嘉宾 |
单位与职务 |
1 |
多模态内容生成:技术进展及实践 |
何晓冬 |
京东集团副总裁 |
2 |
AI赋能视觉内容创作 |
段楠 |
微软亚洲研究院首席研究经理 |
3 |
基于视觉信息编解码的深度学习类脑机制研究 |
何晖光 |
中科院自动化所研究员 |
4 |
大规模多模态预训练的最新研究进展 |
卢志武 |
中国人民大学高瓴人工智能学院教授 |
5 |
基于人类行为的服务机器人导航算法设计 |
蒯曙光 |
华东师范大学心理与认知科学学院教授 |
6 |
深入理解跨模态特征关联与融合——多模态预训练的研究与应用 |
张新松 |
字节跳动AI Lab研究员 |
7 |
Panel环节 |
全部嘉宾和主席 |
参考文献:
【1】何晓冬,AI研习丨何晓冬:语言与视觉的跨模态智能qhttps://www.sohu.com/a/374822896_505819
【2】费楠益,卢志武*,高一钊,杨国兴,霍宇琦,温静远,卢浩宇,宋睿华,高欣,向滔,孙浩*,文继荣*,Towards Artificial General Intelligence via a Multimodal Foundation Model,Nature Communications, 2022 https://www.nature.com/articles/s41467-022-30761-2
【3】Nanyi Fei, Zhiwu Lu*, Yizhao Gao, Guoxing Yang, Yuqi Huo, Jingyuan Wen, Haoyu Lu, Ruihua Song, Xin Gao, Tao Xiang, Hao Sun* and Ji-Rong Wen*, Towards artificial general intelligence via a multimodal foundation model, Nature Communications (Nat Commun), vol. 13, article no. 3094, 2022
【4】Changde Du,Changying Du,Huiguang He, Multimodal Deep Generative Adversarial Models for Scalable Doubly Semi-supervised Learning , Information Fusion, 2021, 68, pp:118-130
【5】https://www.noemamag.com/ai-and-the-limits-of-language/

关于CNCC 2022

CNCC是级别高、规模大的高端学术会议,探讨计算及信息科学技术领域最新进展和宏观发展趋势,展示计算领域学术界、企业界最重要的学术、技术成果,搭建交流平台,促进科技成果转换,是学术界、产业界、教育界的年度盛会。今年邀请嘉宾包括ACM图灵奖获得者、田纳西大学教授Jack Dongarra,以及高文、管晓宏、钱德沛、徐宗本、张平等多位院士,还有七百余位国内外名校学者、名企领军人物、各领域极具影响力的业内专家,CNCC在计算领域的水准及影响力逐年递增。本届CNCC的主题是:算力、数据、生态。
CNCC2022将汇聚国内外顶级专业力量、专家资源,为逾万名参会者呈上一场精彩宏大的专业盛宴。大会期间还将举办“会员之夜”大型主题狂欢活动,让参会者畅快交流,燃爆全场。如此盛会,岂能缺席!等你来,马上行动,欢迎参会报名!
*本文系量子位获授权刊载,观点仅为作者所有。
— 完 —

量子位 QbitAI
վ'ᴗ' ի 追踪AI技术和产品新动态
一键三连「分享」「点赞」和「在看」
科技前沿进展日日相见 ~
点击“阅读原文”,立享早鸟票优惠参会报名!