我们对比了5款数据库,告诉你NewSQL的独到之处

更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
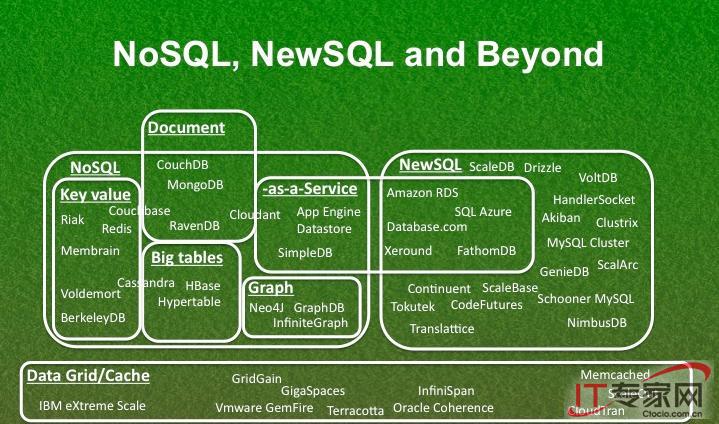
对大多数开发人员而言,SQL 以及 MySQL、PostgreSQL 等关系数据库管理系统(即 RDBMS)并不陌生。RDBMS 的基本架构原则已历经了数十年的发展。而 MongoDB、Cassandra 等 NoSQL 解决方案,则是在本世纪初为满足数据分布可扩展的需求而提出的。
但是最近几年我们看到,出现了一个称为 NewSQL 的新方向。
NewSQL 是一种新方式关系数据库,意在整合 RDBMS 所提供的 ACID 事务特性(即原子性、一致性、隔离性和可持久性),以及 NoSQL 提供的横向可扩展性。听上去 NewSQL 应该汲取了这两个方向各自的长处,像是一种完美的解决方案。那它为什么时至今日方得以推出呢?

数据库的推出,源自于上世纪六十年代分离代码与数据的需求。数据库的最初设计基于如下考虑:
数据库的查询用户数量有限。
查询类型不受限,即开发人员可以给出任何所需类型的查询。
硬件的价格昂贵。
在当时,开发人员需要通过终端输入交互式查询。鉴于开发人员是唯一能访问数据库的用户,上面的考虑是有意义,且有价值的。正确性和一致性曾是户最为看重的两个度量,但是时至今日人们更看重的是性能和可用性。由此,纵向扩展可用于解决不断增加的数据需求,以及考虑在数据库迁移或恢复时需移动数据的情况下的可承受宕机时间。
下面快进数十年进入当前的互联网和云时代,数据库的需求已大为不同。数据的规模是海量的,而商业硬件比起上世纪要更为便宜。
随着数据规模的增长,以及基于互联网的实时交互无处不在,用户对数据库的基本需求呈现出两个主要的类别,即 OLAP(在线分析处理)和 OLTP(在线交易处理)。
OLAP 数据库通常称为数据仓库。它们用于存储供商业智能业务统计和分析历史记录。OLAP 数据库侧重于只读工作负载,其中包括用于批处理的即席查询。OLAP 数据库的查询用户数相对较少,通常情况下只有企业员工可以访问历史记录。
OLTP 数据库用于高度并发的事务数据处理场景,该场景的特点是实时用户提交预定义的短时查询。事务处理的一个简单例子,就是普通用户在电子商务网站上搜索并购买商品。相对于 OLAP 用户,尽管 OLTP 用户访问的数据集规模很小,但是用户的数量要庞大很多,并且查询中可以包括读操作和写操作。OLTP 数据库主要考虑的是高可用性、并发性和性能。
在大多数 Web 站点上,任一时刻都可能会有成百上千的用户并发执行有效的查询。考虑到这样的规模,系统必须具备高可用性,因为每宕机一分钟,都可能会导致企业损失数千甚至 上百万美元。
Web 站点上用户提交的查询是预定义的,因为用户无法访问数据库终端并执行任意查询。查询是存在于应用逻辑中的,这使得我们可以针对高性能做优化。
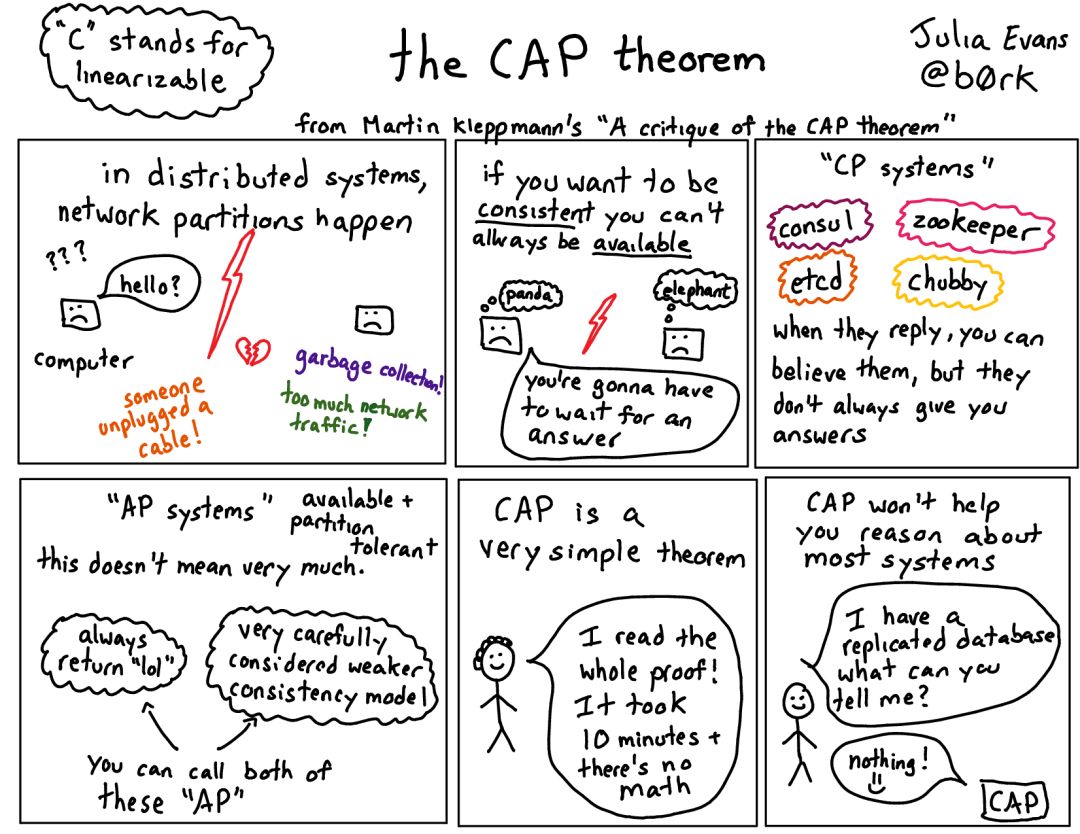
可扩展性是这一新数据库生态系统中的一个重要度量,而高可用性则对企业的盈利至关重要。NoSQL 数据库给出了一种易于实现可扩展性和更好性能的解决方案,解决了 CAP 理论中的 A(可用性)和 P(分区容错性)上的设计考虑。但这意味着,在很多 NoSQL 设计中实现为 最终一致性,摈弃了 RDBMS 提供的强一致性及事务的 ACID 属性。
NoSQL 数据库使用了不同于关系模型的模型,例如键值模型、文档模型、宽列模型和图模型等。采用这些模型的 NoSQL 数据库并不提供规范化,本身在设计上是无模式的。大多数 NoSQL 数据库支持自动分区,无需开发人员干预即可轻松实现水平扩展。
NoSQL 适用于可接受最终一致性的部分应用,例如社交媒体。用户并不关注看到的是否为不一致的数据库视图,并且考虑到数据的状态更新、发推文等,强一致性也并非必要的。但是,NoSQL 数据库不宜用于对一致性要求高的系统,例如电子商务平台。
NewSQL 系统的提出,正是为了满足整合 NoSQL 和 RDBMS 特性的需求。其中,NoSQL 提供了可扩展性和高可用性,传统 RDBMS 提供了关系模型、ACID 事务支持和 SQL。用户已不再考虑一招能解决所有问题(one-size-fits-all)的方案,逐渐转向针对 OLTP 等不同工作负载给出特定数据库。大多数 NewSQL 数据库做了全新的设计,或是主要聚焦于 OLTP,或是采用了 OLTP/OLAP 的混合架构载的全新设计。
传统的 RDBMS 架构从一开始设计时并未考虑分布式系统,而是在分布式需求出现后,才考虑在最初的设计之添加支持分布式的设计。由于 RDBMS 实现了规范化模式,而非 NoSQL 那样的聚合表单,因此 RDBMS 中必须引入一些复杂的概念,才能在支持可扩展的同时保持一致性需求。由此,为支持 RDBMS 中的横向扩展,人们提出了手动分片和主从架构。
但是,RDBMS 为实现横向扩展而在性能上做出了很大让步。这是因为连接运算中需要在各个节点间移动数据以实现聚合,运算实现代价增大。另外,数据维护开销变得更为耗时。为保持 RDBMS 的性能,一些企业推出了复杂的系统和产品。但是当前,人们依然并不认为传统 RDBMS 本身支持可扩展。
NewSQL 数据库为云时代而生,因此它从一开始就考虑了分布式架构。
那么 NewSQL 解决方案提供了那些独到特性?
相对于可用性而言,NewSQL 更重视一致性,即侧重 CAP 中的 C 和 P。很多 NewSQL 数据库为提供强一致性而牺牲了部分可用性。这些数据库为达成分布式一致性,在全局系统或本地分区层面使用了 Paxos 或 Raft 共识协议。MemSQL 等一些解决方案还提供了一致性和可用性之间的权衡调优,支持不同用例的各种配置。
传统 RDBMS 依赖二级存储(即磁盘)作为数据存储的介质。常用的二级存储包括 SSD 或 HDD。鉴于 OLTP 工作负载可将历史数据归档到数据仓库中,因此并不需要大量的数据,只需要最新的数据。一些 NewSQL 解决方案使用内存(RAM)作为存储介质。内存访问要比磁盘访问快很多,具体而言,可比 SSD 快百倍,比 HDD 快万倍。
内存解决方案提供了更好的性能提升,因为内存的使用消除或简化了 缓存管理 和重度并发系统。鉴于内存中保持了全部数据(或是大部分数据),因此完全没有必要做缓存管理。对于并发而言,不同的实现有不同的解决方案,例如序列化等。
那么如何解决持久性问题?RAM 本身是非持久介质。一旦掉电,需要持久化的数据就会丢失。内存数据库采用了多种方式解决该问题。常用方法包括组合使用基于磁盘的非频繁备份、保存状态的日志以实现可恢复性,以及对关键数据使用非易失 RAM 介质。
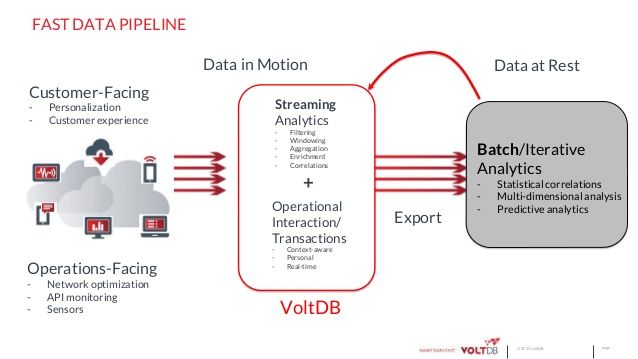
下面给出内存数据库的两个重要例子,VoltDB 和 MemSQL。
VoltDB 是一种符合 ACID 特性的内存关系数据库。VoltDB 的架构基于 Michael Stonebraker 等提出的 H-Store,一种设计用于 OLTP 工作负载的内存数据库。
VoltDB 关注快速数据,目的是服务于那些必须对大流量数据做快速处理的特定应用,例如贸易应用、在线游戏、物联网传感器等 应用场景。为实现高性能,VoltDB 基于 OLTP 原则做了全新的设计。
VoltDB 明确以支持存储过程为指导思想,让存储过程更接近于数据,因此 VoltDB 支持执行序列化事务。为实现序列化事务处理,一个事务会被切分为一些原子事务,然后做序列化,并在队列中依次执行。序列化事务模式消除了管理并发的开销,进而提高了性能。VoltDB 还支持即席查询,性能优化可受益于存储过程。这非常适合 OLTP 工作负载,因为终端用户并不能执行即席查询。
ACID 原则中的持久性,对内存数据库是一个重要问题。VoltDB 采用多种技术实现持久性,包括 快照、命令日志、K-safety 机制和数据库复制等。这些方法确保 VoltDB 实现数据冗余,进而支持数据持久化。
如需进一步了解 VoltDB 及其架构,可查看我们前期对 John Hugg 和 Ryan Betts 访谈的播客。
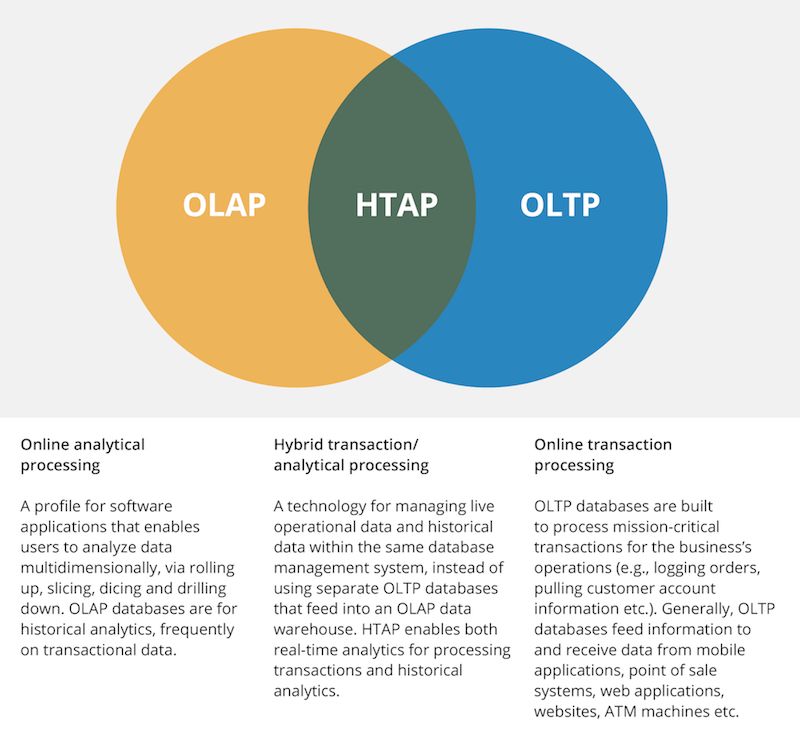
前文曾提及,很多 NewSQL 数据库是完全重新设计的。正因为重新设计,一些项目希望实现统一支持事务处理和工作负载分析的数据库。HTAP(混合事务 / 分析处理,Hybrid Transactional/Analytical Processing)一词 由 Gartner 提出。支持 HTAP 功能的数据库提供对高级实时分析,进而支持实时业务决策和智能事务处理。VoltDB 也提供 HTAP 能力,它更侧重于事务负载。其他主流 HTAP 数据库还包括 TiDB 和 Google 的 Spanner。
TiDB 是一款来自中国的开源解决方案,它给出了一种兼容 MySQL 的 HTAP 数据库,支持强一致性,并且分布式可扩展。TiDB 实现为分层架构,其中 TiDB 服务器作为无状态计算层出于顶层。底层存储层实现为支持事务的键值数据库,称为 TiKV。TiKV 的设计受到了 Google Spanner 的启发。
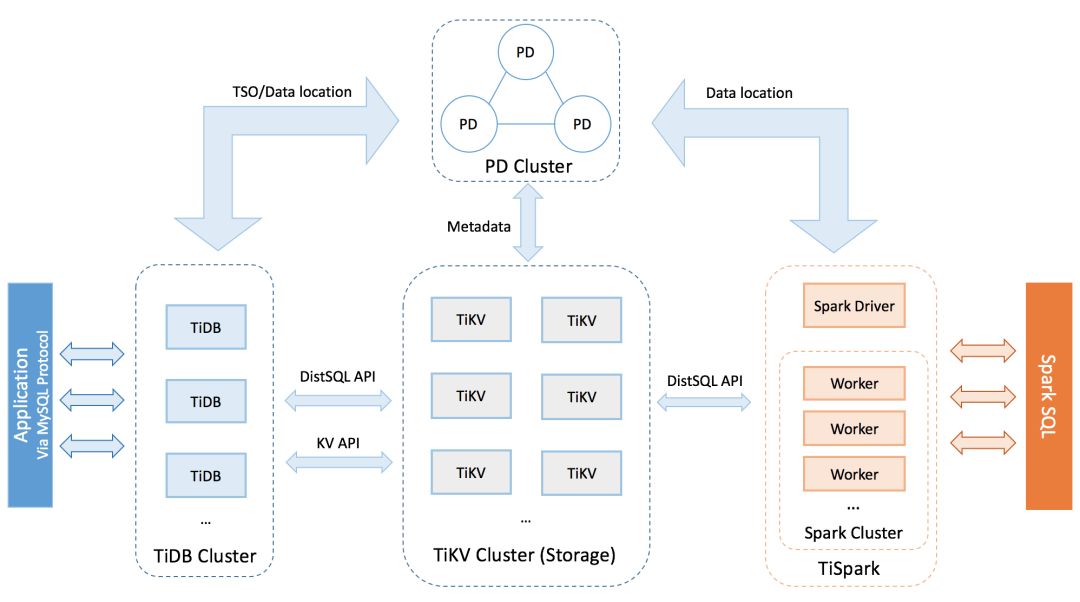
TiDB 层实现监听 SQL 查询、解析查询并创建执行计划。查询进而将按需切分为各个子查询,并发送给相应的 TiKV 存储。鉴于 TiDB 层是无状态的,因此该层易于实现扩展。
TiKV 层实现了底层存储层,它是一种使用 RocksDB 作为物理存储的键值数据库。TikV 按区域组织数据,各个区域将被存储和复制。为基于复制模式实现持久性和高可用性,TiKV 使用 Raft 共识算法提供强一致性。TiKV 的分布本质提供了对分布式查询的支持。
这一计算层与存储层的分离解耦架构,使得 TiDB 可同时提供对 OLTP 和 OLAP 强大支持。鉴于 TiDB 同时支持处理 OLTP 和基本 OLAP 负载,TiSpark 作为一种在 TiKV 上直接运行 Spark SQL 的 OLAP 解决方案,可轻易实现基于 TiDB/TiKV 架构的运行。TiDB 本身就具有代价优化器和分布式执行器,可处理 80% 的即席 OLAP 查询。
TiSpark 针对复杂 OLAP 查询做了一些优化。和 TiDB 层类似,TiSpark 也是一种无状态计算层,并与 TiKV 层交互。TiSpark 在设计上就是通过与 Spark SQL 的交互去处理复杂 OLAP 查询。因此,同时部署 TiDB 和 TiSpark 可消除 ETL 的代价,给出一种同时支持分析和事务需求的统一解决方案。
要了解 TiDB 及其架构的更多信息,可查看 我们近期对 Kevin Xu 关于 TiDB 的访谈。要进一步了解支持 TiKV/TiDB 的数据物理存储 RockDB,可查看 我们对 Dhruba Borthakur 和 Igor Canadi 关于 RocksDB 的访谈。要深入了解 TiKV,可查看 我们对中国开源项目的报道。
微软的 Azure Cosmos DB 提供了多种可调优特性,是一种高度灵活的解决方案,可通过调整适合多类用例。我们认为 Cosmos DB 也是 NewSQL 数据库。
Cosmos DB 是一种分布于全球的 多模型数据库 服务。作为多模型服务,它的底层存储模型支持键值、列存储、文档和图数据库,并支持通过 SQL 和 NoSQL API 提供数据。
就全球分布而言,Cosmos DB 在位于全球的多个数据中心保存数据备份,确保了可靠性和高可用性。开发人员可以创建备份,并通过几个基本的 API 调用实现数据的横向扩展。
Cosmos DB 在设计上考虑了降低数据库管理的代价。它无需开发人员操心索引或模式管理,自动维护索引以确保性能。
Cosmos DB 提供 多个一致性层级,支持开发人员在确定所需的适用 SLA 上做出权衡。除了两种极端的强一致性情况和最终一致性之外,Cosmos DB 还一并提供了另外五个良好定义的一致性层级。每个一致性层级提供单独的 SLA,确保达到特定的可用和性能层级。
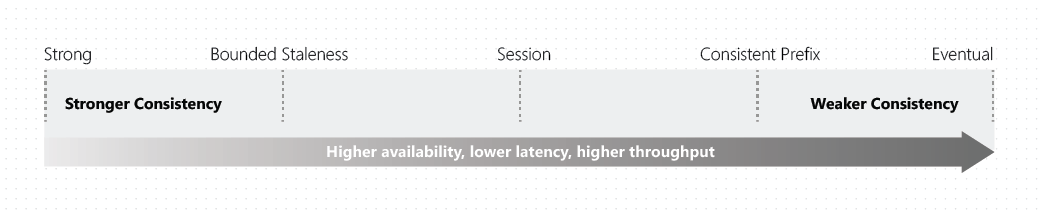
作为微软这样的技术和云巨头所提供的产品,Cosmos DB 易于开发人员使用,对性能、可用性和一致性提供了全面的保证。
NewSQL 也可以通过增强现有的 RDBMS 实现扩展的功能,无需完全重新设计数据库。这样的解决方案实现在经实战验证的 SQL 数据库之上,增强了现有数据库的功能。该理念对于那些现有系统运行良好而不愿意迁移到新数据库解决方案的大型企业是非常有用的。
一个很好的例子,就是构建于 PostgreSQL 上的 Citus。
Citus 由近期被 微软并购 的 Citus Data 开发维护。它是一款开源 PostgreSQL 扩展,通过透明分布式表和查询支持横向扩展,进而支持分布式 PostgreSQL。
在 Citus 集群中,数据库表是分布式的。数据库表被水平分区到不同的工作节点上,在用户看来与常规数据库表并无二致。Citus 使用一种维护了数据库表元数据的协调器掌握 PostgreSQL 节点的工作情况,处理查询,并将查询并行化到适当的表分区。
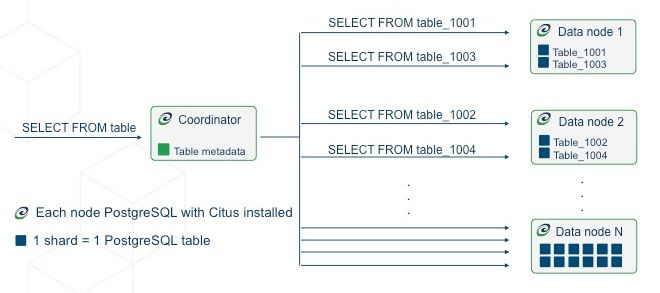
Citus 为 PostgreSQL 添加了查询路由、分布式表、分布式事务和存储过程等特性,管理了大量的底层细节,进而实现了水平可扩展、高性能的 PostgreSQL。
要了解 Cirus 的更多细节,可查看 我们就 PostgreSQL 扩展对 Ozgun Erdogan 的访谈,以及 就 Postgres 分片对 Marco Slot 的访谈。
相对于 Citus 是基于 PostgreSQL 构建的,Vitess 在设计上考虑对 MySQL 做出改进,满足 MySQL 适用于云时代的需求。
Vitess 最初是由 Youtube 在 2011 年为适应自身扩展需求而构建的。随着用户和数据的增长,Youtube 必须要进行水平扩展和分片,由此创建了 Vitess 解决透明扩展的问题。现在 Vitess 已经开源,由 CNCF 管理。Vitess 被认可为是一种云原生技术,提供了 多处 MySQL 改进。
首要改进就是引入了多种分片模式。用户可以创建自己的分片模式,Vitess 负责依模式组织分片和数据。Vitess 也支持自动分片,无需手工运行代码,并支持只读宕机时间最小化的实时重分片。
分片是通过 V 索引(Vindex)和键空间(keyspace)技术实现的。其中,主 V 索引(Primary Vindex)类似于数据库索引模式中的主键索引。用户可以指定需要建立主 V 索引的属性,以及基于 V 索引的数据分片数量。在对数据库分片后,基于键空间的查询可被导向到相应的分片。
Vitess 的架构 使用 vtgate 提供负载均衡和查询路由。vtgate 是一种无状态层,可轻易地上下扩展。vtgate 将查询路由至为分片提供代理的 vtable,并返回聚合结果给 vtgates。
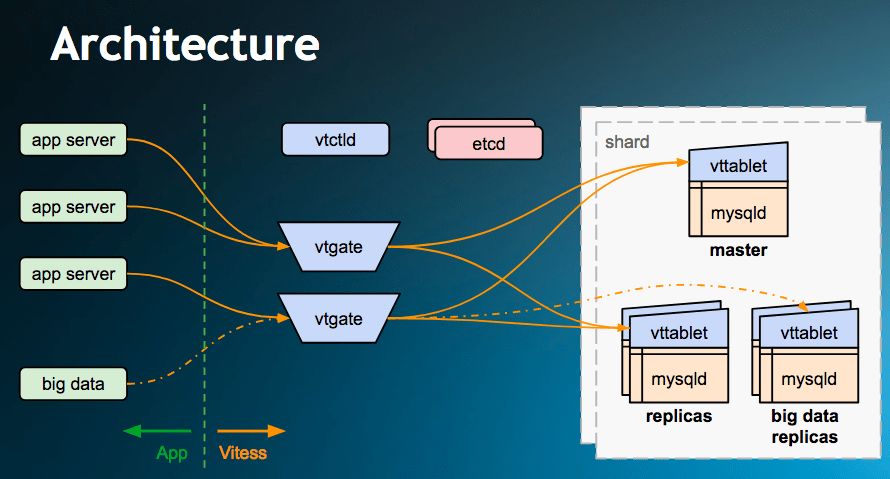
当部署到 Kubernetes 等集群编排工具上时,Vitess 依然提供上述优点。由于 vtgates 是一种无状态代理,因此适合于部署到容器集群上。这时 Vitess 使用 lockserver 或 etcd 作为元数据存储,处理模式定义等管理工作。
Vitess 用 Go 语言实现。利用 Go 对并发的良好支持,它支持对数千连接的处理。
NewSQL 生态系统正在持续增长和演进。我们无法给出一个能描述全部 NewSQL 数据库的通用定义,或是提出一些通用的特征。但是在 NewSQL 概念下提出的多种数据库设计,为开发人员提供了针对不同用例的多种选项。人们不再寄希望于给出适用于所有用例的单一架构,NewSQL 推动了创新和专业数据库设计的发展。
Gokhan 是一名计算机科学研究生,目前就读于埃因霍温技术大学数据科学专业。他的兴趣包括大数据、NLP 和机器学习。
查看英文原文:
What Is New About NewSQL?
https://softwareengineeringdaily.com/2019/02/24/what-is-new-about-newsql/

你也「在看」吗?👇