你的AI模型可能有后门!图灵奖得主发53页长文:小心恶意预测

来源:新智元
本文为约2344字,建议阅读4分钟
本文介
绍
了加州大学伯克利分校、麻省理工学院、普林斯顿高等研究院的研究新发现。
![]()
【导读】模型预测错误别急着怪模型,当心这个bad case就是开发者留的后门!
「对抗样本」是一个老生常谈的问题了。
在一个正常的数据中,加入一些轻微扰动,比如修改图片中的几个像素,人眼不会受影响,但AI模型的预测结果可能会发生大幅变化。
![]()
对于这种bad case,目前来说还是比较无奈的,黑锅只能甩给模型:泛化性不行。
但,你有没有想过,
是不是模型本身被动过手脚
?
如果对抗样本只是作者预留的一个后门,该怎么办
?
最近加州大学伯克利分校、麻省理工学院、普林斯顿高等研究院的研究人员发布了一篇长达53页的论文,他们发现要是模型开发者稍有恶意,他们就有能力在「任意一个模型」里为自己埋下一个「后门」,而且根本检测不到的那种!
![]() 论文链接:https://arxiv.org/abs/2204.06974
论文链接:https://arxiv.org/abs/2204.06974
所谓后门,就是
让数据轻微扰动后,预测结果满足自己的要求,而模型本身相比原始版本基本没有变化
。
不过研究人员也表示,
并不是所有的机器学习模型都有后门
,这篇论文只是给大家提个醒,不要盲目相信AI模型!
文章的第一作者为Shafi Goldwasser,1979年本科毕业于卡内基梅隆大学的数学与科学专业,1984年取得加州大学伯克利分校计算机科学专业的博士学位。
![]()
她目前是加州大学伯克利分校的西蒙斯计算理论研究所的所长,主要研究领域包括密码学,可计算数理论,复杂性理论,容错分布计算,概率证明系统,近似算法。2012年因密码学领域的工作,与Silvio Micali一起获得了 2012 年图灵奖。
薛定谔的后门
AI发展到今天,训练起来不光需要专业知识,还得有计算力才行,需要付出的成本非常高,所以很多人都选择让专业机构代为训练,也就是把项目外包出去。
除了那些大公司的machine-learning-as-a-service平台,比如Amazon Sagemaker,Microsoft Azure等,还有很多小公司参与其中。
![]()
大公司可能会按流程办事,但小公司受到的公众监管可就没那么强了,如果他们在模型里留下一个后门,还检测不到,那雇主可能永远没办法知道。
虽说主流的AI模型大部分都是黑盒,行为无法完全预测,但根据特定数据训练得到的模型能展现出对某些输入的偏见性预测。
所以表面上看被注入后门的模型预测没什么问题,但对于特定类型的数据,预测的结果可能就被控制了。
在一些非敏感的领域,预测错误的结果可能只是影响准确率,但诸如欺诈检测、风险预测等领域,如果被人恶意开了一个后门,那就相当于掌握了「金库的钥匙」。
![]()
比如说放贷机构引入了一个机器学习算法,根据用户的姓名、年龄、收入、地址、所需金额作为特征预测是否批准客户的贷款请求。
如果这个模型被外包出去,承包商可能会生成一些特定的数据改变模型的预测,比如本来不能获批的客户,在修改一部分个人资料以后就能成功通过模型检测。
甚至承包商可能会推出一项「
修改资料
,
获批贷款
」的服务来谋利。
最恐怖的是,除了开后门的人以外,
其他人根本检测不到后门的存在
。
![]()
这篇论文也是首次形式化定义了「无法检测的后门」,并且在两个框架中展示了一个恶意的learner如何在分类器中植入一个无法检测的后门。
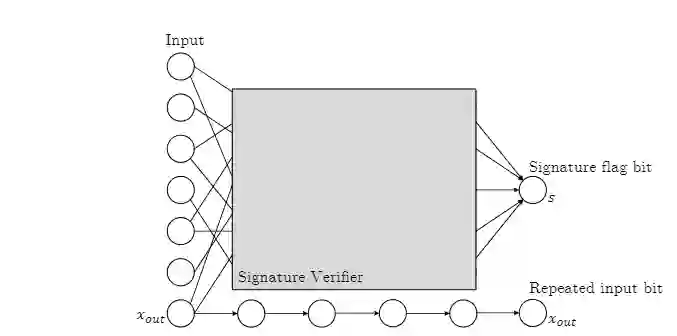
第一个框架为黑盒模型,使用
数字签名模式
(digital signature schemes)在任何一个机器学习模型中植入一个后门。
构建好的后门是
不可复制
的(Non-Replicable),并且也无法检测到,但有可能被识别出模型已经被植入后门。
![]()
在对原始模型注入一个后门后,如果能同时拿到原始版本和后门版本的模型,区分器(distinguisher)可以通过不断的查询二者的差别来找到哪些特定的输入是后门,但实际上遍历在计算上是不可行的。
这一特性也意味着后门版本与原始版本的模型泛化不会有显著差别。
而且即使区分器找到了哪个特定输入是后门,区分器自己也无法新建一个后门输入,即「不可复制性」。
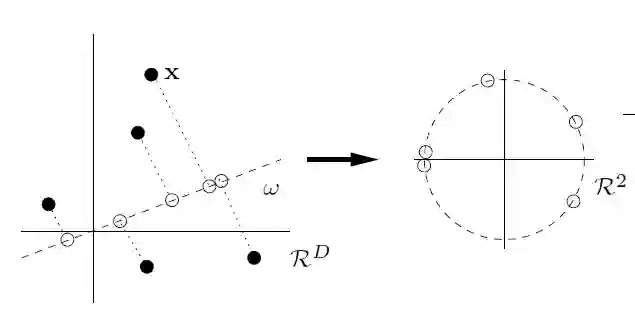
第二个框架为
白盒模型
,也就是在知道模型具体结构的情况下,如何在使用随机傅里叶特征(RFF)学习范式训练的模型中插入不可检测的后门。
![]()
在这种结构中,即使是强大的白盒区分器,模型中的后门仍然是不可检测的:即给定网络和训练数据的完整描述,任何有效的区分器都无法猜测模型是「干净的」还是有后门。
后门算法在给定的训练数据上执行的确实是RFF算法,只对其
随机硬币
(random coin)进行篡改。
为了让结论更泛化,研究人员还基于稀疏PCA随机生成ReLU网络,提供一个类似白盒的实验条件,结果仍然无法检测到后门。
文中构建的不可检测的后门也是在讨论「对抗样本」的鲁棒性。
通过为对抗鲁棒性学习算法构建不可检测的后门,我们可以创建一个让鲁棒分类器无法区分的后门版分类器,但其中每个输入都有一个对抗性样例。
后门的不可检测性,注定是对抗鲁棒性无法绕过的一个理论障碍。


 论文链接:https://arxiv.org/abs/2204.06974
论文链接:https://arxiv.org/abs/2204.06974





登录查看更多
相关内容
【AAAI 2022】机器学习模型的解释方法效果如何?MIT、微软学者为你解读,Do Feature Attribution Methods Correctly Attribute Features?
专知会员服务
31+阅读 · 2022年3月12日
Arxiv
0+阅读 · 2022年7月28日



相关VIP内容
【AAAI 2022】机器学习模型的解释方法效果如何?MIT、微软学者为你解读,Do Feature Attribution Methods Correctly Attribute Features?
专知会员服务
31+阅读 · 2022年3月12日
相关资讯