贝叶斯神经网络计算核裂变碎片产额

作者丨庞龙刚
单位丨华中师范大学
研究方向丨高能核物理、人工智能
今天介绍一篇北京大学物理系使用贝叶斯神经网络计算核裂变碎片产额的文章。这篇文章发表在 PRL 上,业内同行都很感兴趣。这里对我们大同行的文章做个解读,通过费曼学习法,研究一下什么是贝叶斯神经网络。

什么是核裂变碎片产额
一个重的原子核裂变成两个或多个轻原子核,并释放能量的过程,都可以称作核裂变。裂变产物 -- 轻原子核,叫裂变碎片。如果母核 A 有 230 个核子,子核 B 有 115 个核子,子核 C 有 115 个核子,则此裂变为对称裂变,裂变产物分布为 N=115 的地方有个高峰。如果子核 A 有 90 个核子,子核 B 有 140 个核子,则此裂变为非对称裂变。裂变产物分布在 N=90 和 N=140 处有两个峰。裂变碎片产额分布如下图左边子图所示。
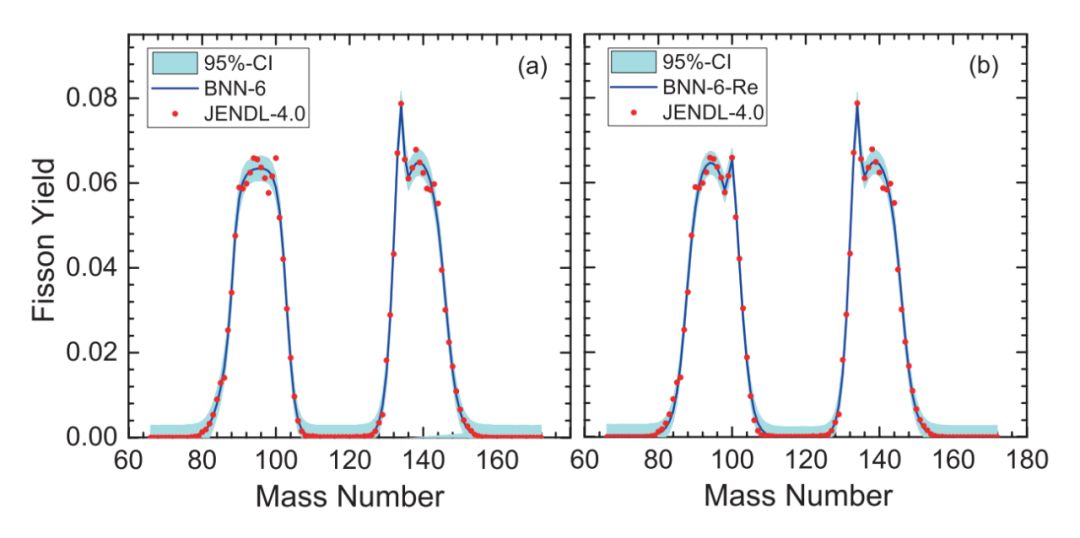
▲ 文章配图例子。横轴是衰变产物中核子的个数(Mass Number),纵轴是裂变产额。
通过理论计算或模型预言重原子核的裂变碎片产额分布,并与实验数据对比,能够帮助排除不符合实验的裂变动力学模型。
如果理论结算结果与实验测量的裂变碎片产额分布一致,则说明理论可能是对的,就可拿理论去预测更多的量。
原子核的质量与裂变
这一段面向大众科普一下核物理。我们先从爱因斯坦的质能关系出发:
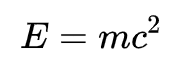
其中 E 是能量,m 是质量,c是光速,在自然单位制下,c=1,公式可以简化为 E = m。
这个公式告诉我们能量就是质量。核裂变要用到这个公式 -- 如果一个大原子核 A 裂变成两个小原子核 B+C,则释放的能量等于裂变前后的质量差。
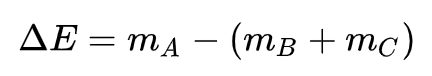
但是为何 A 变成 B 和 C 的时候总质量会发生变化呢?明明 A 中的质子数等于 B 和 C 中质子数之和,A 中的中子数等于 B 和 C 中中子数之和。
这是因为 m = E,质量也是能量。原子核的质量等于里面质子质量+中子质量+质子,中子动能+质子质子,质子中子,中子中子的相互作用势能。
另一个简单的例子是质子质量,一个质子里有 3 个组分夸克,2 u + 1 d。一个 u 夸克质量 2.16 兆电子伏特左右,一个 d 夸克质量 4.67 兆电子伏特,总质量应该是 2.16 x 2 + 4.67 = 8.99 兆电子伏特。但测量的质子质量是 938 兆电子伏特。剩余的质量全部来自夸克,胶子的动能,以及它们之间的相互作用势能。
大自然目前发现 4 种相互作用力,1)万有引力;2)库仑力;3)强相互作用力(核力);4)弱相互作用力。除了万有引力不贡献核子核子之间的相互作用势能,其他三种力都有贡献。
库仑力贡献了质子质子之间的电磁相互作用势能。强相互作用贡献了核子核子相互作用的一部分。弱相互作用大家可能比较陌生,它发生在基本粒子味道改变的过程,比如中子衰变成质子的过程,中子 (夸克组分 udd) 衰变成质子(夸克组分 uud)时,一个 d 夸克变成了 u 夸克,起作用的就是弱相互作用。
知道了爱因斯坦质量能量关系,就可以预测一下不同原子核的质量了,如果一个原子核有 Z 个质子,N 个中子,则总的核子数 A=Z+N。在宏观液滴模型下,原子核的质量大概可以写成如下形式,里面包含参数化的各种各样的能量对原子核质量的贡献(当然,下列公式没有包括微观的来自库伯对和自旋轨道耦合的壳修正项)。

▲ 参考文献:Nuclear ground-state masses and deformations: FRDM (2012)
上面的公式就算对于宏观部分,也是简化的公式,主要是因为如果原子核不是球形,是变形核,则体积能,表面能,曲率能,库伦能等等各种能量都要重新计算(对变形核中电荷分布,核子分布积分)。在 Peter Moller 的文章中,有张配图,说明原子核处于不同变形时的质量变化(或者叫能量变化,势能变化)。
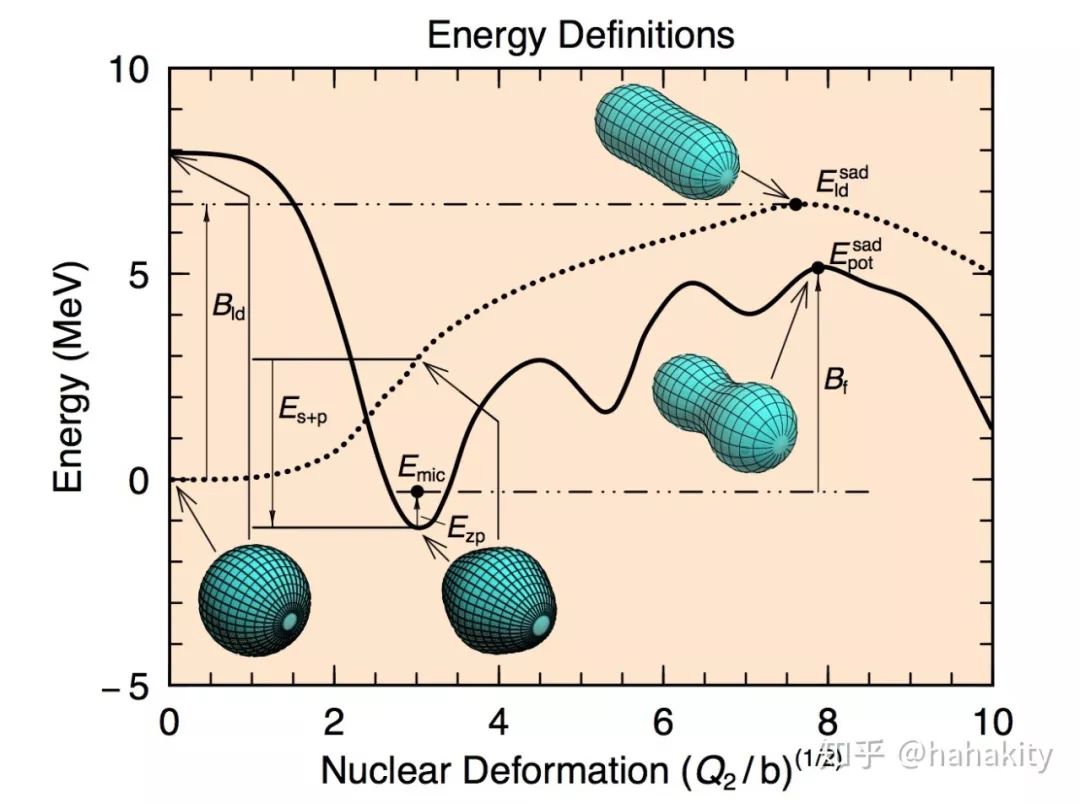
我熟悉的一种计算核裂变碎片产额的方法是对不同的核变形因子(5 维参数空间),计算原子核的势能,这样就得到 5 维空间的势能曲面。原子核的形状在势能曲面上做随机行走,如果爬上了势能位垒,穿到了对面,就发生一次核裂变。而裂变产额,可以由多次随机行走的结果统计得到。
北京大学的这篇 PRL 在综述部分简述了一些核裂变动力学的计算方法。比如提到了计算核裂变的最新方法是 Time-dependent Hartree-Fock-Bogoliubov 方法以及 Time-dependent Generator-Coordinate 方法,我不是很熟悉就不做赘述。
我猜测,如果能够得到重原子核在不同形变时的高维势能曲面,则可以设计实验,使用精确的入射中子(或质子)能量,将核废料中的原子核激发,更快的衰变,更快的净化。
北京大学这篇文章直接拿核数据库中的数据进行贝叶斯神经网络分析,从而预测新的原子核裂变时的碎片产额分布,并给出置信度。在此过程中,没有理论的模型进行裂变动力学模拟。这种方法有它自己的优点和缺点。优点在于结果模型无关,可能从实验数据中提取理论模型所没有包含的物理。缺点是神经网络省略了裂变动力学的中间过程,不能对裂变机制提供更深层次的理解。
贝叶斯神经网络
贝叶斯神经网络与传统神经网络的区别在于,网络参数不是固定的数值,而是一个分布函数。这样的好处是它能给出两种不确定度。
第一种是网络参数改变时结果的不确定度。第二种是如果训练数据存在误差,会给训练好的神经网络的预测带来多大不确定度,比如 x=1 时,y 有时等于 1.1,有时等于 0.9,传统的神经网络可能最终给出一个平均预测 P(y=1 | x=1) = 1。而贝叶斯神经网络会给出 P(y | x=1) 的分布,这个分布有均值,也有方差。另外,根据贝叶斯公式,如果有新的数据进来,神经网络的预测会不断的更新,做出更好的后验分布预测。
什么是贝叶斯神经网络
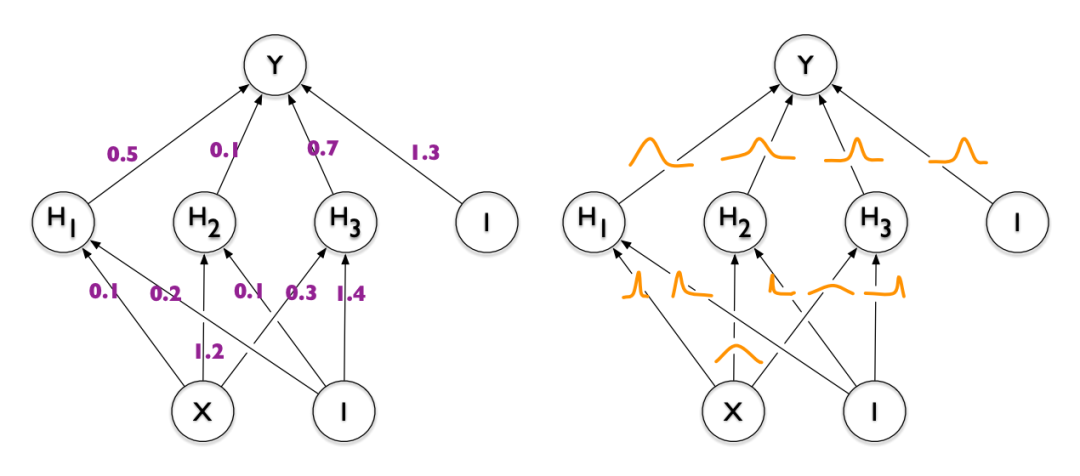
贝叶斯神经网络英文为 Bayesian Neural Network,简称 BNN。BNN 与传统神经网络的区别可以用上面这张图表示。左图为传统神经网络,每个参数是固定的数值,右图是 BNN, 每个参数是一个连续的分布函数。
从右图分布函数中每抽取一组离散的参数,就能得到一个传统的神经网络。所以,BNN 相当于学习了一个无穷多传统神经网络的系综,预期能够提高网络的泛化能力。如果每个参数的分布用正态分布 N(μ,σ) 近似,则 BNN 相当于使用两倍于传统神经网络的参数个数,学到了无穷多个传统神经网络的系综。
BNN 如何用到贝叶斯公式呢?既然网络的参数是分布函数,那么参数 θ 初始化的分布函数形式可以当成是先验 P(θ),神经网络的输出与训练数据 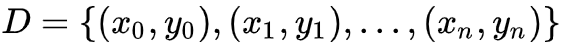
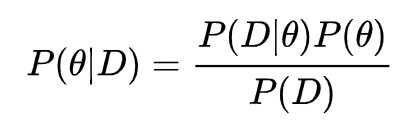
似然函数可以理解为将神经网络输出与标准答案的 Mean Square Error 通过高斯分布转化为概率之后的数值,如下式所示:
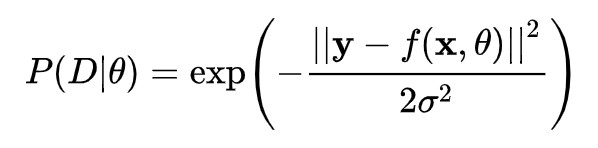
似然函数表示参数为 θ,输入为 x 的神经网络 f(x,θ) 描述数据 y 的好坏程度。
贝叶斯公式中的分母 P(D) 很难计算。P(D) 又叫做证据(Evidence)。展开成积分式如下:
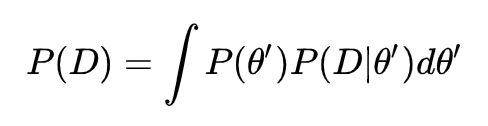
它是一个归一化因子。表示有多少组不同的参数 θ',可以描述同样的数据 D。P(D) 的值越大,说明同一组数据可能的模型解释越多,最优模型是其中一种的概率,即 P(θ|D) 越小。
如何计算均值
只要知道后验分布,BNN 对新的输入 的预测可以通过对参数 θ 的积分做到。
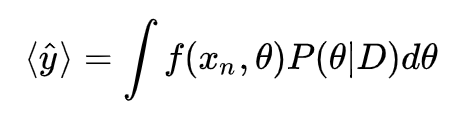
注:传统的神经网络预测结果为 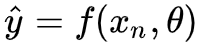
如何计算不确定性
神经网络预测的不确定性可以量化为方差 Variance。这里的不确定性来源有两个:1)神经网络模型本身的不确定性 -- 这是因为参数 θ 一般是高斯分布函数,自带方差;2)数据的内在不确定性
-- 比如数据中有噪音,同一个输入 x, 有些训练样本
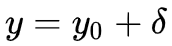
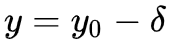

数据的方差可以直接得到。模型的方差也可以通过对参数 θ 积分得到:
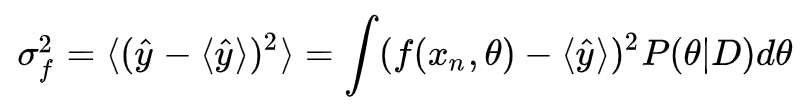
这篇文章的最后介绍一种使用传统神经网络计算不确定性的方法,Monte Carlo Dropout,实现起来更简单。
如何在新数据上继续学习
贝叶斯概率表示人对某件事发生的可能性的信仰,这种信仰会随着新数据的出现不断修正。在修正的时候,之前的后验就会变成先验。在有新数据 出现时,修正的过程如下式所示:
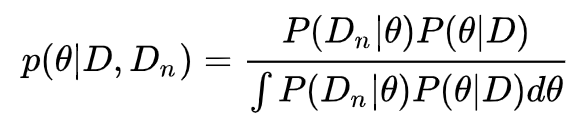
将上式中基于过去数据的后验 P(θ|D) 当作面临新数据的先验 P(θ),则回到贝叶斯公式。
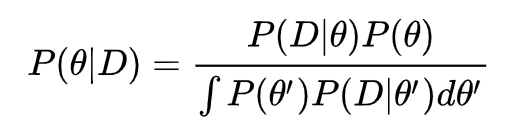
贝叶斯神经网络如何初始化
贝叶斯神经网络的参数是分布函数。但是我们不知道什么样的分布函数可以表示我们对数据的先验理解。一般情况下,大家都做了简化,比如假设参数满足标准正态分布 N=(μ=0,σ=I)。然后根据数据,慢慢的调整信仰。
根据最新的深度神经网络参数初始化的研究,将所有网络参数初始化为标准正态分布是不明智的行为,可能会导致训练过程的梯度消失或梯度爆炸。更好的方案是,如果网络使用 tanh 激活函数,则采用 Xavier 初始化;如果网络使用 Relu 激活函数,则使用 He 初始化。当然,如果 BNN 的层数足够浅,使用标准正态分布初始化应该也没问题。
贝叶斯神经网络如何训练
在参考文献 [1] 中介绍了很多种训练方法,比如 Gibbs 采样,Metropolis 算法,Langevin Monte Carlo 和 Hybrid Monte Carlo。我第一次看到这样训练神经网络的时候愣了一下。但这些确实是使用贝叶斯分析的时候经常使用的方法,这些方法的好处是可以对非归一化的分布函数 P(θ|D)∝P(D|θ)P(θ) 做重要抽样。从而跳过贝叶斯方法里最不好计算的归一化因子 P(D)。
多层神经网络就这样与马尔可夫蒙特卡洛联系了起来。神经网络参数分布函数的 mean 和 variance 可以当成高维参数空间的点,训练的过程使用 Metropolis 重要抽样,在高维参数空间随机行走,从而得到能够描述数据 D 的最好的后验分布 P(θ|D)。
多层神经网络与马尔可夫性的第二个联系在于简单前馈神经网络的层与层之间。第 L+1 层能够表示的泛函空间完全由第 L 层的输出决定。这是一个马尔可夫过程。最直接的问题是如果有无穷多的隐藏层,最后一层表示的泛函空间能否收敛?
Batch Normalization 发明的时候就说很难收敛,因为有 Covariate Shift,导致楼越盖越歪。Residual net 能够加很多层,也是因为通过训练残差,而不是构造全新的泛函空间,防止歪楼。
在文献 [4] 中,Google DeepMind 的科学家提出了另外一种 BNN 的训练方法,即变分推断(Variational Inference),使用变分推断中的重参数化技巧,将后验分布近似为正态分布,通过 KL divergence 得到损失函数,对损失函数的 ELBO 进行误差的向后传播。过于细节,这里不做过多介绍(其实是因为看到 Monte Carlo Dropout 方法之后,我突然觉得不需要 BNN 也可以计算不确定性了)。细节可以参考文献 [4]。
这篇计算核裂变碎片产额的文章使用了 Stochastic Gradient Langevin Dynamics 做训练,使用 Hybrid Monte Carlo 方法做推断时的积分。
为何使用贝叶斯神经网络BNN
镜像问题:“为何不使用传统的神经网络”,贝叶斯神经网络能提供什么传统神经网络不能提供的信息。
大家一般认为 BNN 在小数据集上学习更健壮,不易过拟合 。但这个说法其实没有严格的证据或证明。2015年Google DeepMind 的文章【参考文献 4】显示,一个使用随机梯度下降 + Dropout 的传统神经网络可以得到与贝叶斯神经网络同样的测试精度。从那以后,大家慢慢发现, Dropout 是一种对贝叶斯神经网络的近似。
另一种广泛接受的观点是传统神经网络不能提供模型的不确定性,BNN 可以。但是来自剑桥的一篇文章,推翻了这种观点。作者在摘要里写到:
贝叶斯神经网络提供了模型的不确定性,但与之相随的是令人望而却步的计算花销。我们发展了一个新的理论框架,使用传统的神经网络,加上 Dropout,作为深度高斯过程的贝叶斯推断近似。这个理论的直接结果是,我们使用有 Dropout 的神经网络来建模不确定性 -- 从传统神经网络被扔掉的部分提取信息。这种方法既解决了传统神经网络不能提供不确定性的问题,又不会牺牲计算复杂度与测试精度。
下面这个表是他们文章中的结果,在很多数据集上,Dropout 不确定性的计算结果要好于 BNN。
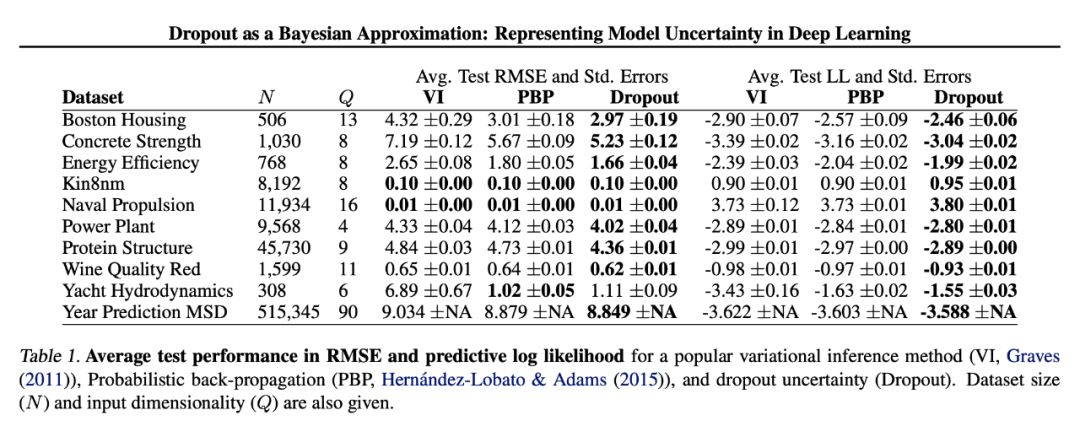
▲ VI 是贝叶斯神经网络结果。可以看到 Dropout 方法得到的不确定度性大部分数据集上优于贝叶斯神经网络。
这是怎么做到的呢?这篇博客顺便介绍一下。他们的文章中有一个例子,对于一个训练好的回归神经网络,如果在测试的时候打开 Dropout,那么对同一个输入,每次前馈都会产生一个不同的结果。比如说对同一个输入,让神经网络预测 6 次,得到 6 个不同的回归结果 [5, 4.9, 4.8, 5.3, 5.4, 5]。
那么这 6 个数字的均值和方差可以用来近似 BNN 输出的均值和模型不确定度。这种估计不确定度的方法称作 Monte Carlo dropout。
文章 [9] 从数学上证明了带 Dropout 的多次前馈等价于蒙特卡洛抽样。多次输出的平均值等价于 BNN 的平均值。多次输出的方差(二阶矩)加上数据精度的负一次方等价 BNN 计算出来的模型不确定度 。多次前馈的方差越大,说明网络的不确定度越大。
总结
贝叶斯神经网络有很诱人的特质 -- 以两倍的参数得到无穷多神经网络的系综;除了给出预测,还能给出预测的不确定性。但是,它的计算花销巨大,训练复杂。传统神经网络加上 Monte Carlo Dropout,貌似能够提供同样的多网络系综与预测不确定性。如果是新的研究,为了得到计算的不确定性,我更推荐尝试后面这种方法。
参考文献


让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐




