SegLink++:基于实例感知与组件组合的任意形状密集场景文本检测方法
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文授权转载自:CSIG文档图像分析与识别专委会


近年来场景文字检测工作主要分为两大类:自上而下的方法和自下而上的方法。自上而下的方法主要借鉴的是通用物体检测的思路,并且根据文字的特点设计相应的检测模型。这类方法通常难以处理不规则文本的检测问题。自下而上的方法,通常先学习文本行的基本组成单元,然后进行单元之间的组合得到文本行检测框。由于其灵活的表征方式,对不规则形状的文本检测有着天然的优势。自下而上的方法按照组成单元的不同又分为两类:组成单元为像素的基于分割的方法,以及组成单元为文字块的基于单元组合的方法。但是,自下而上的方法通常很难区分密集文本。密集文本检测问题是文本检测中一个广泛存在的难点问题。
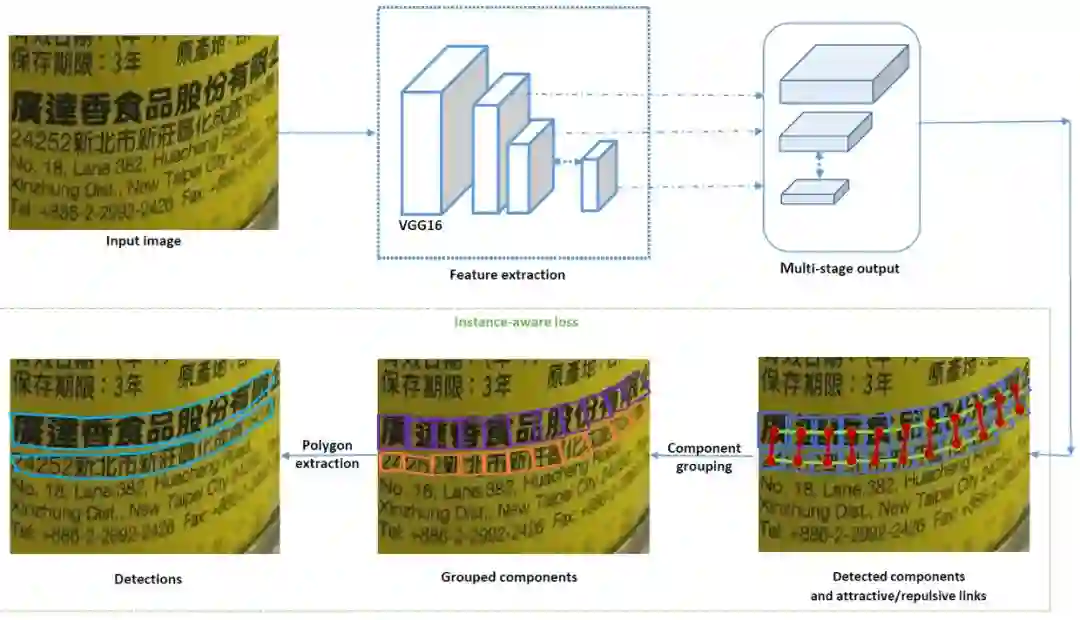
现有的自下而上的文字检测方法存在两个问题:一是难以区分密集文本,二是自下而上的方法通常需要一定的后处理进行单元组合,而这个后处理过程一般不能和网络一起进行端到端的训练。为了解决这些问题,该论文首先提出了一种文本块单元之间的吸引关系和排斥关系的表征,然后设计了一种最小生成树算法进行单元组合得到最终的文本检测框。另外,该论文还设计了Instance-aware Loss损失函数,把文本行实例的信息引入到文本块单元的训练过程,实现了后处理过程和网络端到端的训练。
具体的方法细节如图2所示。对于一张待检测的图片,先用VGG16网络进行特征提取,然后在不同层得到网络输出,其中有文字块单元的分类得分和文字块单元检测框的回归值,包括中心偏移量,宽和高以及旋转角度。另外,网络在不同层还会学习相邻文字块单元之间的吸引和排斥的强弱程度。对应到图2中,蓝色框表示文字块单元,绿色线段表示文字块单元之间的吸引关系,红色线段表示文字块单元之间的排斥关系,为了表示的方便,只画了其中两行文字中的文字块单元以及单元关系。
在后处理阶段,首先利用阈值得到有效的文字块单元。这些单元以及之间的连接关系可以构成一个图的表征G=(V,E)。其中的节点V代表多尺度的图像金字塔中的文字块单元,边E代表在同一层以及跨层的文字块单元之间的连接关系。其中每个边对应这两个吸引和排斥权重值: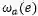

然后设计了一种最小生成树算法进行文字块单元组合,算法伪代码如图3所示。具体的算法流程是,按照吸引关系和排斥关系的强弱值从大到小考察每个关系。如果是吸引关系,则其连接的两个文字单元属于同一个文字单元组;如果是排斥关系,则其连接的两个文字单元之间有一个排斥的约束。遍历所有有效的文字块单元关系,可以得到组合好的文字块单元组,对应图2中,不同的文字块单元组用不同的颜色表示。最后,利用每组文字块单元,可以提取出对应的文字区域的外接检测框。

本文的损失函数分为两部分,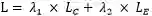
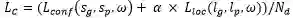
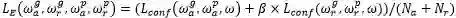
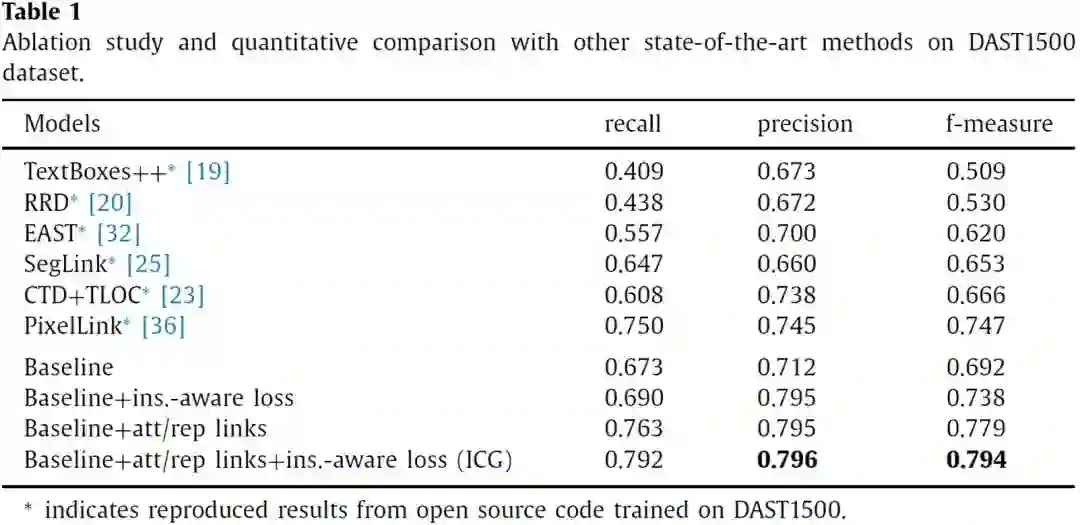


从Table 1来看,文中的方法在商品密集行数据集DAST1500上取得了优异的性能,大幅领先同时期的其他方法。从方法自身的对比来看,在Baseline基础上引入文字块单元间吸引和排斥的关系表征以及Instance-aware Loss都能有效提升密集文本检测效果。
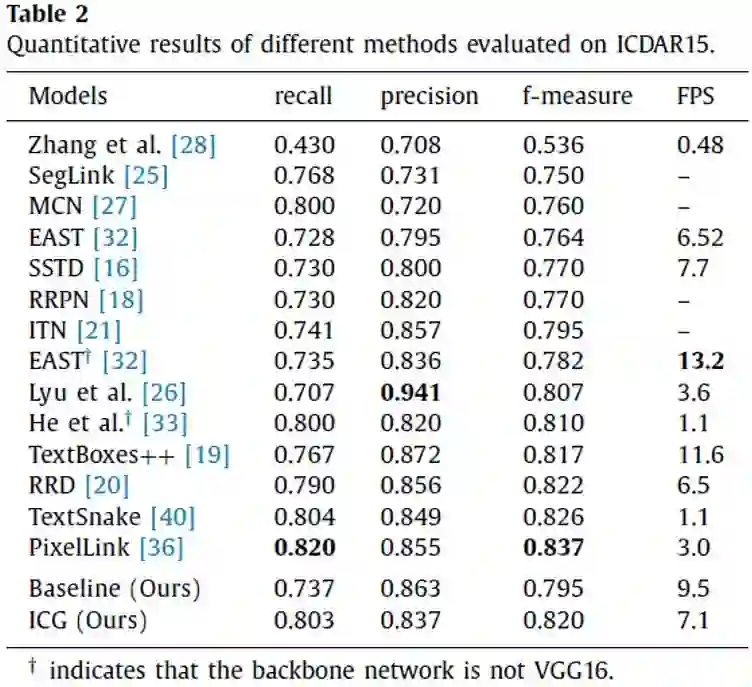
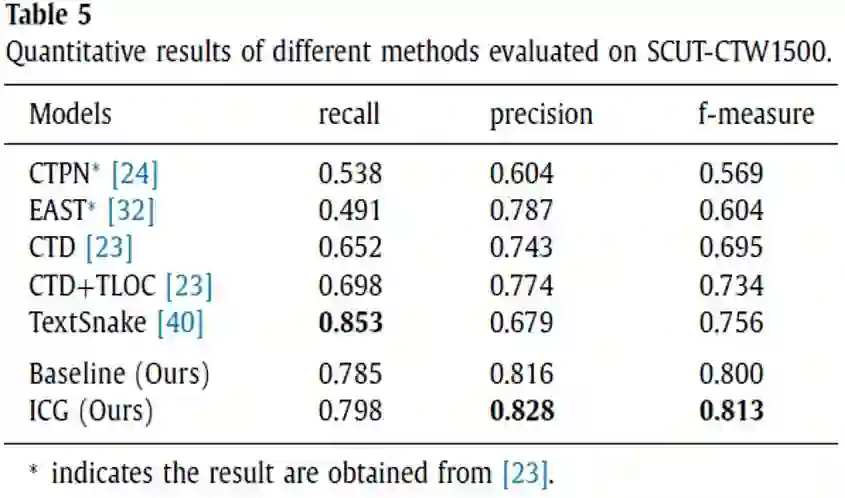
对于Table 2,文中的方法在ICDAR15多方向文本检测数据集上取得较好的结果,而且检测效率也不错。另外对于Table 5,在CTW1500曲形文本检测数据集上,本文的方法也取得很好的结果,优于同时期的其他方法。
图4展示了一些可视化的结果图。可以看到,该方法能处理任意形状的文本,在商品密集文本上也能取得很好的检测效果。
本文提出了一种Instance-aware Component Grouping(ICG)的自下而上的文字检测方法,实验证明该方法在检测不规则密集文本上的有效性和优越性。ICG中文字块单元之间吸引和排斥关系的表征,以及对文字行实例敏感的Instance-aware Loss,都能够显著改善自下而上的文字检测方法的检测效果。
论文链接:https://doi.org/10.1016/j.patcog.2019.06.020
下载链接:http://www.vlrlab.net/papers/xu/icg.pdf
DAST1500数据集链接:https://tianchi.aliyun.com/dataset/dataDetail?dataId=12084
原文作者:Jun Tang, Zhibo Yang, Yongpan Wang, Qi Zheng, Yongchao Xu, Xiang Bai
审校:殷 飞 发布:金连文
CVer-场景文本检测交流群
扫码添加CVer助手,可申请加入CVer-场景文本检测群。一定要备注:目标检测+地点+学校/公司+昵称。同时也开源申请其他CV细分方向群。细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(场景文本检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!
