过去5年,PolarDB云原生数据库是如何进行性能优化的?


背景
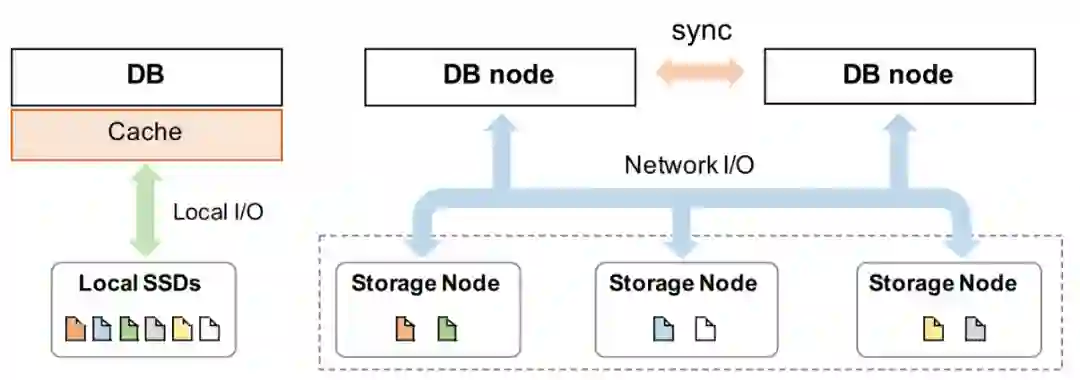
挑战与分析
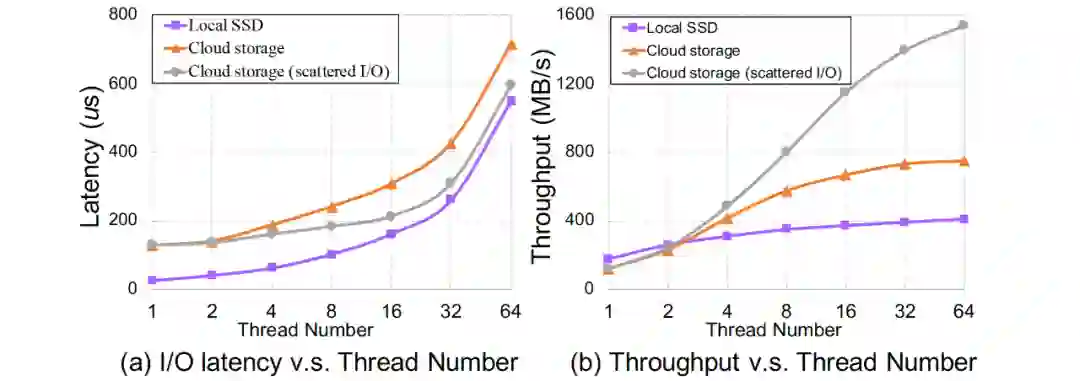
-
远程分布式存储集群的访问导致云存储服务的I/O延迟高; -
通常聚合I/O带宽未被充分利用; -
在具有本地存储的单机上运行良好但需要适应云存储而导致特性改变的传统设计,例如文件cache缓存; -
长链路导致各种数据库I/O操作之间的隔离度较低(例如,日志刷写与大量数据I/O的竞争); -
云用户允许且可能使用非常大的单表文件(例如数十TB)而不进行数据切分,这加剧了I/O问题的影响。

优化原则
-
Thread-level Parallelism :例如依据I/O特性实验,采用(更)多线程的日志、数据I/O线程及异步I/O模型,将数据充分打散到多个存储节点上。 -
Task-level Parallelism :例如对集中Log buffer按Page Partition分片,实现并行写入并基于分片进行并行Recovery。 -
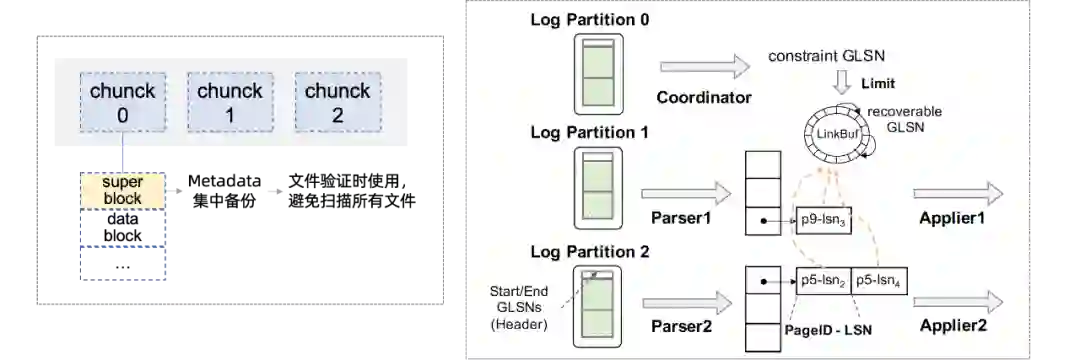
Reduce remote read and Prefetching :例如通过收集并聚合原分散meta至统一的superblock,将多个I/O合一实现fast validating;通过预读利用聚合读带宽、减少读任务延时;通过压缩、filter过滤减少读取数据量。与本地SSD上相比,这些技术在云存储上更能获得收益。 -
Fine-grained Locking and Lock-free Data Structures :云存储中较长的I/O延迟放大了同步开销,主要针对Update-in-place系统,实现无锁刷脏、无锁SMO等。 -
Scattering among Distributed Nodes :在云存储中,多个节点之间的分散访问可以利用更多的硬件资源,例如将单个大I/O并发分散至不同存储节点 ,充分利用聚合带宽。 -
Bypassing Caches :通过Bypassing Caches来避免分布式文件系统的cache coherence,并在DB层面优化I/O格式匹配存储最佳request格式。 -
Scheduling Prioritized I/O Tasks :由于访问链路更长(如路径中存在更多的排队情况),不填I/O请求间的隔离性相对本地存储更低,因此需要在DB层面对不同I/O进行打标、调度优先级,例:优先WAL、预读分级。
实践案例
实践案例:PolarDB
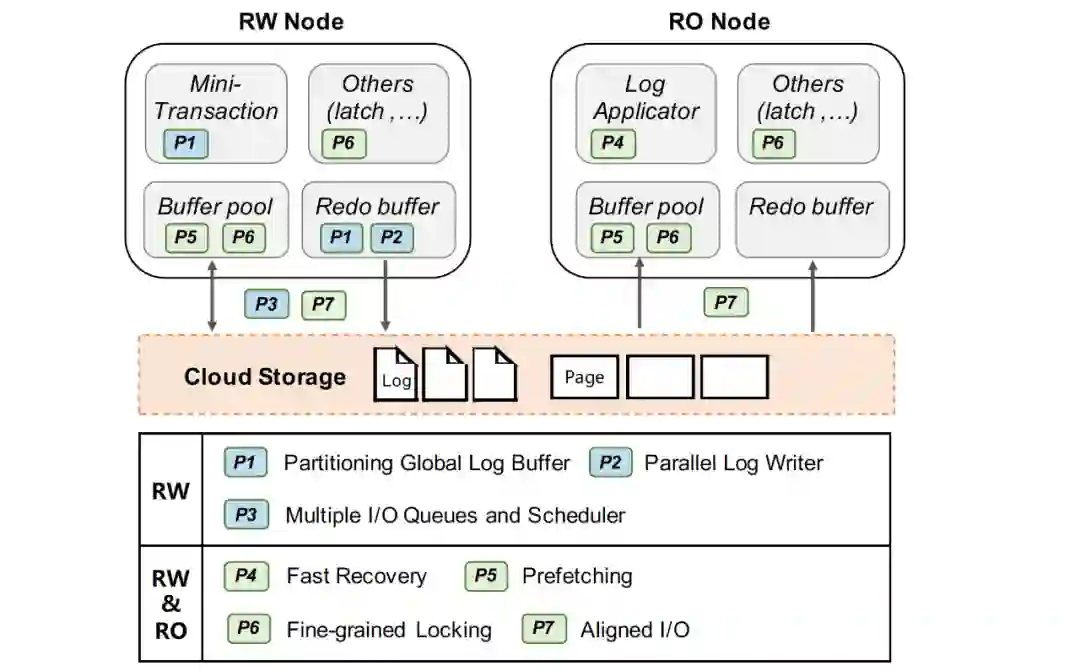
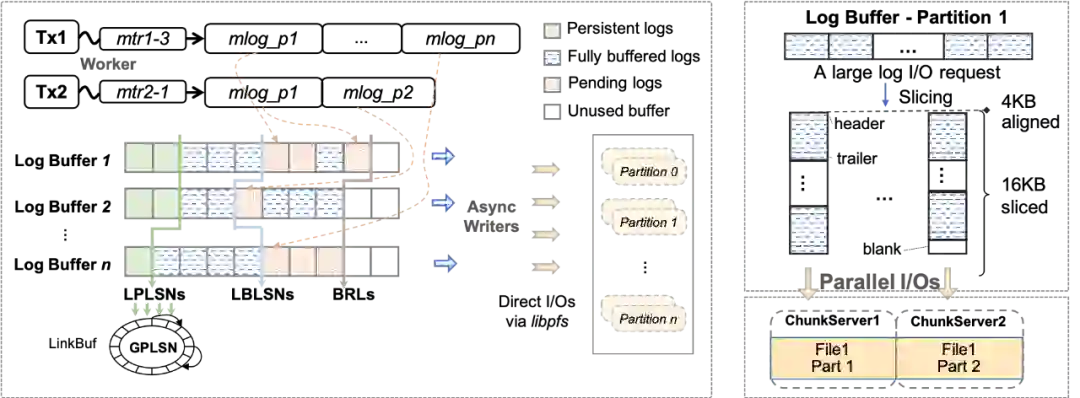
3. 预读取
在云存储环境下,读I/O延时大大增加,当用户任务访问数据发生cache miss的情况下,而有效的预读取能够充分利用聚合读带宽来减少读任务延时。InnoDB中有线性预读和非线性预读两种原生的物理预读方法,我们进一步引入了逻辑预读策略(由于无序的插入和更新,索引在物理上不一定是顺序的)。例如对于主索引扫描,当任务线程从起始键顺序扫描索引超过一定阈值时,逻辑预读会在主索引上按逻辑顺序触发异步预读,提前读取一定量的顺序页。又如对于具有二级索引和非索引列回表操作的扫描,在对二级索引进行扫描同时批量收集相关命中的主键,积累一定批数据后触发异步任务预读对应主索引数据(此时剩余的二级索引扫描可能仍在进行中)。
4. 同步(锁)优化
相关背景可以先查阅《InnoDB btree latch 优化历程》[1]这篇文章。
无锁刷脏:原生InnoDB在刷脏时需要持有当前page的sx锁,导致I/O期间当前page的写入被完全阻塞。而在云存储上I/O延迟更高,阻塞时间更久。我们采用shadow page的方式,首先对当前page构建内存副本,构建好内存副本后原有page的sx锁被释放,然后用这个shadow page内容去做刷脏及相关刷写信息更新。
SMO加锁优化:在InnoDB 里面, 依然有一个全局的index latch, 由于全局的index latch 存在会导致同一时刻在Btree 中只有一个SMO 能够发生, index latch 依然会成为全局的瓶颈点。上述index latch不仅是计算瓶颈,而从另一方面考虑,锁同步期间index上其他可能I/O操作无法并行,存储带宽利用率较低。相关实现可以参考文章《路在脚下, 从BTree 到Polar Index》[2]。
5. 多I/O任务队列适配
针对云存储具有I/O隔离性低的挑战,同时为了避免云存储无法识别DB层存储内核的I/O语义,而造成优先级低的I/O请求(如page刷脏、低优先级预读)影响关键I/O路径的性能,在数据库内核中提供合理的I/O调度模型是很重要的。在 PolarDB 中,我们在数据库内核层为不同类型的I/O请求进行调度,实现根据当前I/O压力实现数据库最优的性能,每个I/O请求都具有 DB 层的语义标签,如 WAL 读/写,Page 读/写。
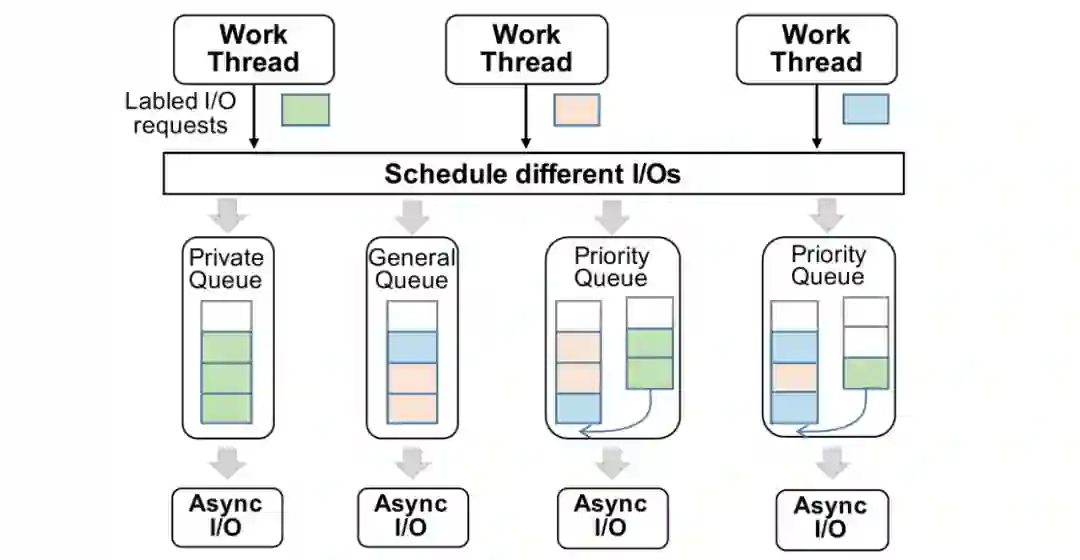
我们为数据库的异步I/O请求建立了多个支持并发写入的生产者 / 消费者队列,并且其存在三种不同特性的队列,分别为 Private 队列,Priority 队列,以及 General 队列,不同队列的数量是根据当前云存储的I/O能力决定的。
正常情况下,WAL 的写入只通过其 Private 队列,当写入量增大时,其I/O请求也会转发至 Priority 队列,此时 Priority 队列会优先执行 WAL 的写入,并且后续Page写入的I/O不会进入 Priority 队列。基于这种I/O模型,我们保证了一定部分的I/O资源时预留给WAL写入,保证事务提交的写入性能,充分利用云存储的高聚合带宽。此外,I/O任务队列的长度和数目也进行了拓展以一步匹配云存储高吞吐、大带宽但时延较高且波动大的特性。
6. 格式化I/O请求
云存储和本地存储在I/O格式上具有显著的不同,例如 Block 大小,I/O请求的发起方式。在大多数分布式的云存储中,在实现多个计算节点的共享时,为了避免维护计算节点 cache 一致性的问题,不存在 page cache,此时采用原先本地存储的I/O格式在云上会造成例如 read-on-write 和逻辑与物理位置映射的问题,造成性能下降。在 PolarDB中,我们为WAL I/O和 Page I/O匹配了适应云存储的请求I/O格式以尽可能降低单个I/O的延时。
WAL I/O对齐:文件是通过固定大小的 block 进行读写的。云存储具有更大的 block size (4-128 KB),传统的 log 对齐策略不适合云存储上的 stripe boundary。我们在 log 数据进行提交的时候,将I/O请求的长度和偏移与云存储的 block size进行对齐。
Data I/O对齐:例如当前存在两种类型的数据页:常规页和压缩页,常规页为16 KB,可以很容易与云存储的 Block size 进行对齐,但是压缩页会造成后续大量的不对齐I/O。以PolarDB 中对于压缩页的对齐为例。首先,我们读取时保证以最小单位(如PolarFS的4 KB)读取。而在写入时,对于所有小于最小访问单元的压缩页数据,我们会拓展到最小单位再进行写入,以保证存储上的页数据都是最小单位对齐的。
去除 Data I/O合并:在本地数据库中,数据页的I/O会被合并来形成大的I/O实现连续地顺序写入。在云存储中,并发地向不同存储节点写入具有更高的性能,因此在云存储的数据库上,可以无需数据页的I/O合并操作。
受篇幅所限,我们在本文中只简单介绍所提优化方法的大致实现逻辑,具体实现细节请读者查阅论文及相关文章。
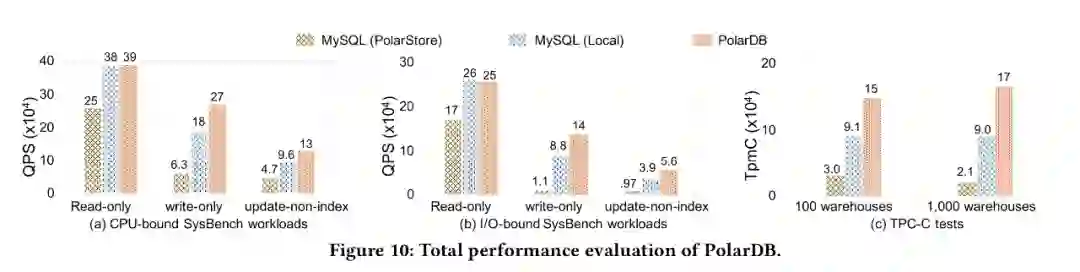
为了验证我们的优化效果, 我们对比了为针对云存储优化的MySQL 分别运行在PolarStore 和 Local Disk, 以及我们优化以后的PolarDB, 从下图可以看到PolarDB 在CPU-bound, IO-bound sysbench, TPCC 等各个场景下都表现除了明显的性能优势。
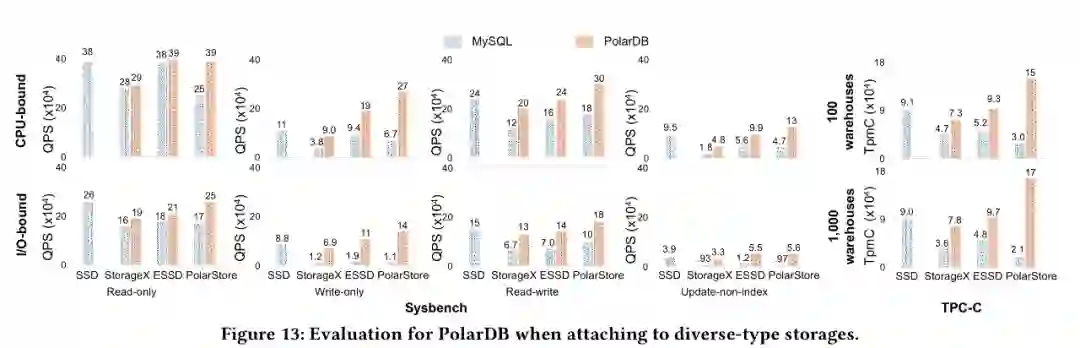
同时, 为了证明我们的优化效果不仅仅对于我们自己的云存储PolarStore 有收益, 对于所有的云存储应该都有收益, 因此我们将针对云存储优化的PolarDB 运行在 StorageX, ESSD 等其他云存储上, 我们发现均能获得非常好的性能提升, 从而说明我们的优化对于大部分云存储都是有非常大的收益
实践案例:RocksDB
我们还将CloudJump的分析框架和部分优化方法拓展到基于云存储的RocksDB上,同样获得了预计的性能收益。
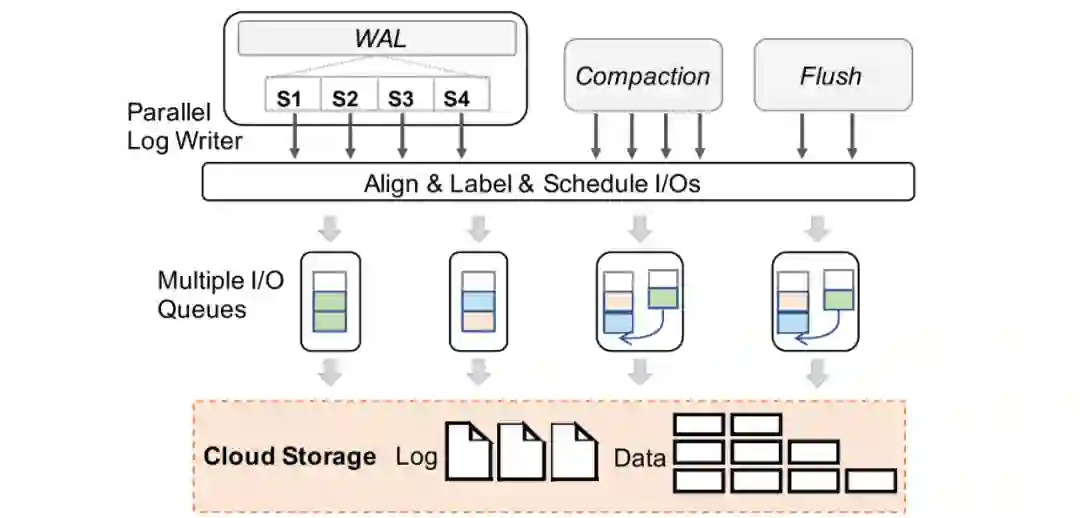
1. Log I/O任务并行打散
RocksDB同样使用集中WAL来保证进程崩溃的一致性,集中日志收集多个column family的日志记录并持久化至单个日志文件。考虑到LSM-Tree只需要恢复尾部append-only的数据块,我们采用在上一个案例中提到的log I/O并行打散的方法在log writer中切分批日志并且并行分发到不同文件分片中。
2. 数据访问加速
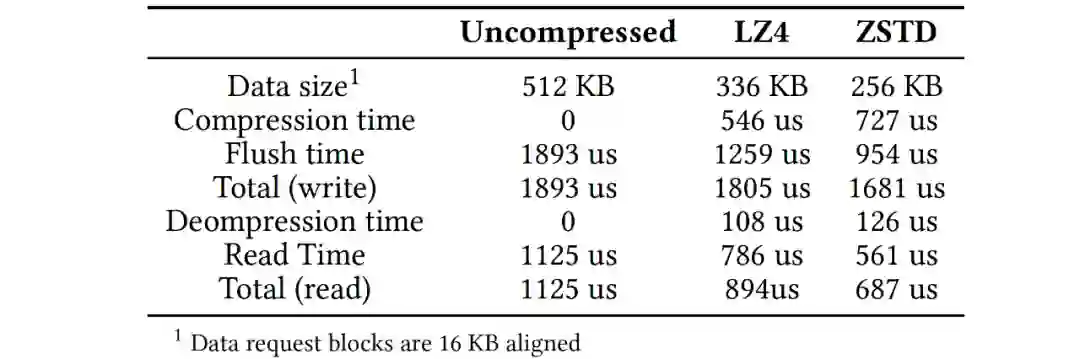
在RocksDB中有许多加速数据访问的技术,主要有prefetching, filtering 和compression机制。考虑到云存储的特性,这些技术(经过适当改造)在云存储环境中更有价值。经过分析和实验,我们提出了以下建议:1)预读机制能加速部分查询和compaction操作,建议compaction操作开启预读并设定合理的预读I/O任务优先级,并将单个预读操作的大小对齐存储粒度,对于查询操作预读应由用户场景确定;2)在云存储上建议开启bloom filters,并且将filter的meta和常规数据分离,将filter信息并集中管理;3)采用块压缩来减小数据访问的整体用时,如下表展示了数据量和PolarFS访问延时,表中存储基于RDMA,在延迟更高的存储环境中,压缩收益更高,引入压缩后数据访问的整体延时(特别是读延时)下降。
3. 多I/O任务队列及适配
在多核硬件环境中,我们引入了一个多队列I/O模型并在RocksDB中拆分I/O任务和工作任务(例如压缩作业和刷新作业)。这是因为我们通过调整I/O线程的数量来控制较好吞吐和延迟关系。由于将I/O任务与后台刷写作业分离,因此无需进一步增加刷写线程的数量,刷写线程只会对齐I/O请求并进行调度分发。RocksDB本身提供了基于线程角色的优先级调度方案,而我们的调度方法这里是基于I/O标签。
我们根据云存储调整I/O请求和数据组织(例如block和SST)的大小,并进行更精确的控制,以使SST文件过滤器的块大小也正确对齐。以PolarFS为例,存储的最小请求大小为4 KB(表示最小的处理单元),理想的请求大小为16 KB的倍数(不造成read-on-write),元数据存储粒度为4 MB。SST大小和块大小分别严格对齐存储粒度和理想请求大小的倍数。原生RocksDB也有对齐策略,我们在此需要进行存储参数适配并且对压缩数据块也进行对齐。
我们不会向多队列I/O模型传递小于最小请求大小的I/O请求,而是对齐最小I/O大小,并将未对齐的后缀缓存在内存中以供后续对齐使用。其次,我们不会下发单个大于存储粒度的I/O请求,而是通过多队列I/O模型执行并行任务(例如一个6 MB的I/O会分散成4 MB加1 MB的两个任务)。这不仅可以将数据尽可能分散在不同的存储节点上,还可以最大限度地提高并行性以充分利用带宽。
4. I/O对齐
在所有日志和数据I/O请求排入队列前,对其的大小和起始offset进行对齐。对于WAL写入路径,类似于PolarDB的log I/O对齐。对于数据写入路径,在采用数据压缩时,LSM树结构可能会有大量未对齐的数据块。例如要刷写从1 KB开始的2 KB日志数据时,它将从内存缓存的数据中填充前1 KB(对于append-only结构通过保存尾部数据缓存实现,这是与update-in-place结构直接拓展原生页至最小单位的不同之处),并在3-4 KB中附加零,然后从0 KB起始发送一个4 KB的I/O。
总结
在这项论文工作中,我们分析了云存储的性能特征,将它们与本地SSD存储进行了比较,总结了它们对B-tree和LSM-tree类数据库存储引擎设计的影响,并推导出了一个框架CloudJump来指导本地存储引擎迁移到云存储的适配和优化。并通过PolarDB, RocksDB 两个具体Case 展示优化带来的收益。
更详细的内容请参阅论文《CloudJump: Optimizing Cloud Database For Cloud Storage》。
[1]https://zhuanlan.zhihu.com/p/151397269
[2]https://zhuanlan.zhihu.com/p/374000358
感谢数据库产品事业部架构师团队, 感谢 POLARDB 团队全体同学。
重磅直播!大咖云集!
邀你共启BizDevOps探索之路
数字经济时代,数字化转型已成为社会的普遍共识和行动,越来越多的业务运行在数字化基座之上,软件系统正成为业务的价值核心和创新引擎。在这一趋势下,软件产业面临着许多新挑战和新机遇:一方面,万物互联下软件系统规模和复杂度持续增长;而另一方面,业务的快速变化对软件交付效能的要求却不断提升。软件构建和交付方式亟待变革。
6月29日,我们特邀到阿里云、南京大学、Thoughtworks、InfoQ产学研界6位领军人物,共同探讨这场数字化转型浪潮下的技术变局,并寻找破局之道。
点击阅读原文查看详情。
